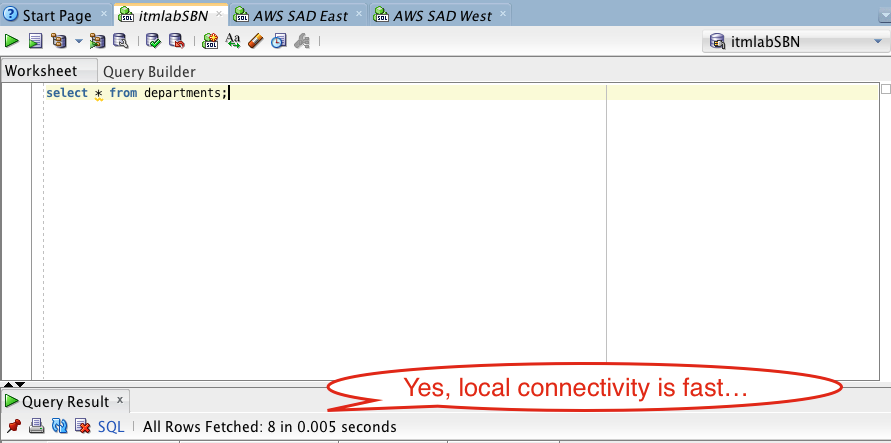
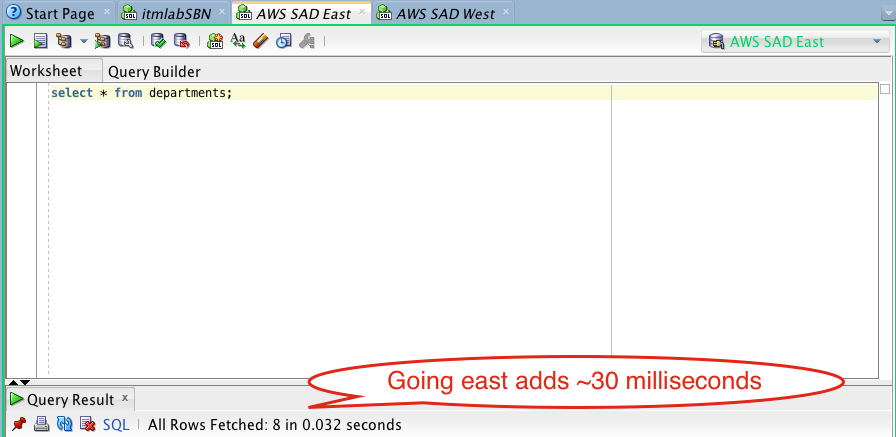
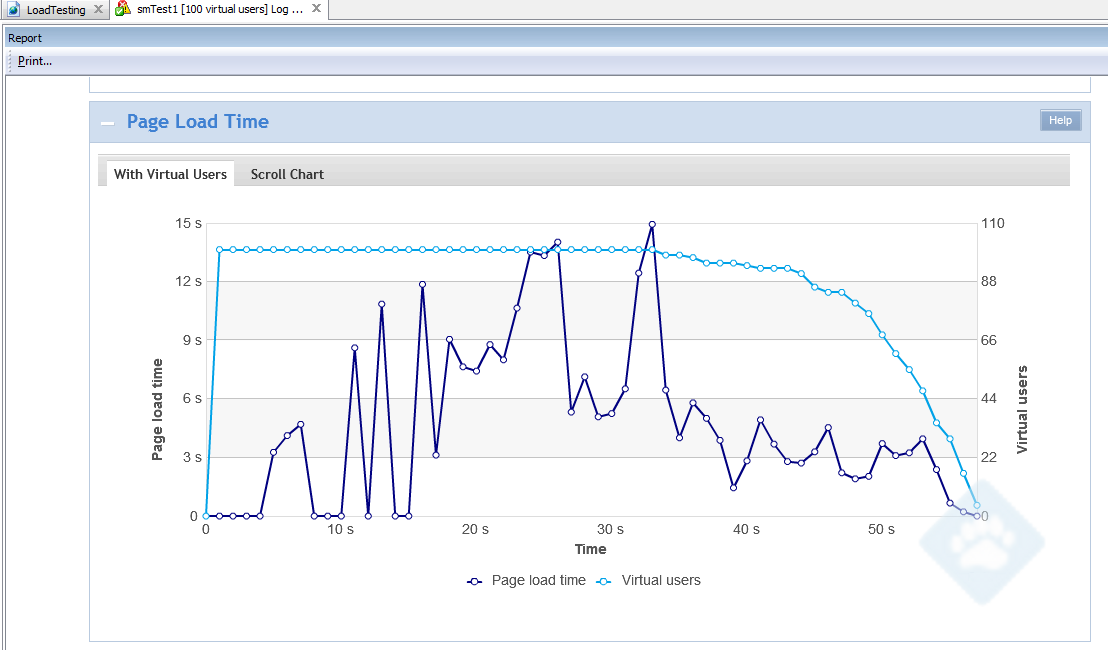
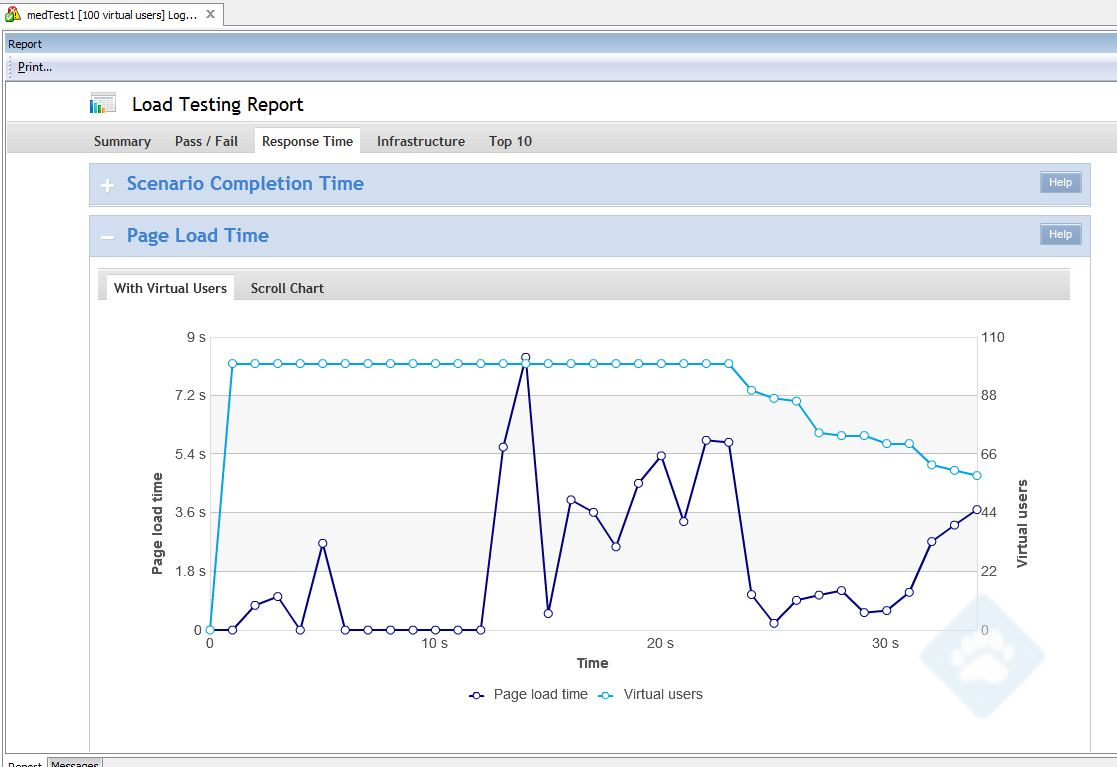
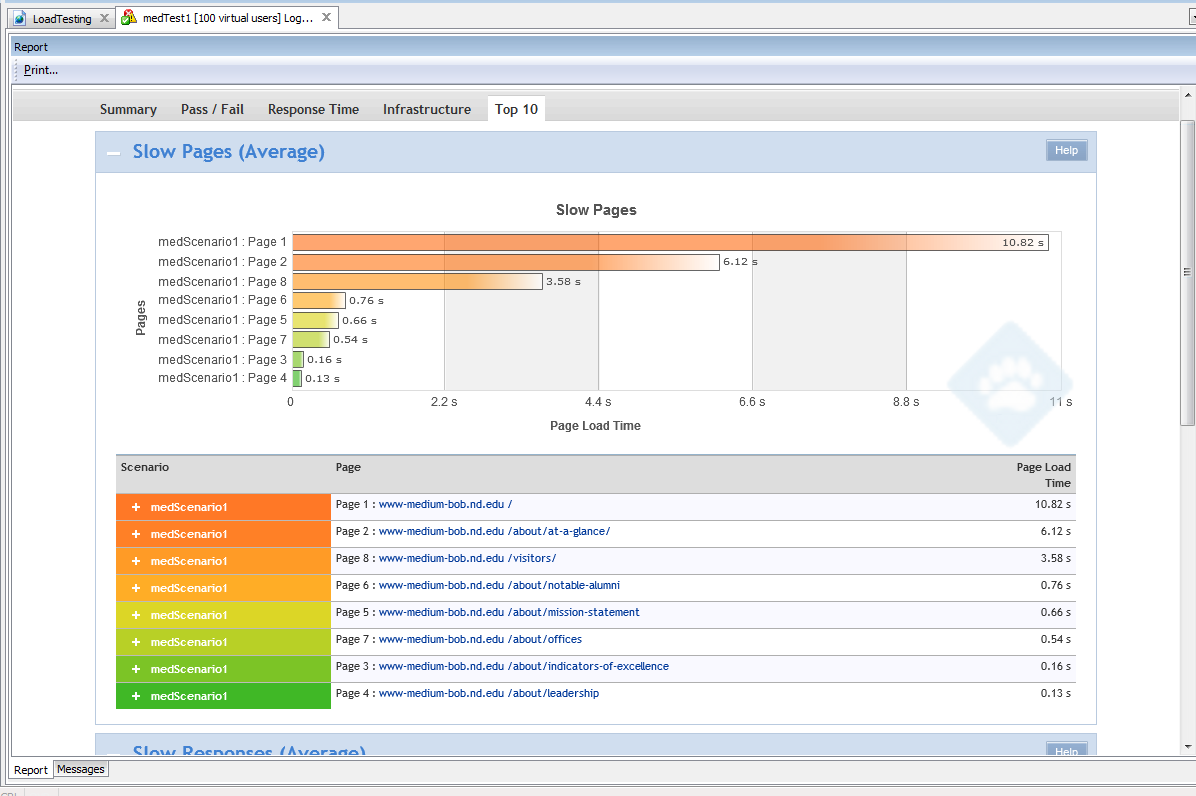
Today is the most exciting day of my modern professional life. It’s the day we are announcing to the world our goal of migrating 80% of our IT service portfolio to the cloud over the next three years.
Yes, that’s right, 80% in 3 years. What an opportunity! What a challenge! What a goal! What a mission for a focused group of IT professionals!
The following infographic accurately illustrates our preference in terms of prioritizing how we will achieve this goal.
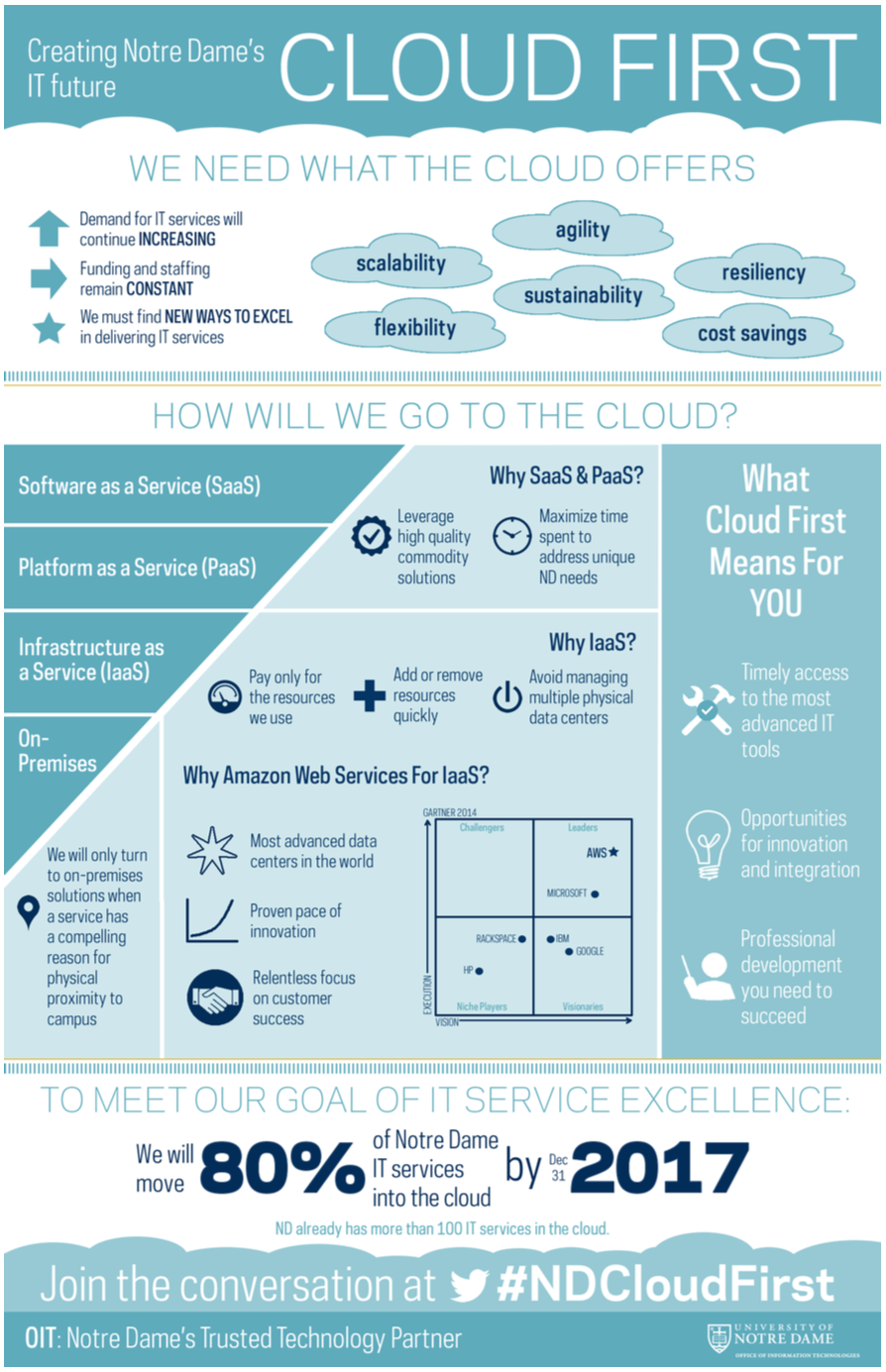
Opportunistically, we will select SaaS products first, then PaaS products, followed by IaaS, with solutions requiring on-premises infrastructure reserved for situations where there a compelling need for geographic proximity.
The layer at which we, as an IT organization, can add value without disrupting university business processes is IaaS. After extensive analysis, we have selected Amazon Web Services as our IaaS partner of choice, and are looking forward to a strong partnership as we embark upon this journey.
Already documented on this blog are success stories Notre Dame has enjoyed migrating www.nd.edu, the infrastructure for the Notre Dame mobile app, Conductor (and its ~400 departmental web sites), a copy of our authentication service, and server backups into AWS. We have positioned ourselves to capitalize on what we have learned from these experiences and proceed with migrating the rest of the applications which are currently hosted on campus.
So incredibly, incredibly fired up about the challenge that is before us.
If you want to learn more, please head over to Cloud Central: http://oit.nd.edu/cloud-first/
Onward!