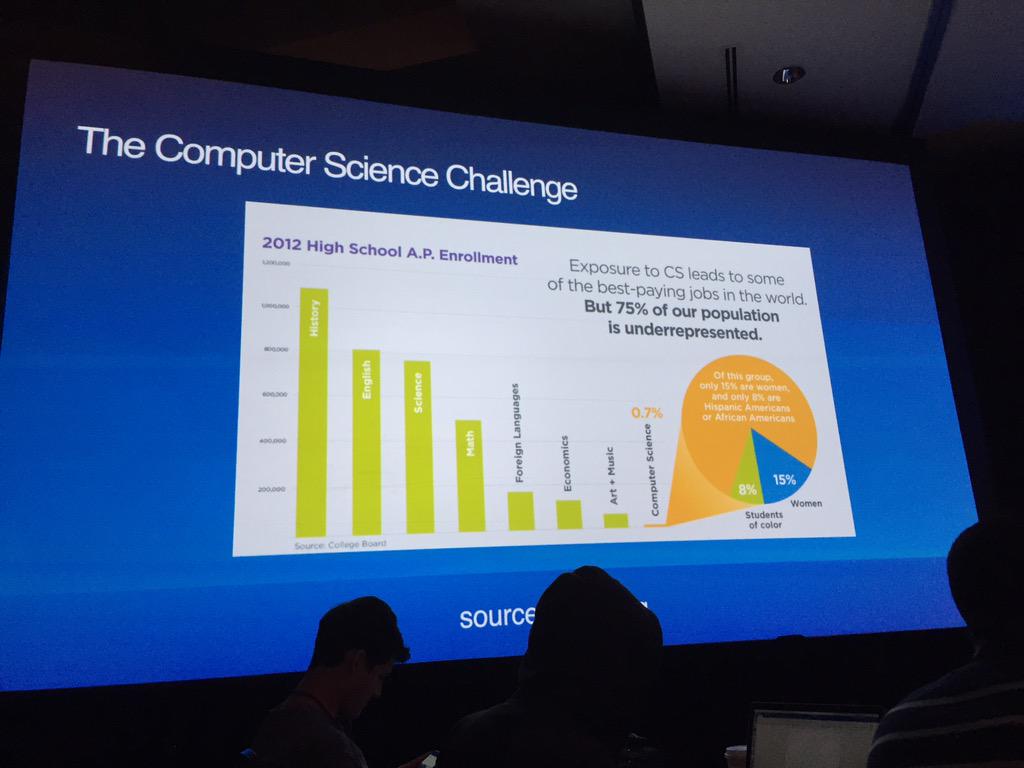
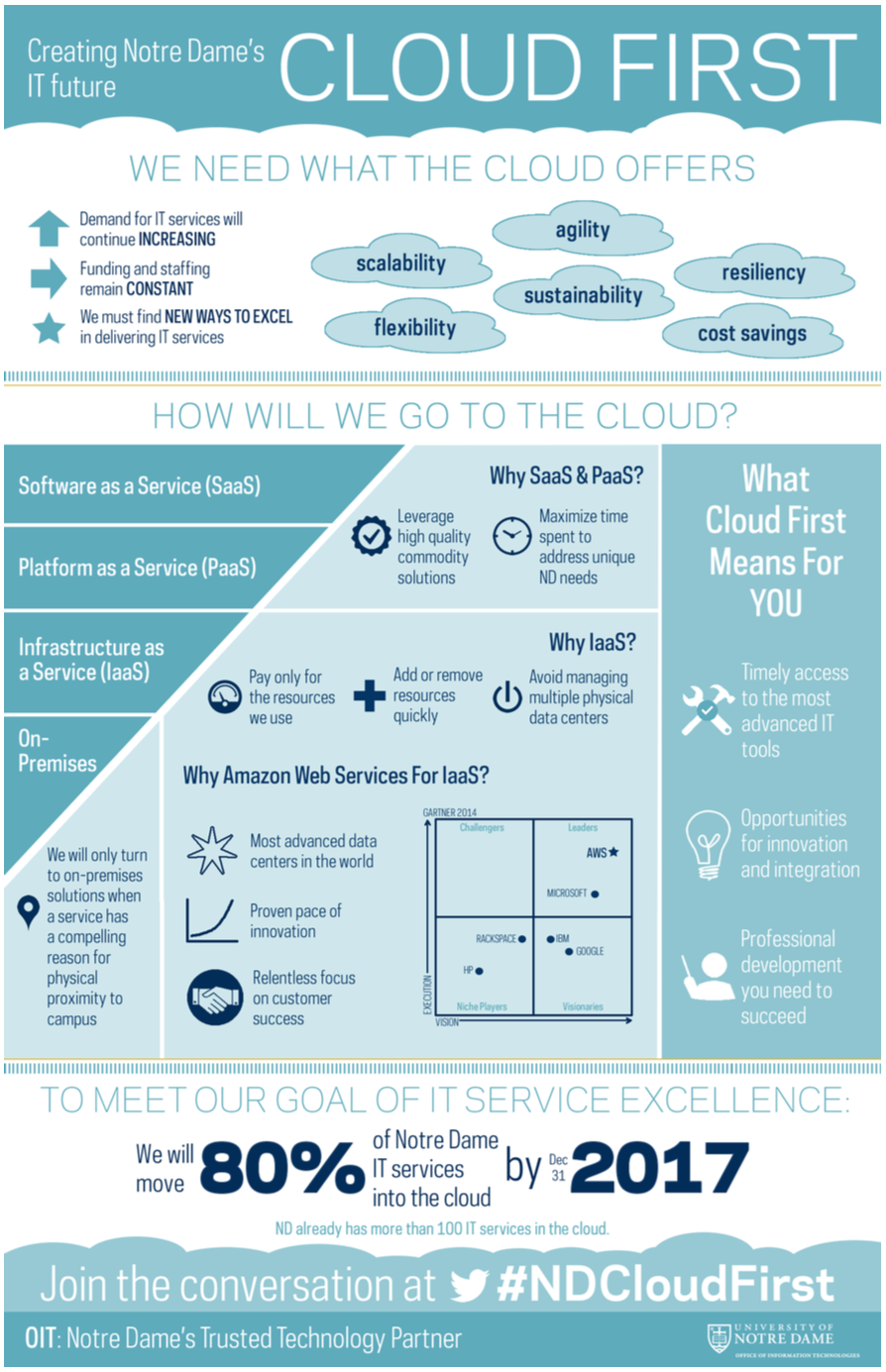
How fast is it really? In the course I teach, students have the opportunity to interact with a database, taking their logical models, turning them into physical designs, and finally implementing them.
Up until this semester, I have made use of a database that is local to campus. The ongoing management and maintenance of that environment is something which is of no particular interest to me – I just want to use the database. Database-as-a-Service, as it were. As in, Amazon Relational Database Service.
Lucky for us all, Amazon has a generous grant program for education. After a very straight-forward application process, I was all set to experiment.
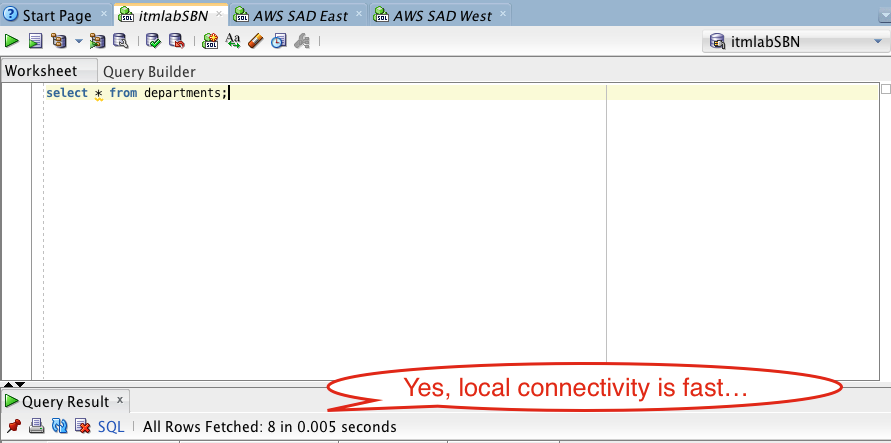
To baseline, I executed a straightforward query against a small, local table. Unsurprisingly, the response time was lightning-fast.
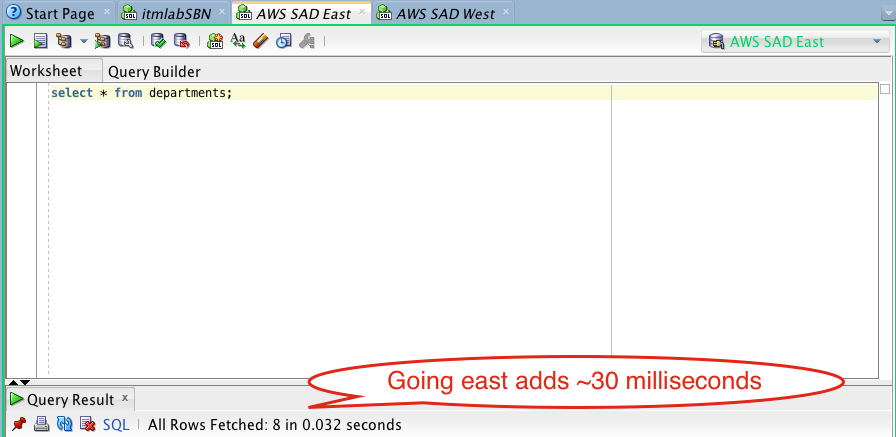
Using RDS, I went ahead and created an Oracle database, just like the one I have typically used on campus. After setting up a VPC, subnet groups, and creating a database subnet group, I chose to create this instance in Amazon’s N. Virginia Eastern Region. Firing off the test, we find that, yes, it takes time for light to travel between Notre Dame’s campus and northern Virginia:
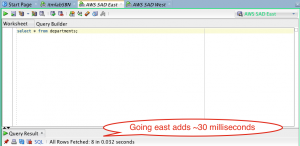
Looks like it added about 30 milliseconds. I can live with that.
Out of curiosity, how fast would it be to the west coast? Say, Amazon’s Oregon Western Region? Fortunately, it is a trivial exercise to find out. I simply snapshotted the database and copied the snapshot from the eastern region to the west. A simple restore and security group assignment later, and I could re-execute my test:
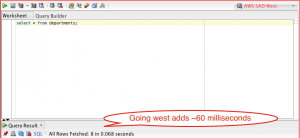
Looks like the time added was roughly double – 60 milliseconds.
Is that accurate? According to Google Maps, it looks like yes indeed, Oregon is roughly twice as far away from Notre Dame as Virginia. The speed of light doesn’t lie.
So, what did I learn? First, imagine for a moment what I just did. Instantiate an Oracle database, on the east coast, and the west coast. From nothing! No servers to order, to routers to buy, no disks to burn in, no gnomes to wire equipment together, no Oracle Universal Installer to walk through. I still get a thrill every time I use Amazon services and think about what is actually happening. I can already see myself when I’m 70, regaling stories about what it was like to actually see a data center.
OK, deep breath.
Second, is 30 milliseconds acceptable? For my needs, absolutely. My students can learn what they need to, and the 30 millisecond hit per interaction is not going to inhibit that process. It’s certainly a reasonable price to pay, especially considering there is nothing to maintain.
What is the enterprise implication? Is 30 milliseconds going to be insufficient? An obstacle that inhibits business processes? We shall see. For local databases and remote web/application servers, perhaps. Perhaps not.
This is why we test, remembering that despite what a remarkably amazing toolset AWS represents, we are still bound by the speed limit of light.
AWS Midwest Region, anyone?