I’ve been a Google Apps user for as long as I could score an invite code to Gmail. Then came Google Calendar, Google Docs and Spreadsheets, and a whole slew of other stuff. But as I moved from coder to whatever-I-am-now, I stopped following along with the new stuff Google and others kept putting out there. I mean, I’m vaguely aware of Google Apps Engine and something called Google Apps Script, but I hadn’t spent any real time looking at them.
But as any good IT professional should, I’m not afraid to do a little scripting here any there to accomplish a task. It’s fairly common to get a CSV export that needs a little massaging or find a perfect API to mash up with some other data.
The other day, I found myself working with some data in a Google Spreadsheet and thinking about one of my most common scripting tasks – appending data to existing data. For instance, I start with something like a list of users and want to know whether they are faculty, staff, or student.
| netid |
name |
Affiliation |
| cgrundy1 |
Chas Grundy |
??? |
| katie |
Katie Rose |
??? |
Aside: Could I get this easily by searching EDS? Sure. Unfortunately, my data set might be thousands of records long and while I could certainly ask our friends in identity management to get me the bulk data I want, they’re busy and I might need it right away. Or at least, I’m impatient and don’t want to wait. Oh, and I need something like this probably once or twice a week so I’d just get on their nerves. Moving on…
So that’s when I began to explore Google Apps Script. It’s a Javascript-based environment to interact with various Google Apps, perform custom operations, or access external APIs. This last part is what got my attention.
First, let’s think about how we might use a feature like this. Imagine the following function:
=getLDAPAttribute("cgrundy1","ndPrimaryAffiliation")
If I passed it the NetID and attribute I wanted, perhaps this function would be so kind as to go fetch it for me. Sounds cool to me.
Now the data I want to append lives in LDAP, but Javascript (and GA Script) can’t talk to LDAP directly. But Google Apps Script can interpret JSON (as well as SOAP or XML), so I needed a little LDAP web service. Let’s begin shaving the yak. Or we could shave a wookiee.
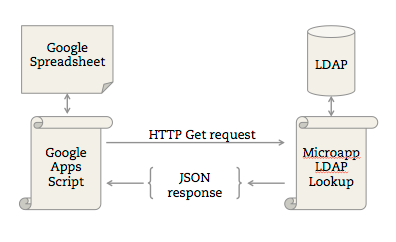
First, I cobbled together a quick PHP microapp and threw it into my Notre Dame web space. All it does is take two parameters, q and attribute, query LDAP, and return the requested attribute in JSON format.
Here’s an example:
index.php?q=cgrundy1&attribute=ndPrimaryAffiliation
And this returns:
{
"title": "LDAP",
"attributes": {
"netid": "cgrundy1",
"ndprimaryaffiliation": "Staff"
}
}
View the full PHP script here
For a little extra convenience, the script allows q to be a NetID or email address. Inputs are sanitized to avoid LDAP injections, but there’s no throttling at the script level so for now it’s up to the LDAP server to enforce any protections against abuse.
Next, the Google Apps Script needs to actually make the request. Let’s create the custom function. In Spreadsheets, this is found under Tools > Script Editor.
function getLDAPAttribute(search,attribute) {
search = search.toLowerCase();
attribute = attribute.toLowerCase();
var attr_value = "";
var url = 'https://www3.nd.edu/~cgrundy1/gapps-ldap-test/?'
+ 'q=' + search
+ '&attribute=' + attribute;
var response = UrlFetchApp.fetch(url);
var json = response.getContentText();
var data = JSON.parse(json);
attr_value = data.attributes[attribute];
return attr_value;
};
This accepts our parameters, passes them along to the PHP web service in a GET request, parses the response as JSON, and returns the attribute value.
Nota bene: Google enforces quotas on various operations including URL Fetch. The PHP script and the Google Apps Script function could be optimized, cache results, etc. I didn’t do those things. You are welcome to.
Anyway, let’s put it all together and see how it works:

Well, there you have it. A quick little PHP microapp, a simple custom Javascript function, and now a bunch of cool things I can imagine doing with Google Apps. And just in case you only clicked through to this article because of the title:
<joke>I tried the Wookiee Steak, but it was a little chewy.</joke>




![By Kbh3rd (Own work) [CC BY 4.0 (http://creativecommons.org/licenses/by/4.0)], via Wikimedia Commons](http://blogs.nd.edu/devops/files/2016/06/Weldon_Spring_Site_containment_stairway_1.jpg)