So I have an EC2 instance sitting in a subnet in a VPC on Amazon. Thanks to Puppet, It’s got a rails server, nginx, and an Oracle client. But it’s got no one to talk to.
It’s time to build a VPN tunnel to campus. Many, many thanks go to Bob Richman, Bob Winding, Jaime Preciado-Beas, and Vincent Melody for banding together to work out what I’m about to describe.
It turns out the AWS side of this configuration is not actually very difficult. Once traffic reaches us, there’s a lot more configuration to do! Here’s a quick sketch:
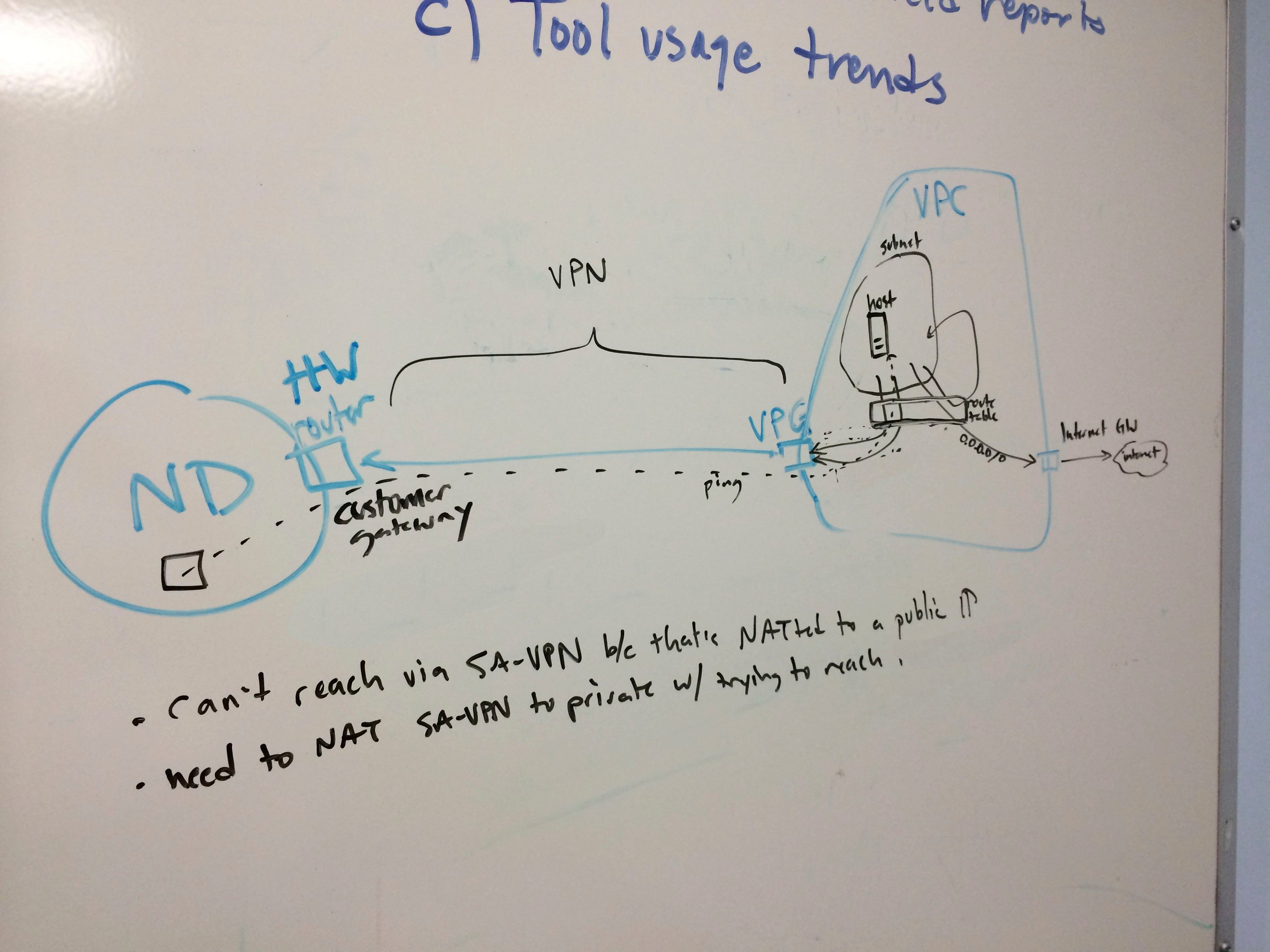 IPs and subnets obscured
IPs and subnets obscured
You can see the VPC, subnet, and instance on the right. The rectangle represents the routing table attached to my subnet. Addresses in the same subnet as the instance get routed back inside the subnet. Everything else (0.0.0.0/0) goes to the internet gateway and out to the world.
Configuring The Tunnel
To actually communicate with resources inside the Notre Dame firewall, such as our Banner databases, we need a few new resources. These objects are pretty simple to create in software on AWS:
- the virtual private gateway. This is basically a router that sits on the AWS side of the VPN tunnel we’ll create. You attach it to the VPC, and then you’re done with that object.
- the customer gateway. When you create this object, you give it the public IP of a router on your network. We’re using one that resides on the third floor of this building. You need to configure this router to function as the VPN endpoint. Fortunately, we have people like Bob Richman, who just know how to do that sort of thing. If we didn’t, AWS provides a “download configuration” button that gives you a config file to apply to the router. You can specify the manufacturer, type, and firmware level of the router so that it should be plug-and-play.
- the VPN connection. This object bridges the two resources named above.
Setting up Routing
Now we want certain traffic to flow over this connection to ND and back again. Here’s where I start to pretend to know things about networking.
- AWS routing table. We need to set routes on the subnet to which our instance belongs, forwarding traffic intended for Notre Dame resources to the Virtual Private Gateway described above. No problem. We define the IP/subnet ranges we want (example: the range for our Banner database service listeners), and route them to the VPG.
- VPN Connection static routes. As I mentioned, this resource bridges the VPG and the Customer gateway on our side. So it needs the same rules to be configured as static routes.
At this point, we are in business! Kind of. I can ping my EC2 instance from campus, but I can’t talk to Oracle from EC2.
Fun Times with DNS
Getting to our development database from anywhere requires a bit of hoop-jumping. For an end user like me, running a SQL client on my laptop, it typically goes like this:
- I use LDAP to connect to an OID (Oracle Internet Directory) server, specifying the service name I want. My ldap.ora file contains four different domain names: two in front of the firewall and two behind. It fails over until it can reach one. So it’s not super-intelligent, but no matter where I call from, one of them should work.
- The OID server responds with the domain name of a RAC cluster machine that can respond to my request.
- My request proceeds to the RAC cluster, which responds with the domain of a particular RAC node that can service the actual SQL query.
With a little help from Infosec, setting up ND firewall rules, we can connect to LDAP, we can connect to the RAC cluster, and we can even connect to the RAC node. Via telnet, using IP addresses. Notice the reliance on DNS above? This got us into a bit of a mess.
Essentially, it was necessary to set up special rules to allow my AWS VPN traffic to use the ND-side DNS servers. I needed to edit my EC2 instance’s resolv.conf to use them. We also ran into an issue where the RAC node resolved to a public IP instead of a private one. This was apparently a bit of a hack during the original RAC setup, and firewall rules have been established to treat it like a private IP. So again, special rules needed to be established to let me reach that IP over the VPN tunnel.
Success!
After these rules were in place and routes added to the VPN to use them, viola! I am now able to make a Banner query from AWS. This is a fantastic step forward for app development in the cloud. It’s only one piece of the puzzle, but an important one, as it is inevitable that we will want to deploy services to AWS that talk to ND resources of one kind or another.
Our networking, infosec, and database guys will probably tell you that some cleanup ought to be done on our side re: network architecture. There are some “interesting” exceptions in the way we have laid out these particular services and their attendant firewall configuration. The special rules we created to get this working are not really scalable. However, these challenges are surmountable, and worth examining as we move forward.
In the meantime, we have made a valuable proof-of-concept for cloud application development, and opened up opportunities for some things I have wanted to do, like measure network latency between AWS and ND. Perhaps a topic for a future blog post!
Onward!