
By Abigail Shelton
What and Why?
Like many academic institutions, the University of Notre Dame’s campus libraries and art museum have been digitizing collections for over a decade. Hesburgh Libraries and the Snite Museum of Art have shared these surrogates with researchers and faculty via email, focused digital exhibits, and collection-specific websites. However, this disjointed digital presence has reduced the utility and accessibility of these digital objects for scholars and students who are interested in searching digital collections and librarians or museum staff who are called upon to provide on-demand digital surrogates on behalf of users.
Enter the University’s 2017 grant from The Andrew W. Mellon Foundation.
This three-year grant project aims to bring those disparate digital collections into one access platform by creating multiple pipelines to a unified search index and user interface. The University is taking a cloud-first approach and the resulting application will be developed using Amazon’s cloud computing services.
We don’t promise to solve all of the challenges posed by legacy metadata, varying image formats, copyright policies, and proprietary or varied data stores. But we do plan to build intuitive, visually engaging user interfaces and a middle-manager data pipeline to begin tackling these discovery and access issues within our own institutional ecosystem.
Our goal of the Updates section is to keep you informed of our progress. We’ll be documenting our process from a technical perspective and a perspective on the project microsite, this update feed, our GitHub pages, and in an Open Science Framework portal. The ultimate hope is that our documentation and our code base will help not only Notre Dame, but also other institutions looking to provide greater online access to their own library and museum collections.
The First Year
In the first year or so of the grant period, we’ve focused on these foundational areas:
- Hiring grant-funded staff (including yours truly),
- Developing stakeholder relationships,
- Building an Alpha prototype,
- Forming subteams to empower subject and metadata experts to make decisions about content and information, and
- Implementing an IIIF (International Image Interoperability Framework) pipeline.
Developing Stakeholder Relationships
As the Outreach Specialist, I set out immediately to meet with as many library and museum faculty and staff as possible to find out what their requirements might be for this new platform. In addition, I’ve met with teaching faculty and students from a diverse range of campus departments to find out how they use digital resources and how they might like to use unique digitized items from the Hesburgh and Snite collections.
Unsurprisingly, the number one need for these users was the ability to quickly search the collections by keyword, followed by the need to narrow those results using a number of facets and filters. Secondary needs include the ability to conduct a known-item search, manipulate images (zoom, download, print, etc.), and create their own custom groupings.
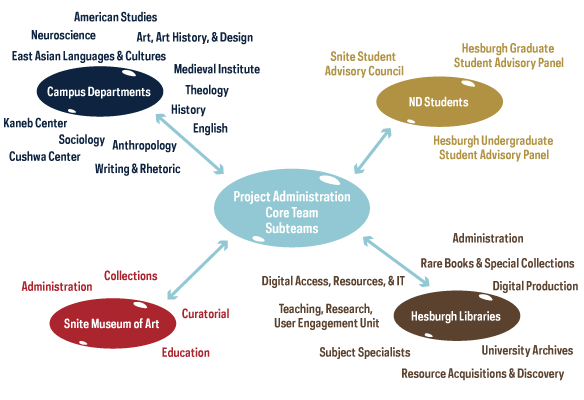
Our network of outreach contacts
Building an Alpha Prototype
We used these ideas and feedback to work on wireframes and, eventually, designed mockups to refine the features and look of the site. Our web developers have been implementing this vision in an alpha prototype website — internal users can now search and browse for a limited number of collection items to test early features and functionality. In the coming year, we’ll begin to test these designs with our users: teaching and library faculty, external researchers, undergraduate and graduate students, university staff, museum and library curators.
And as we’re refining the user experience, the developers will be building the pipelines that will connect our data and image stores to the search index and user interface. Our intent is not to force metadata or digital assets into one format or repository, but to connect an ecosystem of existing systems. This will require bridging open-source and vended solutions and finding a way to accommodate differing metadata schemas.
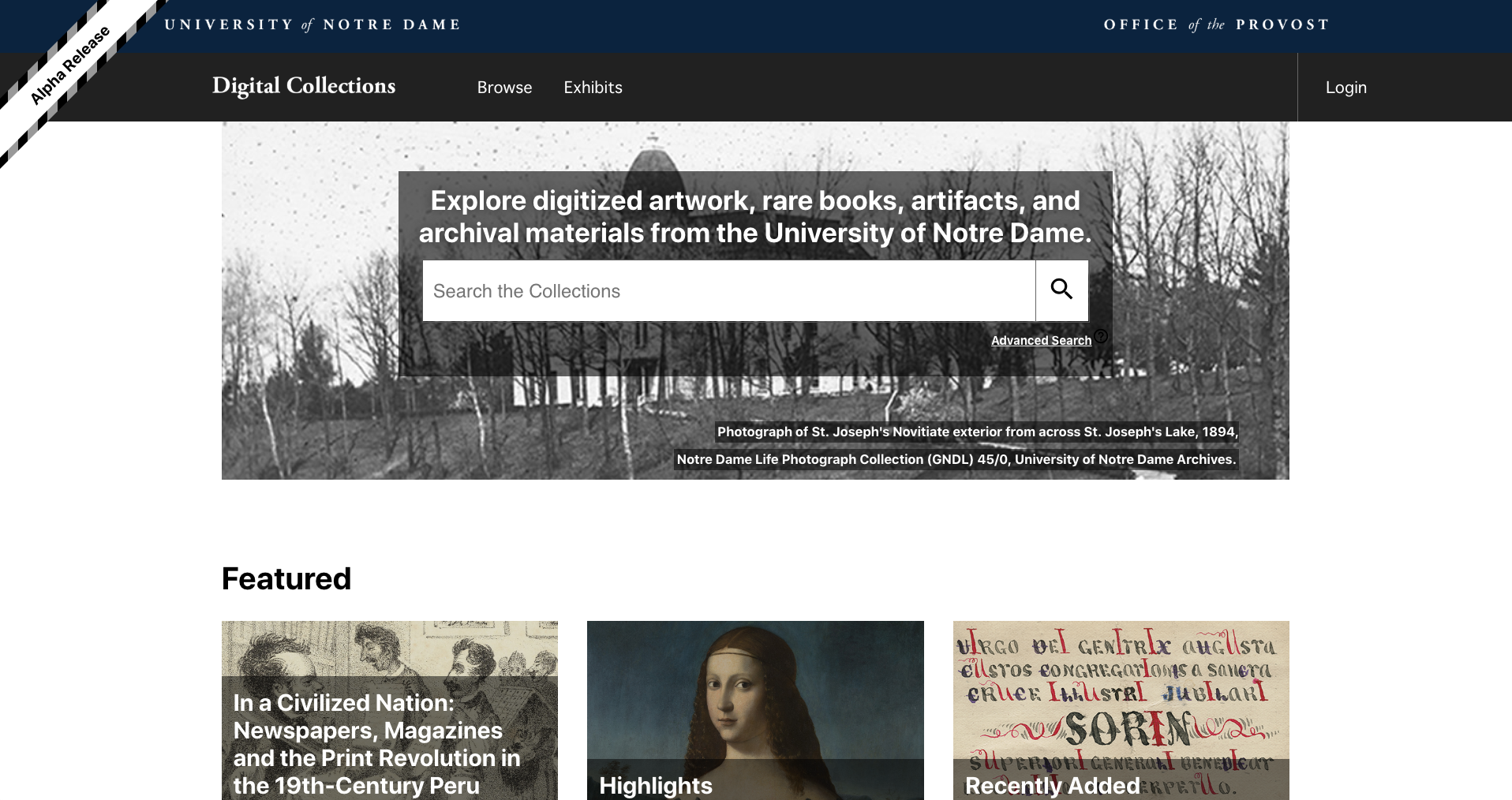
Marble Alpha prototype homepage
Forming Subteams
We have also formed three working groups: Content Team, Metadata Team, and Workflow Team. Future posts will highlight the work of these groups in more detail, but, at the highest level, these teams have been a key vehicle for empowering experts to make project decisions related to their fields. For instance, the Content Team is composed of library and museum curators, subject librarians, and digital project specialists. Their mandate is to select digitized collections to include in the unified platform for the Beta launch.
As subject matter experts, these team members know the University’s collections best, and we knew they needed to be involved in the decisions surrounding online content throughout the grant process. In addition, as scholars in their own right, they can provide feedback on the usability of the platform from a researcher perspective. Similarly, the Metadata Team and Workflow Team include library and museum staff with experience and knowledge related to those areas of the project.
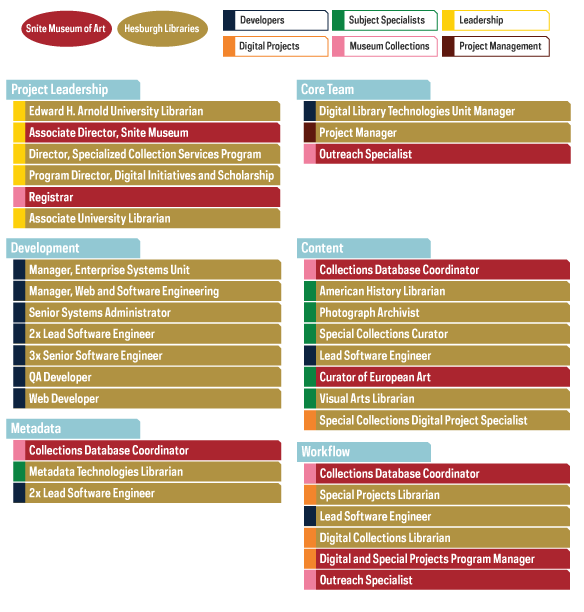
Project teams, color-coded by institutional partner and area of expertise
Implementing a IIIF Pipeline
Deeper below the surface, the library’s developers have been building and implementing a pipeline that accepts common image file formats and transforms them into IIIF (International Image Interoperability Framework) compliant images. The pipeline also serves these images up in a IIIF viewer, which allows the user to zoom deeply, rotate, scroll through alternate images, download, and print the image from the viewer.
One of the benefits of using IIIF compliant images is that they can be used alongside any IIIF compliant images of other institutions. For example, scholars will be able to compare medieval manuscripts from the University of Notre Dame with manuscripts from Oxford University, Stanford University, Bibliothèque Nationale de France, or the Vatican Library side-by-side in the same viewer.
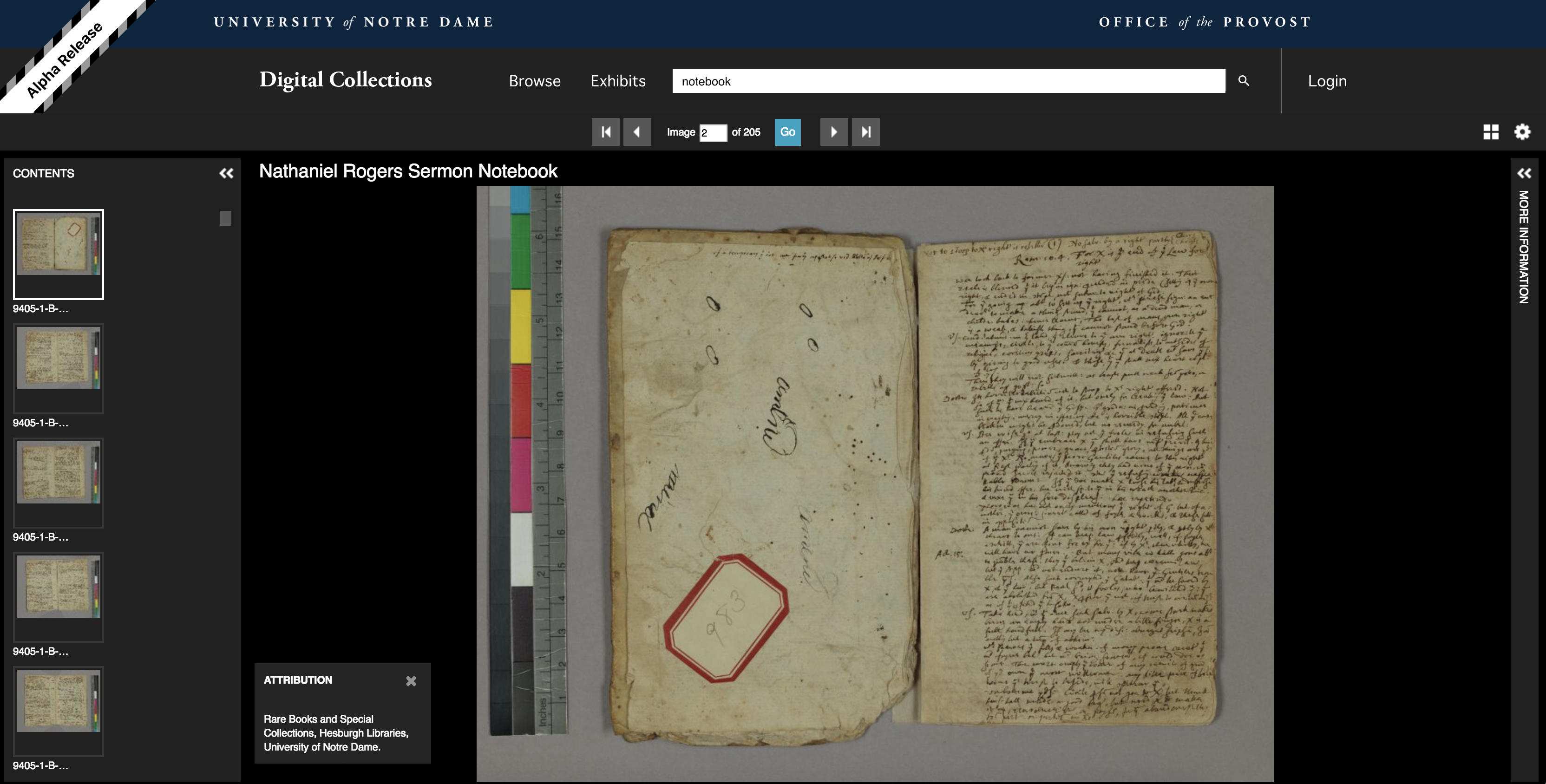
Image viewer containing Nathaniel Rogers Sermon Notebook (MSN/COL 9405, Rare Books and Special Collections, Hesburgh Libraries, University of Notre Dame )
Looking Ahead
In future posts, we’ll dive into feature development, our sub-teams and their work, the evolution of our technical architecture, special digital collections, metadata mapping, and any other facets of our work that we think would be useful to share.
If you’d like to follow along, bookmark this site or contact Abby Shelton (Outreach Specialist) at ashelto3@nd.edu.