

Difficulty: Intermediate
Prerequisites
- This project has no prerequisites.
networkx numpyBackground
Markov chains are a type of computational model used to understand many things, from language to physics to economics. All Markov chains are sequences of objects (like connected “links” of a physical chain). These objects can be numbers, words, states, locations, etc.
In a Markov chain, the process of choosing the next “link” in the chain depends on
✓ the characteristics of the current “link”
and
✓ some element of randomness or probability
but does not depend on
✗ the history of previous objects.
For example, imagine an ant has gotten very lost and is now crawling across your computer screen. You can’t predict exactly where the ant will be in ten seconds (randomness) but its position and the direction it is facing right now (current “link”) does give you some idea. Knowing where it was ten seconds ago (history) doesn’t really give you much additional useful information. This is a good example of Markov-chain-like behavior.
Markov Chain Sentence Generator
The King of Programmia does not have a lot of people to talk to – most people in the castle end conversation rather quickly because they are afraid of offending the King and being thrown in the dungeons. So, he has put out a substantial reward for anyone who can build him a robotic friend to talk to.
You have recently learned about Markov chains by reading the Background section of this article and are itching to try your hand at them. You get to work writing a program to build a sentence. True to Markov chain form, each successive word in your sentence is determined semi-randomly based on what words commonly follow the previous word. For example, if the previous word in your sentence was “go”, then your program might usually choose “to”, “away”, or “crazy” to be the next word, since these often follow “go” in a sentence.
It turns out that this system is not nearly complex enough to create a coherent English sentence, much less hold a conversation and earn you the King’s reward. However, it still has some interesting characteristics we can explore.
What to Do
- Download and extract the files from here to a single folder.
long_text.txt is a large text file with the text of some famous authors in it. This is what the program uses as its "baseline" for how words are commonly arranged. The more text you put in this file, the better your results will be. Visit this site if you want to find more text files of well-known literature.- Run
markov_sentences.py. Depending on the size of yourlong_text.txt, it may take a while to process. - Type in a word and watch the program create a “sentence” from that word.
- The result, of course, nonsense. Do this many more times with different words.
- Type
quitto exit the program. - Now, look in the folder where the python programs are and you should now see a file called
output.txt. This contains all of the sentences you have generated so far. - Run the other Python file,
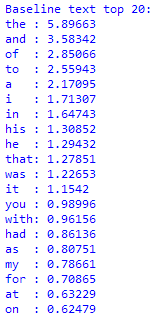
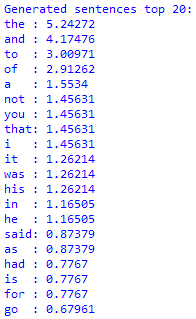
markov_analysis.py. You should get output something like this, showing the frequency percentages of the most common 20 words in the baseline (long_text.txt) and generated (output.txt) text: - If you are working in IDLE, you can get the percentage value for any word after you have run
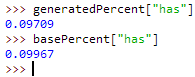
markov_analysis.pylike so: - Compare the word frequency percentages of the baseline and generated text as you add to
output.txtor change the size baseline text (long_text.txt). Note that you can deleteoutput.txtto start over as necessary.



Looking Back
Consider the following questions:
- How does decreasing or increasing the size of the baseline text change the frequency percentages of words?
- How closely do your output text frequencies match your baseline text frequencies? Why is this? What would cause them to match more or less closely?
- How do your output text frequency percentages compare to normal English text? Feel free to use online resources to find general English word frequencies. You may need to do a bit of calculation to convert online frequencies to percentages.
- Is there anything you notice about the words in your output text that is significantly different than a normal sentence?
- Why does this produce only nonsense sentences? Theoretically, how could you improve this program to more closely resemble real English sentences?