

Post by Christine Rollinson, Post-doc at Boston University working with Michael Dietze.
After a bit of a break and some time back out in the woods, for the PalEON blog and myself, it’s time to wrap up our series of posts on the ecosystem modeling side of PalEON. In the first post, we talked about why a paleoecological research group is using ecosystem models. The second post took us behind the curtain and down the rabbit hole to describe a bit of the how of the modeling process. Now it’s time to take a step back again and talk about what we are learning from the PalEON Model Inter-comparison Project (MIP).
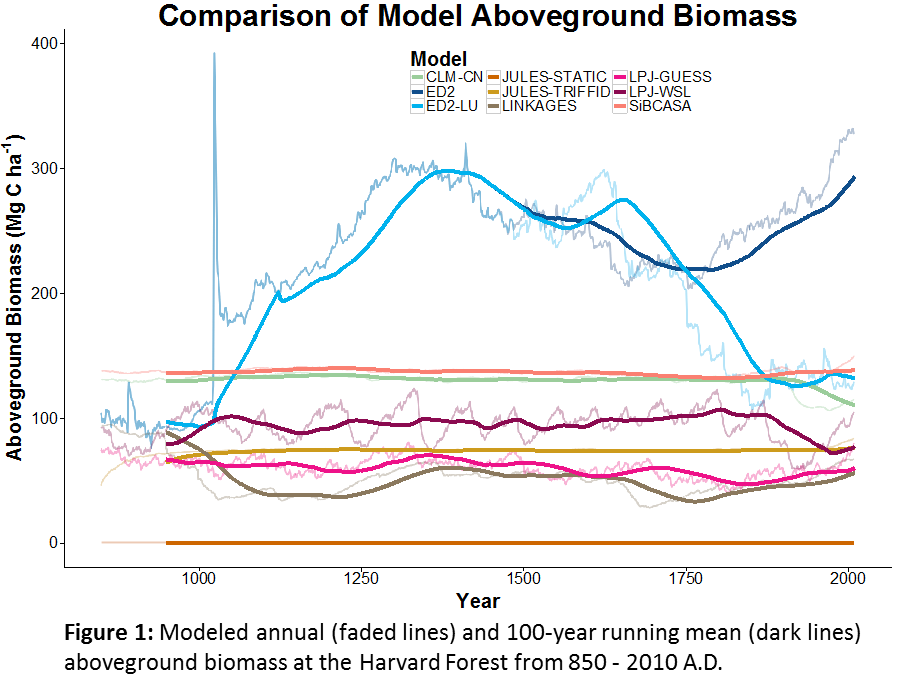
Above is a figure showing aboveground biomass at Harvard Forest from the different PalEON MIP models. The first question most people want know is: Which model is right (or at least closest to reality)? Well, the fact of the matter is, we don’t really know. We know that modern biomass at the Harvard Forest is around 100 Mg C per hectare. Most models are in the right ballpark, but each has a very different path it took to get there. When we go back in time beyond the past few decades the data available to validate most of these models is extremely sparse. PalEON has gathered pollen samples at Harvard forest and other MIP sites as well as pre-settlement vegetation records for most of the northeast. The settlement vegetation records have provided a biomass benchmark for some of our western MIP sites, but aside from that, all other pre-1700 information currently available for comparison with models is based on forest composition.
So how do we evaluate these different models when we don’t actually know what these forests were like 1,000 years ago? In the absence of empirical benchmarks, we are left comparing the models to each other. A typical approach would then be to look at each model and try to explain why it has a particular pattern or is different from another model. For example, why does ED have that giant spike in the 11th century? (We’re still trying to figure that one out; see previous post on debugging.)
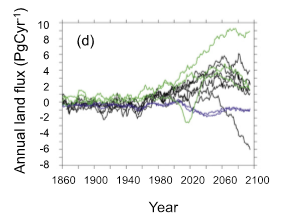
Figure 2: The PalEON MIP isn’t the only model comparison project to see models predicting vastly different conditions in time periods that have no data available for comparison. This figure shows similar problems in CMIP51.
The purpose of a multi-model comparison doesn’t necessarily need to be identifying a single “best” or most accurate model. As an ecologist with PalEON, my goal is to avoid dissecting individual models and instead focus on the big picture and answer questions where output from a single model would be insufficient.
I like to view the PalEON MIP in the same way I would view an empirical-based study that is trying to find cohesive ecological patterns across many field sites or ecosystems. An incredible about of detailed information can be gleaned from a study based in a single site or region, but these types of studies have their limitations. Single-site studies have extraordinarily detailed information about plant physiology, ecosystem interactions, and direct effects of warming through experimentation. I think working with a single ecosystem model is very similar to performing a single-site field study. With one model, you can run simulations to identify potential cause-and-effect relationships, but at the end of the day, the observed response may only be an artifact of that particular model’s structure and not representative of what happens in the real world.
Working with a multi-model comparison is like working with a continental- or global-scale data set. There’s always a temptation to dig into the story of indvidual sites (or in this case models). Each site or model has it’s own interesting quirks, stories, and contributions to ecology that a researcher could easily use to build a career (as many have). However, if we think about ideas that have formed the fundamentals of ecology, ideas such as natural selection, carrying capacity, or biogeography, these ideas are those that apply across taxa and ecosystems. To draw the parallel with modeling, if we want to move away from a piecemeal approach to ecosystem modeling and find synthetic trends, test ecological theories, and identify areas of greatest uncertainty, we need to draw comparisons across many models. The PalEON MIP, with detailed output from more than 10 models on ecosystem structure and function from millenial-length runs at six sites, is the perfect model data set to look at these sort of questions.
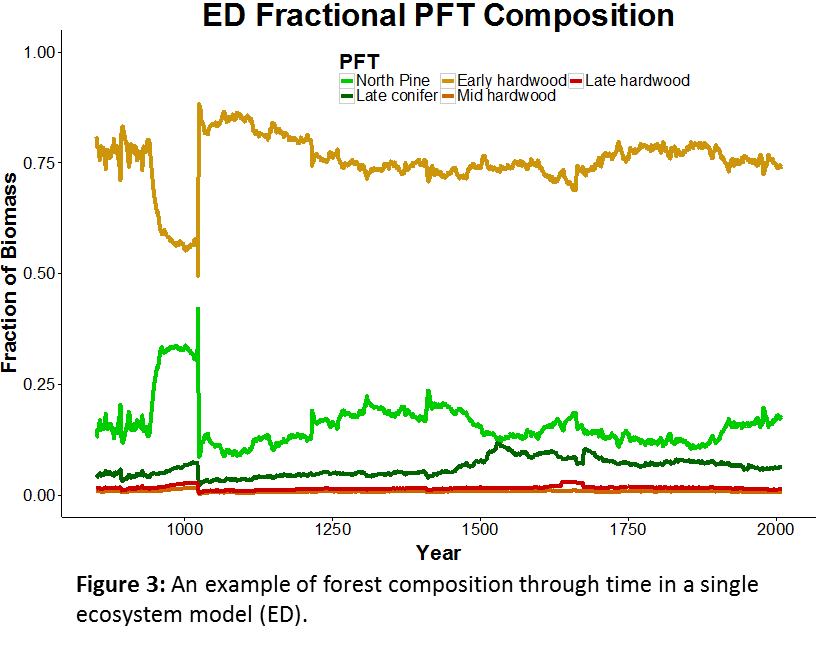
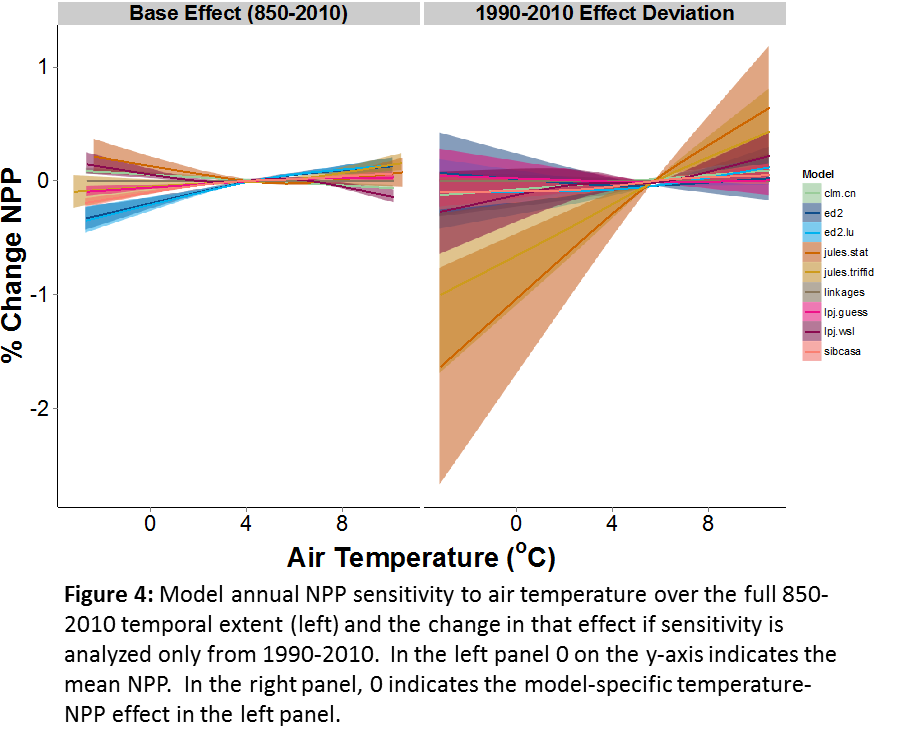
Current PalEON MIP analyses are investigating a wide range of ecological patterns and processes such as the role of temporal scale in understanding causes of ecosystem variation, transitions in vegetation composition, and ecological resilience after extreme events. With the PalEON MIP, we are first identifying patterns that we know exist in nature such as concurrent shifts in climate and species composition or a given sensitivity of NPP to temperature. We can then find out if and when these patterns occur in the model and only then, look at similarities or differences among the models that might explain patterns of model behavior across models. Additionally, my personal ecological research interests have led me to use these models to test conceptual ecological theories regarding the role of temporal scale in paleoecological data that have thus far been difficult to assess with empirical data (Fig. 4).
If there’s one point I want you to take away from this series on ecological modeling, it is this: ecosystem models are tools that let us test ecological theories in ways not possible with empirical data. Models allow us to test our understanding of individual ecosystem processes as well as how those processes scale across space and time. Because ecosystem models are representations of how we think the world works, modelers aren’t just programmers; modelers are ecologists too!
I want to take this opportunity to thank all of the PalEON team and collaborators and particularly the PalEON MIP participants for contributing runs and helping get me up to speed on ecological modeling. Keep your eyes out at ESA next month for PalEON-related talks including this session where you can hear several PalEON-related talks including some actual MIP results!
- P. Friedlingstein et al., Uncertainties in CMIP5 climate projections due to carbon cycle feedbacks. J. Clim. 27, 511-526 (2014).