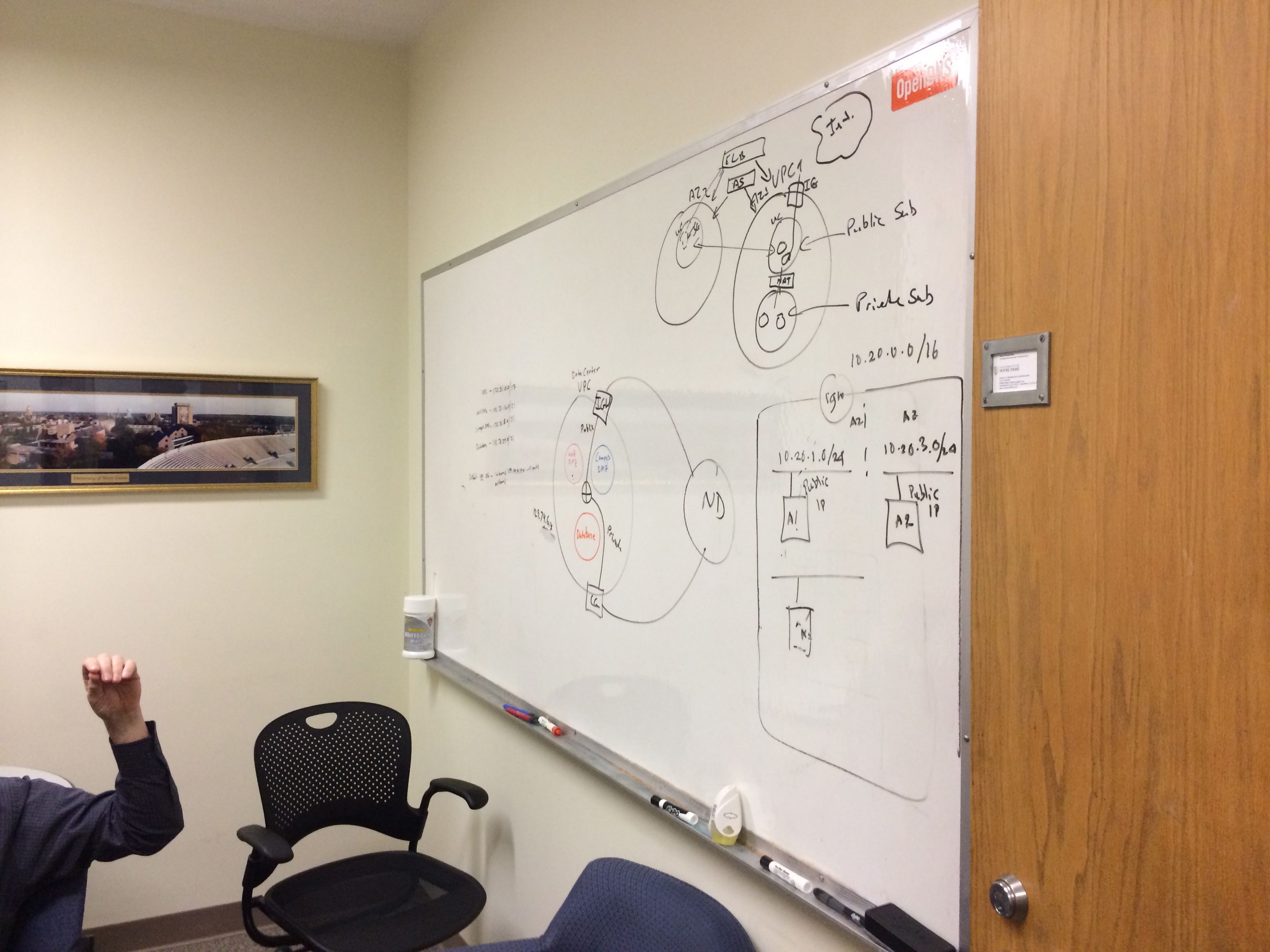
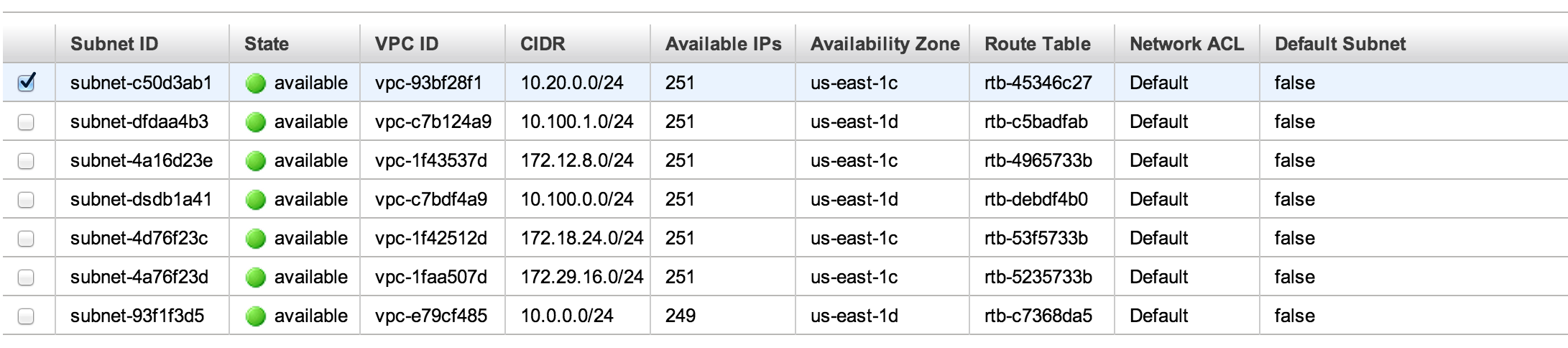
Today is an exciting time to be a part of higher education IT! We are participating in the biggest transformation in our field since the client/server computing model displaced mainframes – the adoption of public cloud computing. The innovation, flexibility, cost effectiveness and security that the public cloud brings to our institutions will permanently change the way that we work. This new technology model will render the construction of on-campus data centers obsolete and transform academic and administrative computing for decades to come.
Why is this transformation happening? We’ve reached a tipping point where network speeds allow the consolidation of computing resources in a manner where large providers can achieve massive economies of scale. For the vast majority of workloads, there’s really no difference if computing power is located down the hall or across the country. Computing infrastructure is now a commodity for us to leverage rather than an art for us to master. We have the opportunity to add more value higher up in the stack by becoming integrators and innovators instead of hardware maintainers.
We Need the Cloud’s Disruptive Innovation
The reality is that cloud providers can simply innovate faster than we can. Our core mission is education and research – not information technology. The core mission of cloud providers is providing rock solid infrastructure services that make IT easier. How can we possibly compete with this laser-like focus? Better question – why would we even want to try? Instead of building data centers that compete with cloud providers, we can leverage the innovations they bring to the table and ensure that our laser-like focus is in the right place – on our students and faculty.
As an example, consider the automatic scaling capabilities of cloud providers. At Notre Dame, we leveraged Amazon Web Services’ autoscaling capability totransform the way we host the University website. We now provision exactly the number of servers required to support our site at any given time and deprovision servers when they are no longer needed. Could we have built this autoscaling capability in our own data center? Sure. The technology has been around for years, but we hadn’t done it because we were focused on other things. AWS’ engineering staff solved that for us by building the capability into their product.
We Need the Cloud’s Unlimited Capacity and Flexibility
The massive scale of public cloud infrastructures makes them appear to have essentially unlimited capacity from our perspective. Other than some extremely limited high performance computing applications, it’s hard to imagine a workload coming out of our institutions that a major cloud provider couldn’t handle on a no-notice basis. We have the ability to quickly provision massive computing resources, use them for as long or short a duration as necessary, and then quickly deprovision them.
The beauty of doing this type of provisioning in the public cloud is that overprovisioning becomes a thing of the past. We no longer need to plan our capacity to handle an uncertain future demand – we can simply add resources on-demand as they are needed.
We Need the Cloud’s Cost Effectiveness
Cloud solutions are cost effective for two reasons. First, they allow us to leverage the massive scale of cloud providers. Gartner estimates that the public cloud market in 2013 reached $131 billion in spend. The combined on-campus data centers of all higher education institutions combined constitute a tiny fraction of that size. When companies like Amazon, Google and Microsoft build at macro-enterprise scale, they are able to generate a profit while still passing on significant cost savings to customers. The history of IaaS price cuts by AWS, Google and others bear this out.
The second major cost benefit of the public cloud stems from the public cloud’s “pay as you go” model. Computing no longer requires major capital investments – it’s now available at per-hour, per-GB and per-action rates. If you provision a massive amount of computing power to perform serious number crunching for a few hours, you pay for those hours and no more. Overprovisioning is now the responsibility of the IaaS provider and the costs are shared across all customers.
We Need the Cloud’s Security and Resiliency
Security matters. While some may cite security as a reason not to move to the cloud, security is actually a reason to make the move. Cloud providers invest significant time and money in building highly secure environments. They are able to bring security resources to bear that we can only dream about having on our campuses. The Central Intelligence Agency recently recognized this and made a $600M investment in cloud computing. If IaaS security is good enough for the CIA, it should be good enough for us. That’s not to say that moving to the cloud is the silver bullet for security – we’ll still need a solid understanding of information security to implement our services properly in a cloud environment.
The cloud also simplifies the creation of resilient, highly available services. Most providers operate multiple data centers in geographically diverse regions and offer toolkits that help build solutions that leverage that geographic diversity. The Obama for America campaign discovered this when they picked up and moved their entire operation from the AWS eastern region to a west coast region in hours as Superstorm Sandy bore down on the eastern seaboard.
Higher education needs the cloud. The innovation, flexibility, cost effectiveness and security provided by public cloud solutions give us a tremendous head start on building tomorrow’s technology infrastructure for our campuses. Let’s enjoy the journey!
Originally published on LinkedIn November 12, 2014