Apparently, when it comes to the idea of love during the Early English period, everything is black & white.
 Have harvested the totality of the EEBO-TCP (Early English Books Online – Text Creation Partnership) corpus. Using an extraordinarily simple (but very effective) locally developed indexing system, I extracted all the EEBO-TCP identifiers whose content was cataloged with the word love. I then fed these identifiers to a suite of software which: 1) caches the EEBO-TCP TEI files locally, 2) indexes them, 3) creates a browsable catalog of them, 4) supports a simle full text search engine against them, and 5) reports on the whole business (below). Through this process I have employed three sets of “themes” akin to the opposite of stop (function) words. Instead of specifically eliminating these words from the analysis, I specifically do analysis based on these words. One theme is “big” names. Another theme is “great” ideas. The third them is colors: white, black, red, yellow, blue, etc. Based on the ratio of each item’s number of words compared the number of times specific color words appear, I can generate a word cloud of colors (or colours) words, and you can “see” that in terms of love, everything is black & white. Moreover, the “most colorful” item is entitled The whole work of love, or, A new poem, on a young lady, who is violently in love with a gentleman of Lincolns-Inn by a student in the said art. — a charming, one-page document whose first two lines are:
Have harvested the totality of the EEBO-TCP (Early English Books Online – Text Creation Partnership) corpus. Using an extraordinarily simple (but very effective) locally developed indexing system, I extracted all the EEBO-TCP identifiers whose content was cataloged with the word love. I then fed these identifiers to a suite of software which: 1) caches the EEBO-TCP TEI files locally, 2) indexes them, 3) creates a browsable catalog of them, 4) supports a simle full text search engine against them, and 5) reports on the whole business (below). Through this process I have employed three sets of “themes” akin to the opposite of stop (function) words. Instead of specifically eliminating these words from the analysis, I specifically do analysis based on these words. One theme is “big” names. Another theme is “great” ideas. The third them is colors: white, black, red, yellow, blue, etc. Based on the ratio of each item’s number of words compared the number of times specific color words appear, I can generate a word cloud of colors (or colours) words, and you can “see” that in terms of love, everything is black & white. Moreover, the “most colorful” item is entitled The whole work of love, or, A new poem, on a young lady, who is violently in love with a gentleman of Lincolns-Inn by a student in the said art. — a charming, one-page document whose first two lines are:
LOVE is a thing that’s not on Reaſon laid,
But upon Nature and her Dictates made.
The corpus of the EEBO-TCP is some of the cleanest data I’ve ever seen. The XML is not only well-formed, but conforms the TEI schema. The metadata is thorough, (almost) 100% complete, (usually) consistently applied. It comes with very effective stylesheets, and the content is made freely easily available in a number of places. It has been a real joy to work with!
General statistics
An analysis of the corpus’s metadata provides an overview of what and how many things it contains, when things were published, and the sizes of its items:
- Number of items – 156
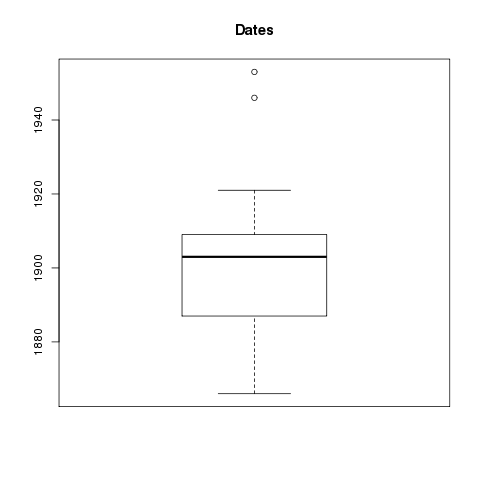
- Publication date range – 1493 to 9999 (histogram : boxplot)
- Sizes in pages – 1 to 606 (histogram : boxplot)
- Total number of pages – 12332
- Average number of pages per item – 79
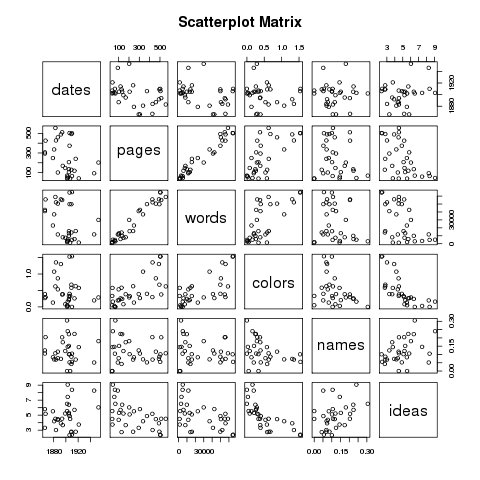
Possible correlations between numeric characteristics of records in the catalog can be illustrated through a matrix of scatter plots. As you would expect, there is almost always a correlation between pages and number of words. Are others exist? For more detail, browse the catalog.
Notes on word usage
By counting and tabulating the words in each item of the corpus, it is possible to measure additional characteristics:
Perusing the list of all words in the corpus (and their frequencies) as well as all unique words can prove to be quite insightful. Are there one or more words in these lists connoting an idea of interest to you, and if so, then to what degree do these words occur in the corpus?
To begin to see how words of your choosing occur in specific items, search the collection.
Through the creation of locally defined “dictionaries” or “lexicons”, it is possible to count and tabulate how specific sets of words are used across a corpus. This particular corpus employs three such dictionaries — sets of: 1) “big” names, 2) “great” ideas, and 3) colors. Their frequencies are listed below:
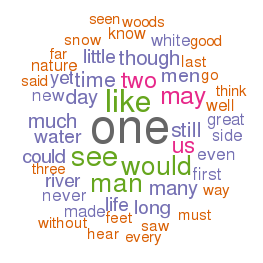
The distribution of words (histograms and boxplots) and the frequency of words (wordclouds), and how these frequencies “cluster” together can be illustrated:
Items of interest
Based on the information above, the following items (and their associated links) are of possible interest:
- Shortest item (1 p.) – Now she that I louyd trewly beryth a full fayre face hath chosen her … (TEI : HTML : plain text)
- Longest item (606 p.) – Psyche, or, Loves mysterie in XX canto’s, displaying the intercourse betwixt Christ and the soule / by Joseph Beaumont … (TEI : HTML : plain text)
- Oldest item (1493) – This tretyse is of loue and spekyth of iiij of the most specyall louys that ben in the worlde and shewyth veryly and perfitely bi gret resons and causis, how the meruelous [and] bounteuous loue that our lord Ihesu cryste had to mannys soule excedyth to ferre alle other loues … Whiche tretyse was translatid out of frenshe into englyshe, the yere of our lord M cccc lxxxxiij, by a persone that is vnperfight insuche werke … (TEI : HTML : plain text)
- Most recent (9999) – Ovid’s Art of love; in three books: : together with his Remedy of love: / translated into English verse, by several eminent hands: ; to which are added, The court of love, The history of love, and Armstrong’s Oeconomy of love. (TEI : HTML : plain text)
- Most thoughtful item – A sermon directing what we are to do, after strict enquiry whether or no we truly love God preached April 29, 1688. (TEI : HTML : plain text)
- Least thoughtful item – Amoris effigies, sive, Quid sit amor? efflagitanti responsum (TEI : HTML : plain text)
- Biggest name dropper – Wit for money, or, Poet Stutter a dialogue between Smith, Johnson, and Poet Stutter : containing reflections on some late plays and particularly, on Love for money, or, The boarding school. (TEI : HTML : plain text)
- Fewest quotations – Mount Ebal, or A heavenly treatise of divine love Shewing the equity and necessity of his being accursed that loves not the Lord Iesus Christ. Together with the motives meanes markes of our love towards him. By that late faithfull and worthy divine, John Preston, Doctor in Divinitie, chaplaine in ordinary to his Majestie, master of Emmanuel Colledge in Cambridge, and sometimes preacher of Lincolnes Inne. (TEI : HTML : plain text)
- Most colorful – The whole work of love, or, A new poem, on a young lady, who is violently in love with a gentleman of Lincolns-Inn by a student in the said art. (TEI : HTML : plain text)
- Ugliest – Eubulus, or A dialogue, where-in a rugged Romish rhyme, (inscrybed, Catholicke questions, to the Protestaut [sic]) is confuted, and the questions there-of answered. By P.A. (TEI : HTML : plain text)






 emerson
emerson thoreau
thoreau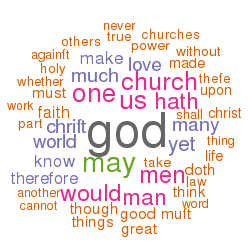 EEBO is an acronym for Early English Books Online. It is intended to be a complete collection of English literature between 1475 through to 1700. TCP is an acronym for Text Creation Partnership, a consortium of libraries dedicated to making EEBO freely available in the form of XML called TEI (Text Encoding Initiative). [4, 5]
EEBO is an acronym for Early English Books Online. It is intended to be a complete collection of English literature between 1475 through to 1700. TCP is an acronym for Text Creation Partnership, a consortium of libraries dedicated to making EEBO freely available in the form of XML called TEI (Text Encoding Initiative). [4, 5]
 I used the repository on Box to get my content, and I mirrored it locally. [1, 2] I then looped through the content using XPath to extract rudimentary metadata, thus creating a “catalog” (index). Along the way I calculated the number of words in each document and saved that as a field of each “record”. Being a tab-delimited file, it is trivial to import the catalog into my favorite spreadsheet, database, editor, or statistics program. This allowed me to browse the collection. I then used grep to search my catalog, and save the results to a file. I searched for Richard Baxter. [6, 7, 8]. I then used an R script to graph the numeric data of my search results. Currently, there are only two types: 1) dates, and 2) number of words. [9, 10, 11, 12] From these graphs I can tell that Baxter wrote a lot of relatively short things, and I can easily see when he published many of his works. (He published a lot around 1680 but little in 1665.) I then transformed the search results into a browsable HTML table. The table has hidden features. (Can you say, “Usability?”) For example, you can click on table headers to sort. This is cool because I want sort things by number of words. (Number of pages doesn’t really tell me anything about length.) There is also a hidden link to the left of each record. Upon clicking on the blank space you can see subjects, publisher, language, and a link to the raw XML.
I used the repository on Box to get my content, and I mirrored it locally. [1, 2] I then looped through the content using XPath to extract rudimentary metadata, thus creating a “catalog” (index). Along the way I calculated the number of words in each document and saved that as a field of each “record”. Being a tab-delimited file, it is trivial to import the catalog into my favorite spreadsheet, database, editor, or statistics program. This allowed me to browse the collection. I then used grep to search my catalog, and save the results to a file. I searched for Richard Baxter. [6, 7, 8]. I then used an R script to graph the numeric data of my search results. Currently, there are only two types: 1) dates, and 2) number of words. [9, 10, 11, 12] From these graphs I can tell that Baxter wrote a lot of relatively short things, and I can easily see when he published many of his works. (He published a lot around 1680 but little in 1665.) I then transformed the search results into a browsable HTML table. The table has hidden features. (Can you say, “Usability?”) For example, you can click on table headers to sort. This is cool because I want sort things by number of words. (Number of pages doesn’t really tell me anything about length.) There is also a hidden link to the left of each record. Upon clicking on the blank space you can see subjects, publisher, language, and a link to the raw XML.

 I have put my (fledgling) HathiTrust Workset Browser on GitHub. Try:
I have put my (fledgling) HathiTrust Workset Browser on GitHub. Try:{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}