Good to have Goals
One architectural goal we had in mind as we designed our OnBase implementation in AWS was to break out the single, collapsed web and application tier into distinct web and application tiers.
Here’s a simplification of what the design of our on-premises implementation looked like:
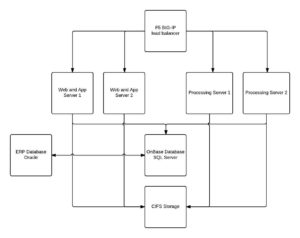
Due to licensing considerations, we wanted to retain two, right-sized web servers behind an Elastic Load Balancer (ELB). We then wanted to have that web tier interact with a load balanced application tier. Since licensing at the application tier is very favorable, we knew we could horizontally scale as necessary to meet our production workload.
To ELB, or not to ELB, that is the question
Our going-in assumption was that we would use a pair of ELBs. It was remarkably quick to configure. In under an hour, we had built out an ELB to front the web servers, and an ELB to front the application servers. It was so easy to set up. Too easy, as it turned out.
During functional testing, we observed very strange session collisions. We worked with our partners, looked at configuration settings, and did quite a bit of good, old-fashioned shovel work. The big sticking point turned out to be in how we have OnBase authentication implemented. Currently, we are using Windows Challenge/Response (NTLM to be specific, dating back to the days of NT LAN Manager) to authenticate users. The problem is, NTLM authentication does not work across an HTTP proxy because it needs a point-to-point connection between the user’s browser and server. See https://commscentral.net/tech/?post=52 for an explanation of NTLM via an ELB.
When an IIS server gets a request, it sends a 401 response code (auth required) and keeps the HTTP connection alive. An HTTP proxy closes the connection after getting a 401. So in order to proxy traffic successfully, the proxy needs to be configured to proxy TCP, not HTTP. NTLM authenticates the TCP connection.
Enter HAProxy
In order to get past this obstacle, we ended up standing up an EC2 instance with HAProxy on it, and configuring it to balance TCP and stick sessions to backends. Properly configured, we were cooking with gas.
A word on scheduling
For our production account, we make extensive use of reserved instances. On a monthly basis, 85% of our average workload is covered by a reservation. For OnBase, we use t2.large running Windows for our application servers.
Currently, a one-year reservation costs $782. If you were to run the same instance at the on demand rate of $0.134 per hour, the cost for a year would be $1174. For an instance which needs to be on 24×7, reservations are great. For a t2.large, we end up saving just over 33%.
Due to application load characteristics and the desire to span availability zones, we ended up with four application servers. However, from a workload perspective, we only need all four during business hours: 7 am to 7 pm. So, 52 weeks per year, 5 days per week, 12 hours per day, $0.134 per hour. That comes out to just over $418, which is a savings of over 64%. If you can schedule, by all means, do it!
Simplified final design
So, where did we end up? Consider the following simplified diagram:
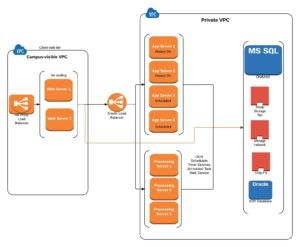
The web servers are in separate availability zones, as are the application servers. There are still single points of failure in the design, but we our confident in our ability to recover within a timeframe acceptable to our customers.
So, what did we learn?
We learned quite a bit here, including:
- NTLM is not our friend. Replacing it with SAML/CAS this summer will allow us to jettison the HAProxy instance and replace it with an ELB.
- Scheduling is important. Reserved Instances optimize your spend, but they don’t optimize your usage. You’re leaving a lot of money on the table if you’re not actively involved in scheduling your instances, which you can only do if you have a deep understanding of your system’s usage profile.
- Working in AWS is a lot of fun. If you can imagine it, it’s really easy to build, prototype, and shift as appropriate.
Coming soon, migrating the OnBase database.





![By Kbh3rd (Own work) [CC BY 4.0 (http://creativecommons.org/licenses/by/4.0)], via Wikimedia Commons](http://blogs.nd.edu/devops/files/2016/06/Weldon_Spring_Site_containment_stairway_1.jpg)