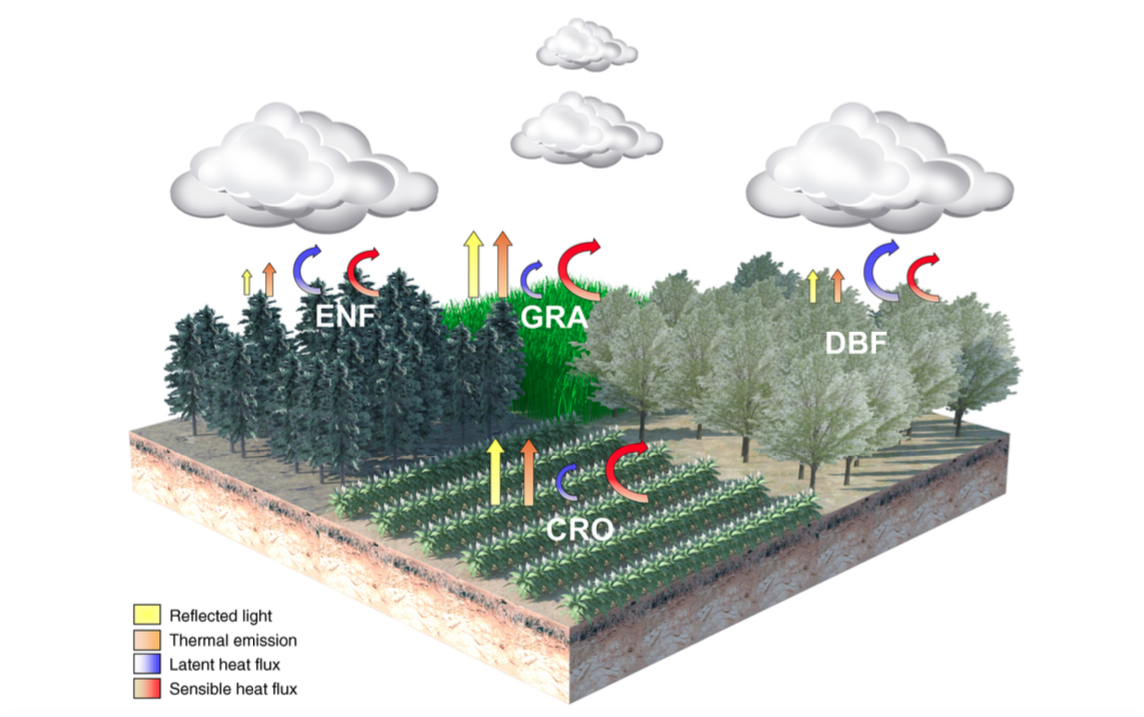
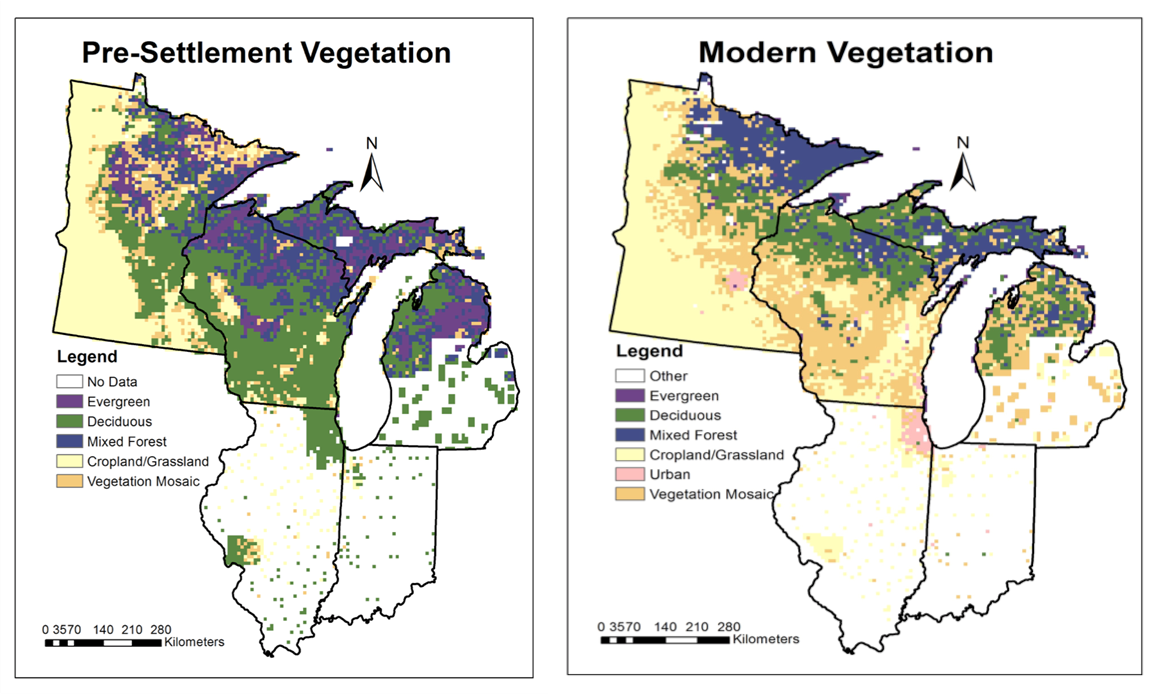
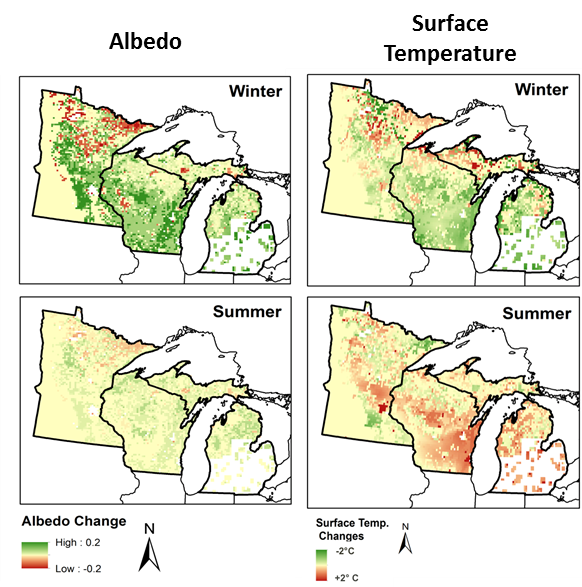
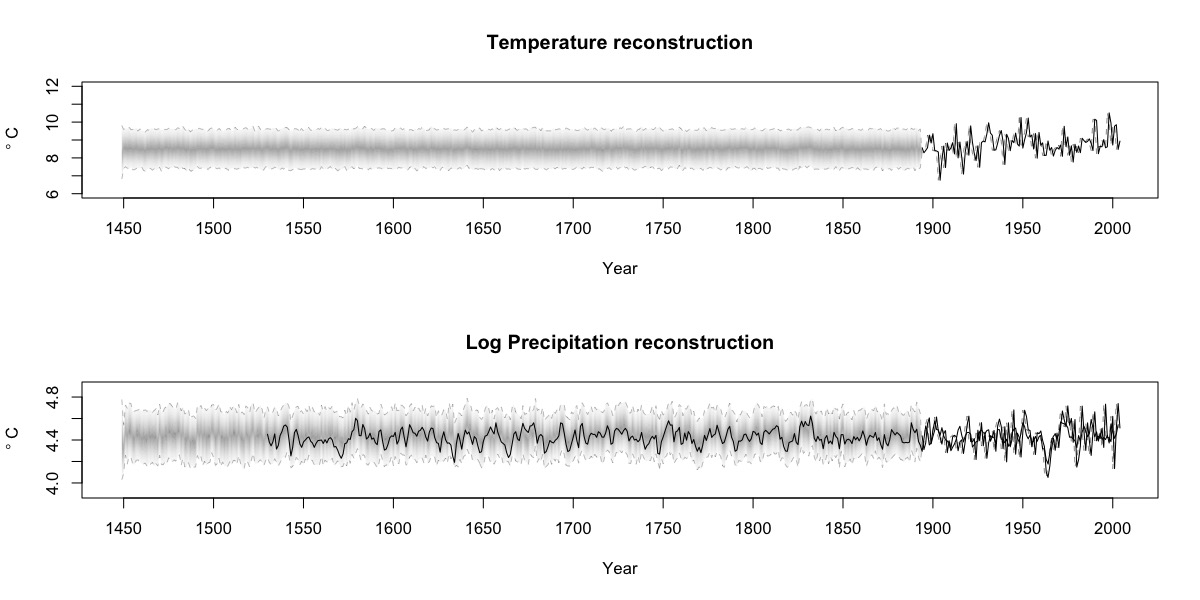
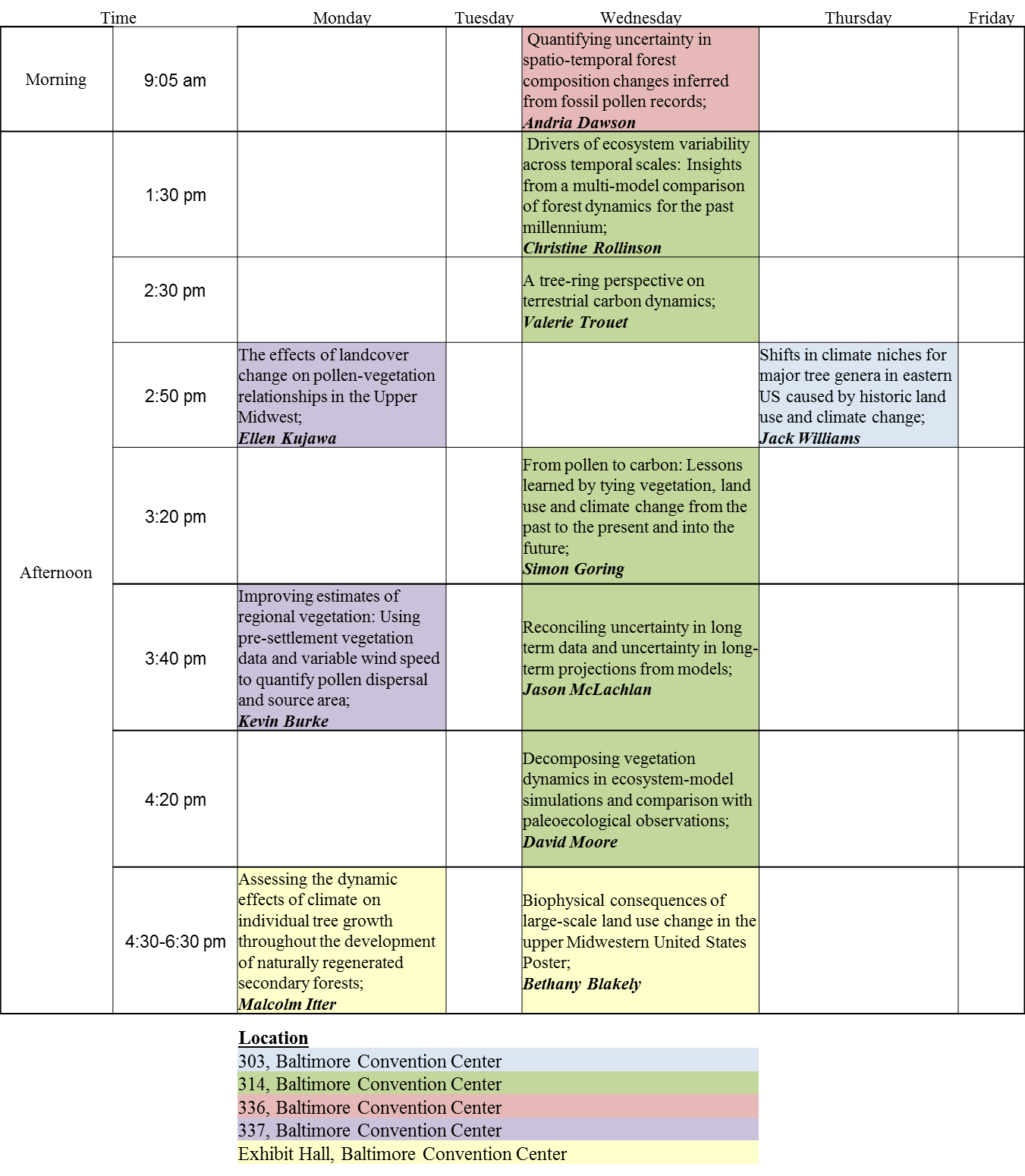
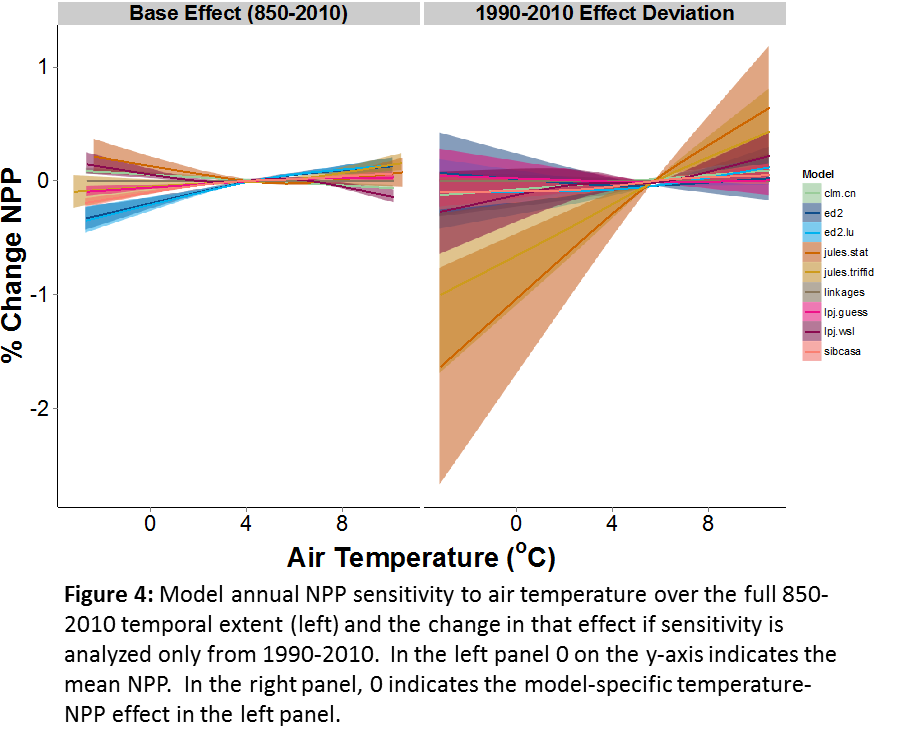
Post by Tyler Hoecker graduate student with Philip Higuera at the University of Montana. Tyler received an Outstanding Student Paper Award when he presented this work at AGU 2015!
Over the past two decades the paleoecological research community has amassed dozens of sediment cores from across Alaska. These long-term records contain a range of clues about the character of ecosystems and climate that existed deep in the past. Some records extend back as far as 14,000 years, and have been used to reconstruct millennial-scale vegetation, climate and disturbance dynamics. For example, Higuera et al. (2009) identified the marked increase in biomass burning and fire frequency following the transition from forest-tundra to modern black-spruce dominated boreal forest ca. 5000-6000 years ago using cores from four lakes in the south-central Brooks Range (Figure 1).
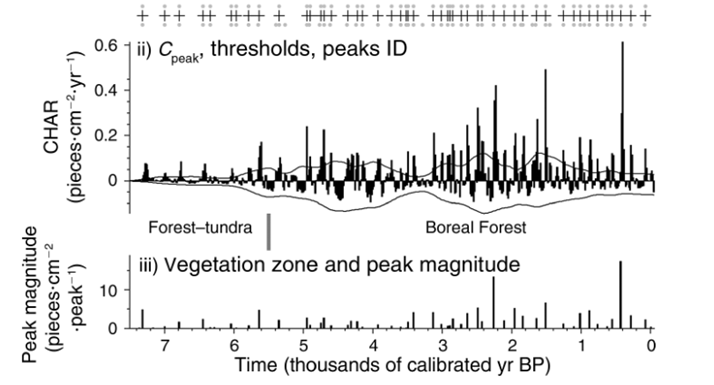
Figure 1. Paleocharcoal record from a south-central Brooks Range lake presented in Higuera et al. 2009. Vertical bars in the top panel show the charcoal accumulation rate (CHAR; pieces cm-2 year-1) over the past 7,000 years, and crosses indicate peaks in CHAR that are inferred to represent local fire events. Bottom panel shows peak magnitude (pieces cm-2 peak-1) delineated by vegetation zone.
More recent work has focused in on the past two millennia to understand the sensitivity of fire regimes in the boreal forest to centennial-scale climate change, including the Medieval Climate Anomaly (MCA) and the Little Ice Age (LIA) (Kelly et al., 2013). Persisting from ca. 850-1200 A.D. (750-1100 calibrated years before present), the MCA has been proposed as a rough analog to modern and predicted climate warming. This work identified significant increases in biomass burning during the MCA based on 14 cores from the Yukon Flats region of boreal forest, likely in response to regional warming. Biomass burning tapered off before LIA cooling began, hypothesized to reflect negative feedbacks from fuel limitations (Kelly et al., 2013).
The synthesis work I presented at AGU built on the work of Kelly et al. (2013) and focused on characterizing centennial-scale variability over the past two millennia in an additional 12 published fire-history records from elsewhere in the Alaskan boreal forest and tundra (Copper River Basin, Brooks Range, Noatak River Watershed). I looked at these records as Alaskan-wide (n=26) and regional composites (n=14 in Yukon Flats and n=4 elsewhere).

Figure 2. Maps of new and published paleocharcoal records used in the synthesis. 26 paleocharcoal records were analyzed as an Alaskan-wide composite, and as ecoregional composites (colored polygons). 8 new records were collected in the Kuskokwim Mountains ecoregion of interior boreal forest (dark green polygon, westernmost points) in June 2015. Wildfire burn perimeters since 1939 are shown in red.
Each of the composite records demonstrates the pronounced high-frequency variability in fire activity, but long-term trends were also revealed. As an Alaskan-wide composite, this analysis suggests a relatively cohesive increase in biomass burning during the MCA, and a reduction during the LIA, largely reflecting the influence of the Yukon Flats records (Figure 3).
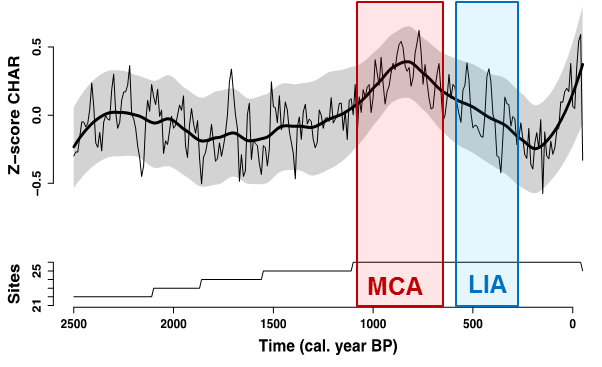
Figure 3. Alaskan-wide composite of 26 paleocharcoal records. Top panel shows the Z-score of charcoal accumulation rate (CHAR; pieces cm-2 year-1) over the last 2500 years. Thick black line represents a 500-year mean, thin black line represents a 100-year mean, and gray band indicates bootstrapped 90% confidence intervals around the 500-year mean. Colored bars indicate the approximate persistence of the Medieval Climate Anomaly (MCA) and Little Ice Age (LIA). Bottom panel indicates the number of records contributing to the composite through time (22-26).
When considered as regional composites (Figure 4) variability across Alaska emerges. At this scale the Yukons Flats, Copper River Basin, and Noatak River Watershed all show a sensitivity to warming, with some variability in the timing of this response. However, the Brooks Range sites show little low-frequency variability during either the MCA or LIA. This suggests that vegetation feedbacks or regional-scale controls act to moderate the impact of warming on biomass burning. Alternatively, climate forcing could have been uneven across Alaska as this scale, and/or climate forcing may not have been substantial enough in some regions to elicit a response in fire regimes. The sensitivity in observed paleocharcoal records may also be a function of sample size; centennial-scale change in some regions may be subtler than can be detected with only four lake cores.
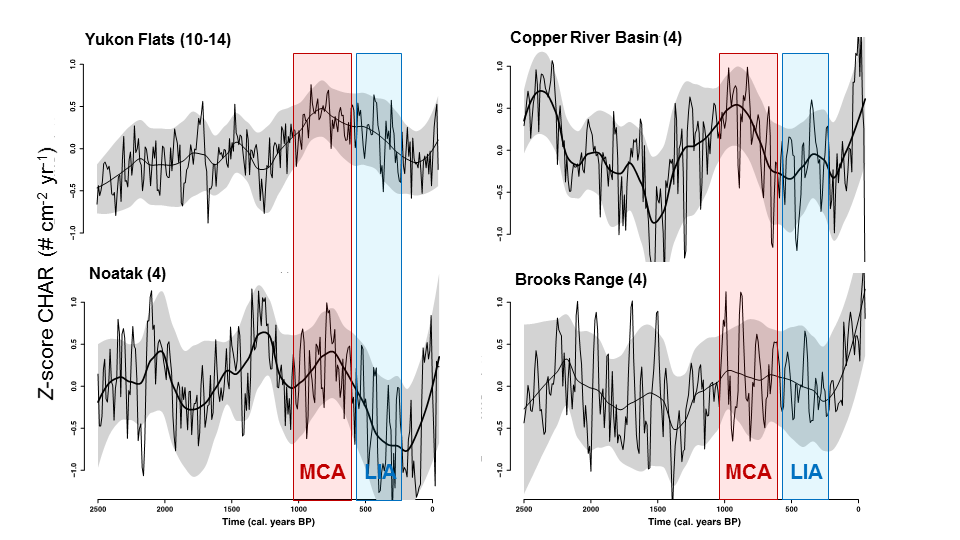
Figure 4. Regional composite paleocharcoal records. Time series are labeled by region (number of records). Each shows the Z-score of charcoal accumulation rate (CHAR; pieces cm-2 year-1) over the last 2500 years. Thick black line represents a 500-year mean, thin black line represents a 100-year mean, and gray band indicates bootstrapped 90% confidence intervals around the 500-year mean. Colored bars indicate the approximate persistence of the Medieval Climate Anomaly (MCA) and Little Ice Age (LIA).
Untangling the potential mechanisms driving the variability across time and space will require similar analyses with larger datasets. For my PalEON-supported MS thesis I will incorporate eight new lake-sediment records collected in 2015 to assess fire-regime sensitivity in a climatically distinct region (Figure 2). This network of lakes will lend itself to detecting the relatively short-term variability of the MCA and LIA. Spatially explicit reconstructions of climate over this time period will also help to explain the causes of variability in biomass burning, and improve our understanding of the relative importance of climate and vegetation dynamics in driving fire regime trend.
Citations
Higuera et al. 2009. Vegetation mediated the impacts of postglacial climate change on fire regimes in the south-central Brooks Range, Alaska. Ecological Monographs 79(2): 201-219
Kelly et al. 2013. Recent burning of boreal forests exceeds fire regime limits of the past 10,000 years. Proceedings of the National Academy of Sciences 110(32): 13055-13060