Despite design principles, despite best intentions, things can go wrong. This is true when all of the design parameters are quantifiable, as exhibited by this spectacular engine failure: What happens when some of the design constraints are not fully understood? Specifically, consider the following excerpt taken from Amazon’s page detailing instance specifications:
What happens when some of the design constraints are not fully understood? Specifically, consider the following excerpt taken from Amazon’s page detailing instance specifications:
| Instance Family | Instance Type | Processor Arch | vCPU | ECU | Memory (GiB) | Instance Storage (GB) | EBS-optimized Available | Network Performance |
| Storage optimized | i2.xlarge | 64-bit | 4 | 14 | 30.5 | 1 x 800 SSD | Yes | Moderate |
| Storage optimized | i2.2xlarge | 64-bit | 8 | 27 | 61 | 2 x 800 SSD | Yes | High |
| Storage optimized | i2.4xlarge | 64-bit | 16 | 53 | 122 | 4 x 800 SSD | Yes | High |
| Storage optimized | i2.8xlarge | 64-bit | 32 | 104 | 244 | 8 x 800 SSD | – | 10 Gigabit*4 |
| Storage optimized | hs1.8xlarge | 64-bit | 16 | 35 | 117 | 24 x 2,048*3 | – | 10 Gigabit*4 |
| Storage optimized | hi1.4xlarge | 64-bit | 16 | 35 | 60.5 | 2 x 1,024 SSD*2 |
– | 10 Gigabit*4 |
| Micro instances | t1.micro | 32-bit or 64-bit |
1 | Variable*5 | 0.615 | EBS only | – | Very Low |
According to Amazon’s page on instance types (emphasis added):
Amazon EC2 allows you to provision a variety of instances types, which provide different combinations of CPU, memory, disk, and networking. Launching new instances and running tests in parallel is easy, and we recommend measuring the performance of applications to identify appropriate instance types and validate application architecture. We also recommend rigorous load/scale testing to ensure that your applications can scale as you intend.
Using LoadUIWeb by Smartbear, we were able to take a given workload and run it on different instance types to gain a better understanding of the performance differences. Running 100 simultaneous virtual users with a 9 millisecond think time between pages, we ran against an M1.small and an M1.medium. Here is are some pictures to illustrate what we discovered:
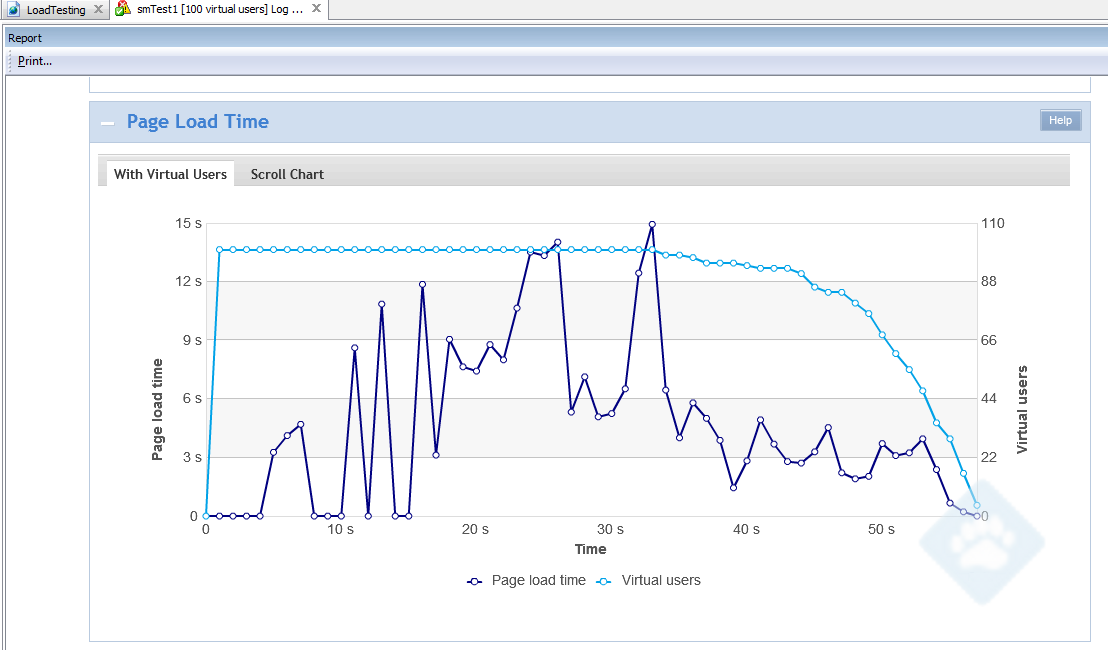
M1.small performance test output:

M1.medium performance test output:
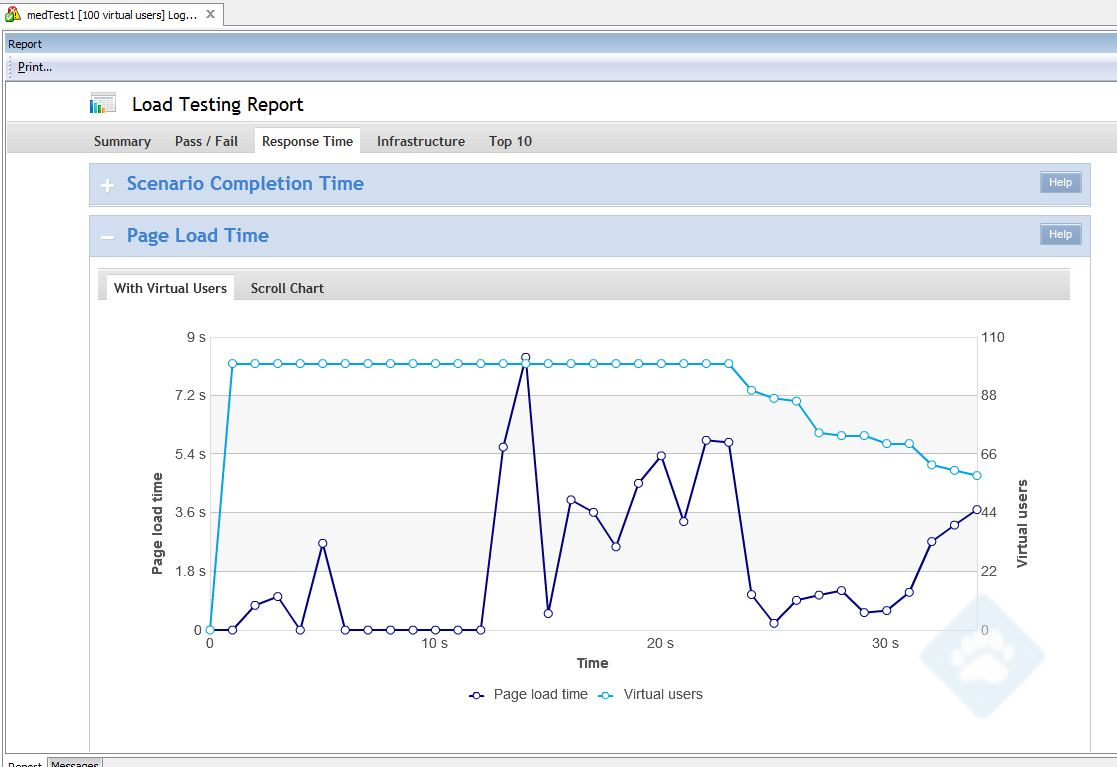
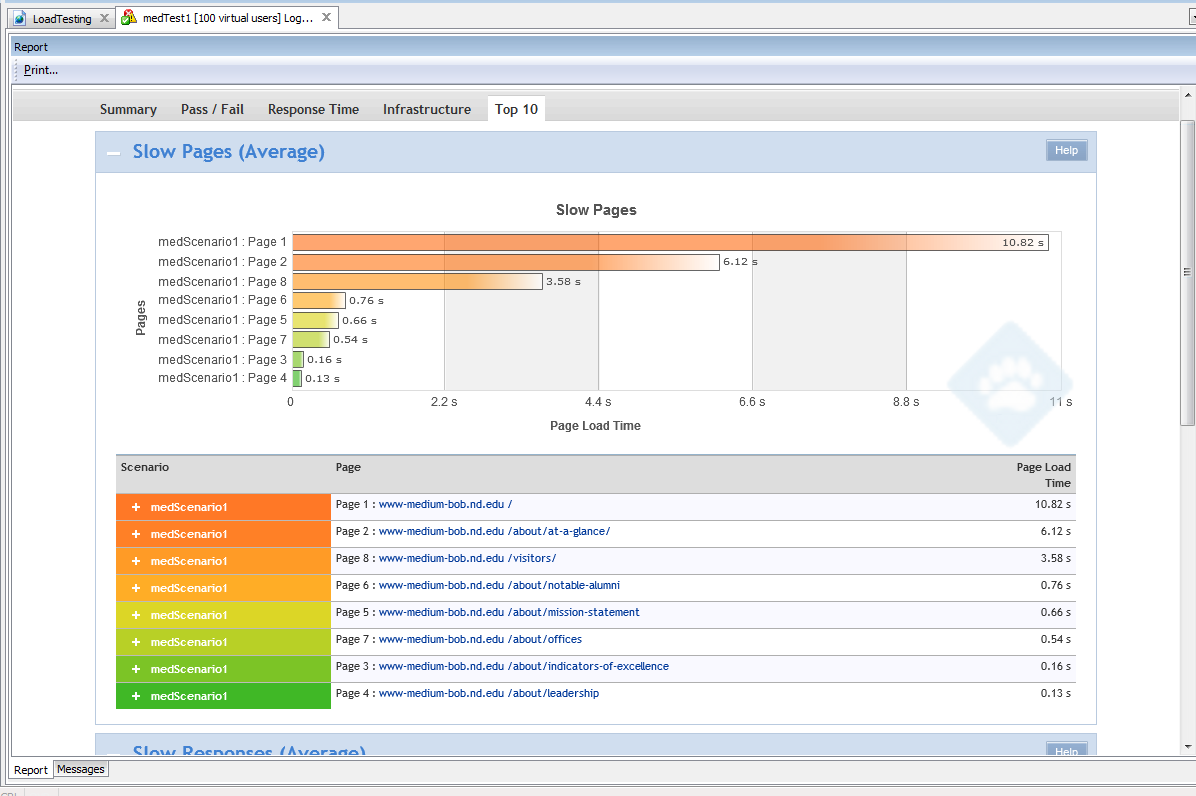
Looking at the numbers, we see that the the response time of the small is roughly twice that of the medium. As neither CPU, memory, or disk activity were constraints, this serves as a warning to us – the quality of service limitations placed on different instance types must be taken into consideration when doing instance size analysis.
When in doubt, test it out!