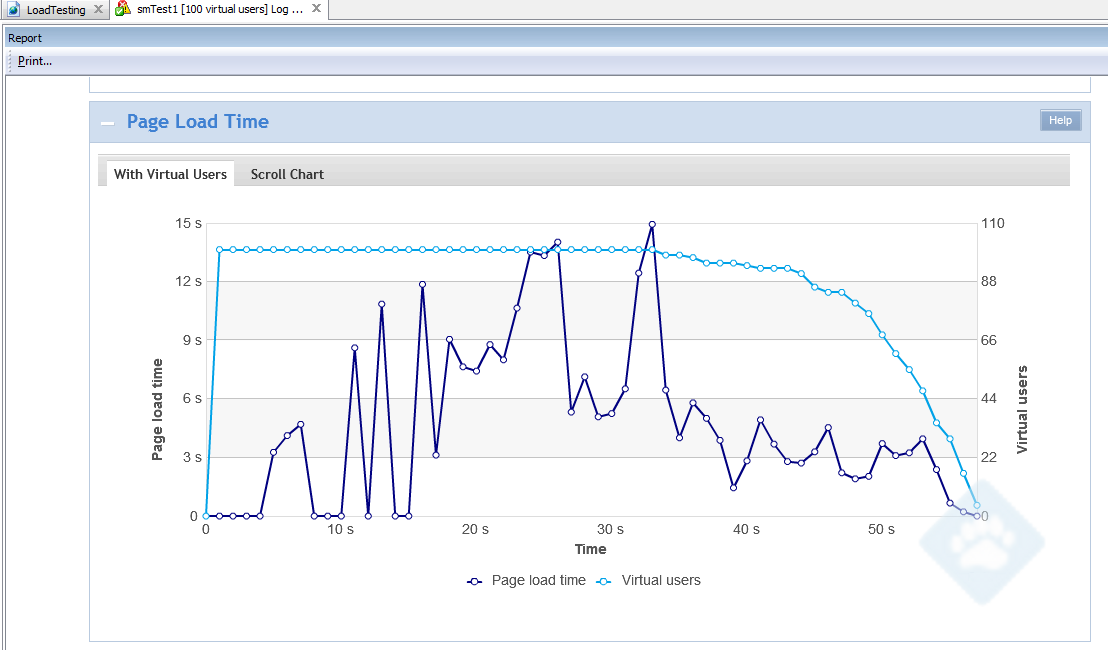
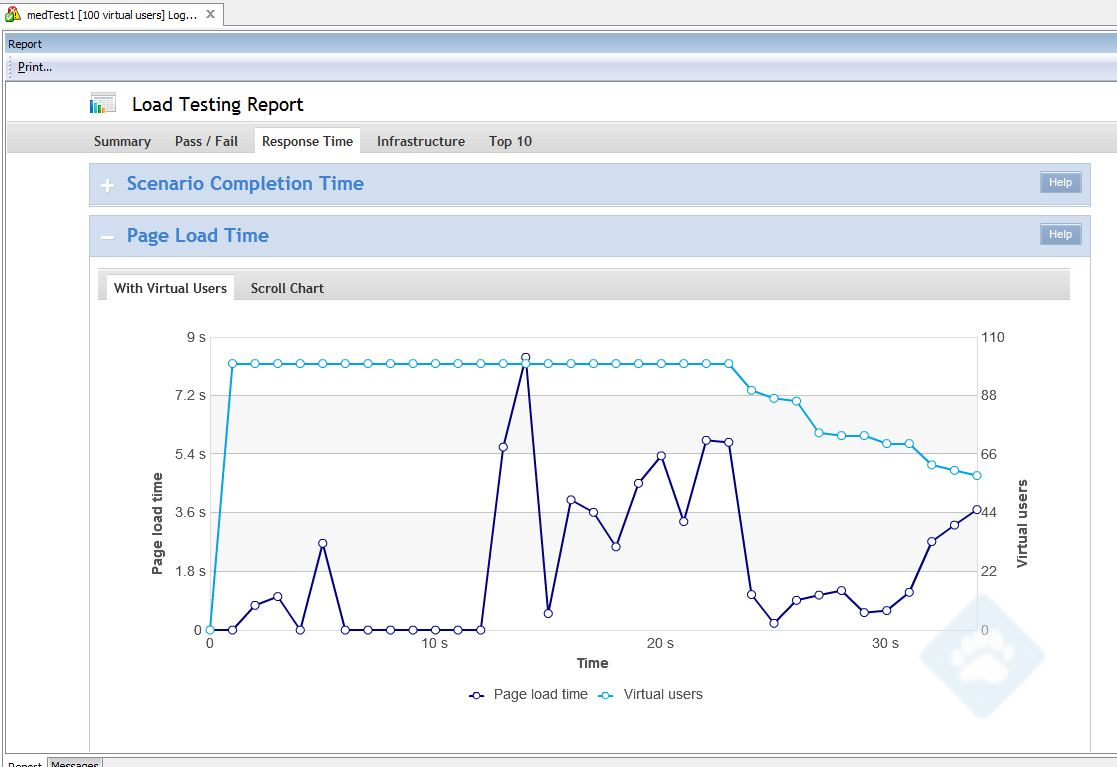
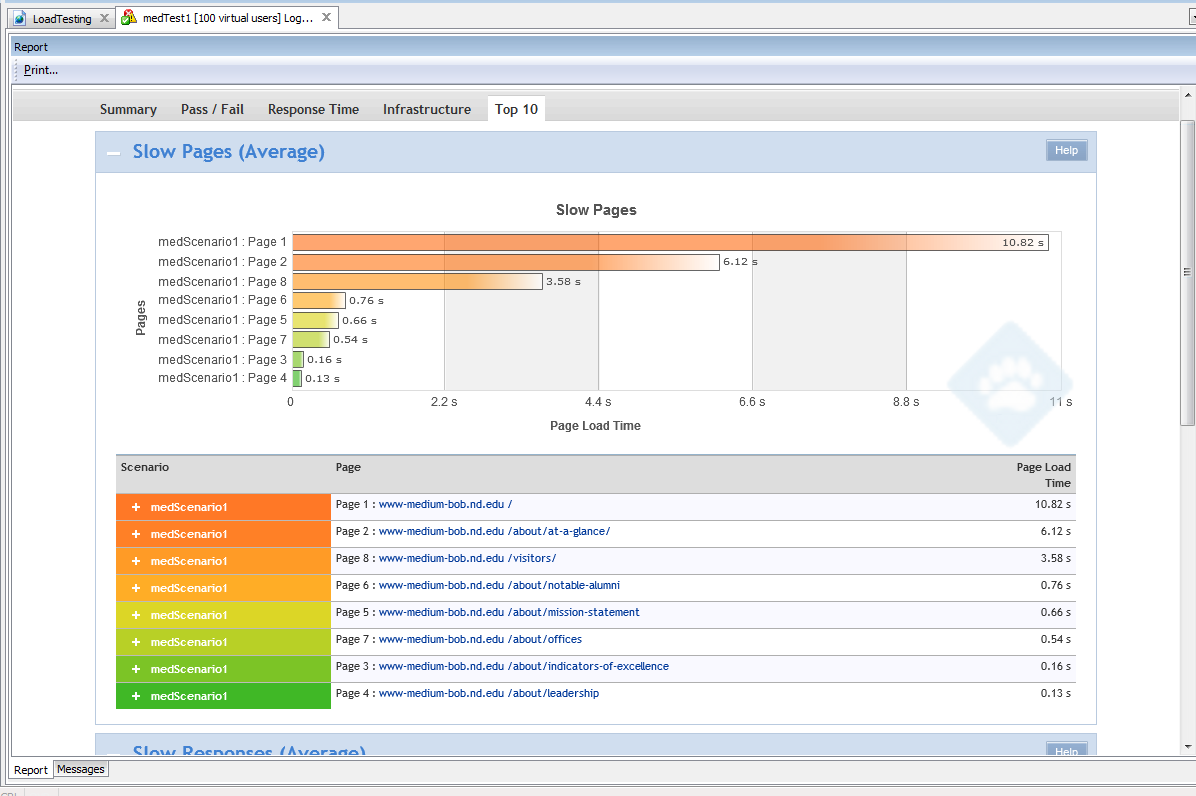
Last week, several new processes and technologies were asked to sink or swim as the OIT and the Office of the Registrar brought two new Ruby on Rails applications to production. I’m pleased to announce that due to a confluence of thorough planning, robust automatic deployment processes, and engaged collaboration across multiple OIT units, the apps are live and swimming, swimming, swimming.

What do we have now that we didn’t have before?
- two Rails apps in production
- a Banner API poised to serve as a key data integration point for the future
- an automated app deployment tool
- a new workflow that empowers developers and speeds app deployment
- puppet manifests to create consistency between developer VMs and deployment environments (satisfying point 10 of the Twelve-Factor App)
What else?
- the experience to extend API services to other data sources and consumers
- an architectural framework for future Rails app development
- a boatload of fresh Ruby on Rails knowledge
Automation + Collaboration = Innovation. Sound familiar? These new practices and processes are enhancing our agility, velocity, and ability to deliver quality functionality to users.
Big Thanks
I have often observed that some of the most fulfilling times working in the OIT are on outage weekends. Communication is quick and actions are decisive as disparate OIT teams come together, often in the same room, to bring new functionality to our campus constituents. That unity of purpose is the heart of DevOps, and I am pleased to say that I have seen it happen on a day-to-day basis recently. Let me highlight some of the people and teams who made this week a success, and who are laying the foundation for a bright future of ND application development.
Information Security
Jason Williams and his team were attentive and helpful in defining best practices for handling database and API credentials — something that is a little different in the new technology stack. Not only that, but when we needed Webinspect scans done or firewall rules put in place quickly, Jason’s team was ready to jump in and take action to help us go live.
Database Administration
Fred Nwangana‘s team was involved from early on, helping shape how Rails applications would work in our environment. Together we determined that this moment presents a great opportunity to decouple custom apps from the Banner database. Vincent Melody in particular was a great help in provisioning database resources and helping drive forward our process standardization.
Change Control
Julie Stogsdill and Matt Pollard‘s contributions have been tremendous. I came to them with Launchpad and a pretty clear agenda of putting TEST environment deployments in developers’ hands. Rather than objecting to this idea, they helped me find ways to integrate the process into our change control system. The new workflow is even more flexible than I had hoped, and has already allowed us to push important changes to production, via RFC, without a hint of dread that the process is too slow.
System Administration / Virtualization
I wrote puppet manifests to provision our servers, but I would have gotten nowhere in our local infrastructure without help from Chris Fruewirth‘s team. Milind Saraph and Joseph Franco, plus John Pozivilko from the virtualization team, were a great help in creating hosts in VMWare, assigning IPs, updating systems, and answering lots of questions when my limited sysadmin knowledge hit a wall. Plus, we are all going to be working toward increasing puppet infrastructure management in the future. Good stuff ahead there!
Just the Beginning
People used to ask me how the new job was going. There were so many things up in the air; how could I really give an answer? So I’d say something like “ask me in six months.” Well, now you can ask me any time, because the apps are live, the processes are working, and we are ready to take on new development challenges. There’s still more to tackle: expanding configuration management; exploring cloud infrastructure; implementing comprehensive monitoring. But for now, I want to pause and say “thank you” to everyone who helped get us to this point. Onward!