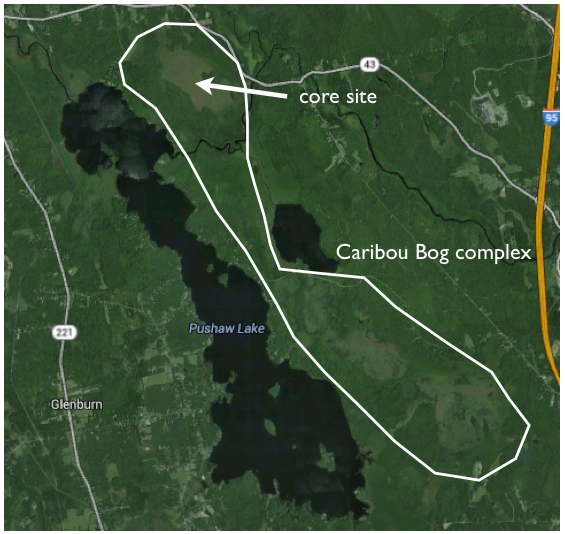
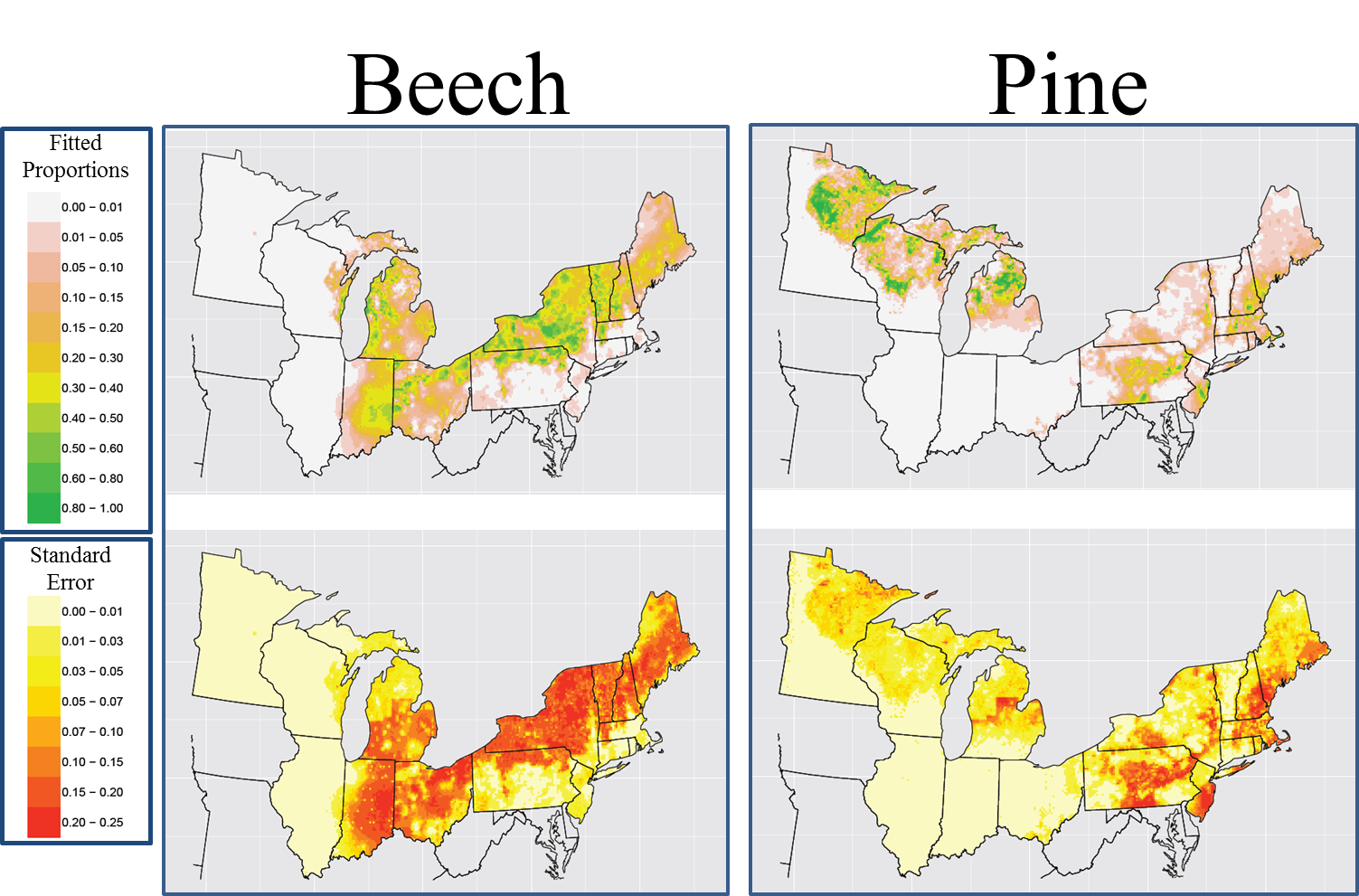
Post by Andria Dawson, Post-Doc at University of California-Berkeley
Pollen and seed dispersal are important reproductive processes in plants, and in part determines the abundance and extent of a species. With a recent push to understand how species will respond to global climate change, dispersal ecology has gained increasing interest. We really want to know if there is a dispersal limitation, or if species can migrate quickly enough to maintain survival in a changing environment. Addressing this question presents challenges, many of which arise from trying to understand and quantify dispersal in ecosystems that are changing in both space and time (Robledo-Arnuncio 2014).
In PalEON, one of our efforts involves estimating the past relative abundance of vegetation from fossil pollen records. To do this, we need to quantify the pollen-vegetation relationship, which includes modelling pollen dispersal processes.
For many trees, including those we study in the PalEON domain, pollination is exclusively (or at least predominantly) anemophilous (carried out by wind). In angiosperms, wind pollination is thought to have evolved as an alternative means of reproduction for use when animal pollinators are scarce (Cox 1991). It was previously understood that wind pollination was less efficient than insect pollination (Ackerman 2000), but Friedman and Barrett (2009) show that may not be the case. To estimate the efficiency of wind pollination, they compared pollen captured by stigmas to pollen produced, and found that the mean pollen capture was about 0.32%, which is similar to estimates of animal pollination efficiency. Although both dispersal vectors are comparable with respect to efficiency, these quantities indicate that both are still pretty inefficient – this is great news for paleoecologists! Some of the pollen that is not captured ends up in the sediment.
Now we know that we expect to find pollen in the sediment, but how do we begin to quantify how much pollen of any type we expect to find at a given location? The route a pollen grain takes to arrive at its final location is governed by atmopsheric flow dynamics (among other things). These dynamics are complicated by landscape heterogeneity and climate, and differ among and within individuals because not all pollen grains are created equal. However, we usually aren’t as interested in the route as we are in the final location – in particular, we want to know the dispersal location relative to the source location. The distributions of dispersal locations from a source defines a dispersal kernel which can be empirically estimated with dispersal location data. Often these kernels are modelled using parametric distributions, usually isotropic, and often stationary with respect both space and time. Are these approximations adequate? If so, at what scale? These are some of the questions we hope to address by using Bayesian hierarchical modelling to quantify the pollen vegetation relationship in the Upper Midwest.
References
1. Robledo-Arnuncio, JJ, et al. Movement Ecology, 2014.
2. Cox, PA. Philosophical Transactions of the Royal Society B: Biological Sciences, 1991.
3. Friedman, J, Barrett SCH. Annals of Botany, 2009.
4. Ackerman, JD. Plant Systematics and Evolution, 2000.