You work in IT. You’re in higher education. It’s 2014. Get a move on!
1. Back up your files.
When your machine crashes, you’ll get no sympathy. The whole world knows you should back up your computer. There’s no excuse. Go get CrashPlan or some other way to make sure your stuff isn’t lost. No, don’t go on to number two until you’ve finished this. It’s that important.
2. Use a password manager.
Most people only use a couple of passwords frequently enough to remember them. Go get PasswordSafe (pwSafe on the Mac) and start generating random passwords for your accounts. Don’t bother remembering them, just store ’em in your password manager and copy/paste when you need them. Secure this password manager with one hard password (the only one you have to remember).
3. Use a collaboration tool to share files rather than emailing them.
Email attachments fill up your mailbox and affect performance. Now think about how that might affect your recipients. Just use a tool like Box and send a share link. Much easier and you can control it later if you need to.
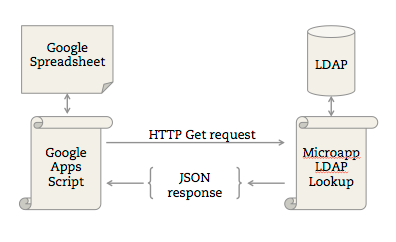
4. Learn some basic scripting, even if it’s just an Excel formula.
You don’t need to be a programmer to do some basic string manipulation or some basic conditionals (if-then). Excel or Google Spreadsheets are incredibly powerful tools in their own right.
5. Find a reliable IT news source relevant to your area (news site, mailing list, blog, twitter).
Make it part of your daily habit to check your RSS (try feedly.com) or Twitter feeds. Seek out and follow a couple of good news sites, tech journalists, or smart people who keep tabs on IT stuff. Let these people be your filter and don’t be in the dark about what’s going on in your industry.
6. Build relationships with people who can help you improve, especially from other departments or organizations.
We learn from each other – by listening, by teaching, or by doing. Join campus communities (e.g., Developer Meetups or Mobile Community of Practice), higher ed user groups, Educause constituent groups, industry consortiums, etc. If it doesn’t exist, create one.
7. Contribute back to the community – an open source project, present at a conference, write a blog post, etc.
You’re standing on the shoulders of giants, and with luck your successors may just stand on yours. We benefit from so many other generous contributions and we’re fortunate to work in higher education, where our counterparts are willing to swap stories and strategies. Be a part of the larger community.
8. Listen to your customers.
Work is happier when your customers are happier. What can you do that will make their lives better? How do you know without talking to them? Get out there and watch them use your software, have them brainstorm ideas, or just listen to them complain. Just knowing that they’re being heard will make your customers happier.
9. Figure out your smartphone.
There’s nothing sillier than an IT person who is computer illiterate, and that counts for your smartphone as well. It’s a magical supercomputer in your pocket. It probably cost you a bunch of money and it does way more than phone, email, and Angry Birds. You can tie in with your VoIP phone, access files via Box, edit Google Docs, submit expense reports, and other wizardry.
10. Break stuff.
Our world is full of settings screens, drop-down menus, config files, old hardware, and cheap hosting. Sadly, too many people are afraid of what might go wrong and they never discover the latest features, time-saving methods, or opportunities to innovate. Try out the nightly build (in dev, maybe). Ask vendors about loaning you some demo hardware. Challenge yourself on whether there’s another way to get it done. You’re in IT. Don’t be afraid to break something – it can be fixed. And who knows? You might just learn a thing or two.