Deep neural networks are known to be a data-intensive algorithm. Thousands of examples are usually needed to be able to make a good classification. Few-shot learning is the opposite of that such that it aims to learn using only a few examples of each class.
One/few-shot learning refers to rapid learning from one or a few examples. Experiments on few shot learning are usually shown on N-way K-shot learning, where N is the number of classes is and K is the number of examples per 5-wayclass.
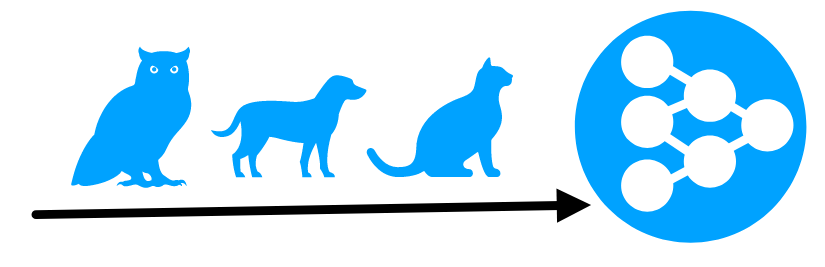
An example of a 5-way 1-shot classification. 5-way stands for 5 classes which are birds, dogs, cats, dolphons and rabbits). We also have one example (1-shot) for each class.
A 3-way 3-shot learning example. We have 3 classes (3-way) in the support set which are birds, dogs and cats with 3 examples (3-shot) each.
The dataset is split such that the classes in the training set are disjoint from the classes in the test set. For example, the training set can include cats, dogs and birds while the test set contains rabbits and dolphins. The number of classes is large while the number of images per class is typically small. Given a set of support images with one/few image(s) per class and a query image, the goal of one/few shot learning is to be able to identify which support image the query image is most similar to.
A dataset commonly used for one/few-shot learning is the omniglot dataset. The omniglot dataset has a large number of classes and only a few examples for each class (i.e., as opposed to the MNIST database of handwritten digits which has few classes and a large number of examples for each class.) Omniglot contains 1623 characters from 50 different alphabets; each character is handwritten by 20 different people. 1200 characters are used for training while the remaining characters are used for testing.
To be able to achieve artificial general intelligence, or human-like intelligence, machines should be able to remember previously known tasks simultaneously. In a given scenario, certains tasks may not appear frequently or recently as others. Neural networks in particular are known to catastrophically forget, information when they are not frequently or recently seen. This happens because neural network must frequently adapt to weights for newer task.
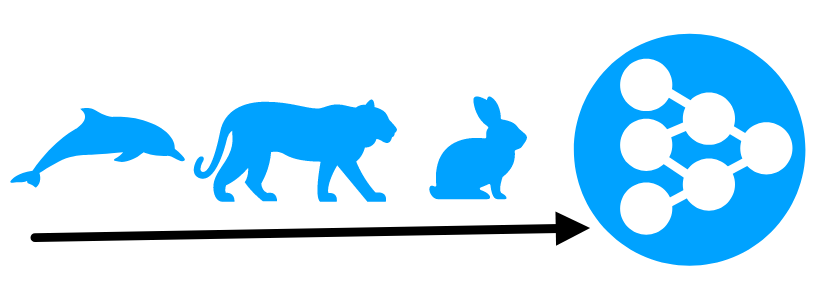
For example, we have a neural network which is trained to recognize birds, cats and dogs (Set 1). We then train it with other classes such as dolphins, rabbits and lions (Set 2). After some time, the neural network can start getting poor results in recognizing any class in Set 1 because the weights are biased to recognize the classes in Set 2. This is known as catastrophic forgetting.