





Catholic Pamphlets and practice workflow
Posted on September 27, 2011 in UncategorizedThe Catholic Pamphlets Project has past its first milestone, specifically, practicing with its workflow which included digitizing and making accessible thirty-ish pamphlets in the Libraries’s catalog, “discovery system”, and implementing a text mining interface. This blog posting describes this success in greater detail.
For the past four months or so a growing number of us have been working on a thing affectionately called the Catholic Pamphlets Project. To one degree or another, these people have included:
Aaron Bales • Adam Heet • Denise Massa • Eileen Laskowski • Jean McManus • Julie Arnott • Lisa Stienbarger • Lou Jordan • Mark Dehmlow • Mary McKeown • Natalia Lyandres • Pat Lawton • Rejesh Balekai • Rick Johnson • Robert Fox • Sherri Jones
Our long-term goal is to digitize the set of 5,000 locally held Catholic pamphlets, save them in the library’s repository, update the catalog and “discovery system” (Primo) to include links to digital versions of the content, and provide rudimentary text mining services against the lot. The short-term goal is/was to apply these processes to 30 of the 5,000 pamphlets. And I am happy to say that as of Wednesday (September 21) we completed our short-term goal.
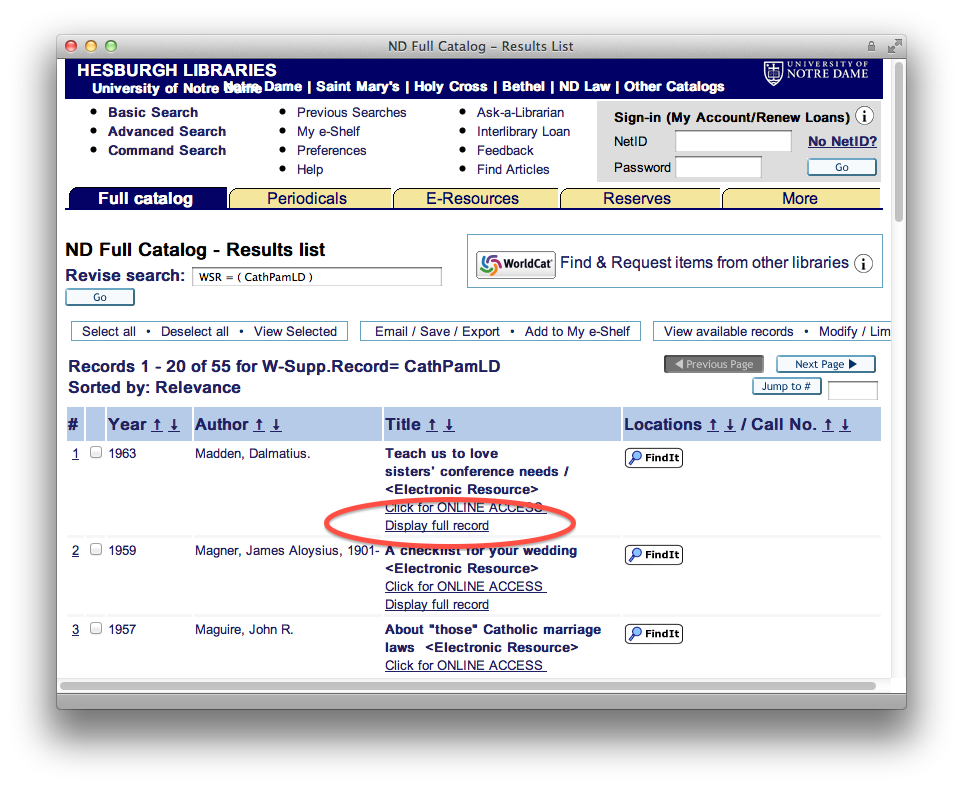
catalog display
The Hesburgh Libraries owns approximately 5,000 Catholic pamphlets — a set of physically smaller rather than larger publications dating from the early 1800s to the present day. All of these items are located in the Libraries’s Special Collection Department, and all of them have been individually cataloged.
As a part of a university (President’s Circle) grant, we endeavored to scan these documents, convert them into PDF files, save them to our institutional repository, enhance their bibliographic records, make them accessible through our catalog and “discovery system”, and provide text mining services against them. To date we have digitized just less than 400 pamphlets. Each page of each pamphlet has been scanned and saved as a TIFF file. The TIFF files were concatenated, converted into PDF files, and OCR’ed. The sum total of disk space consumed by this content is close to 92GB.
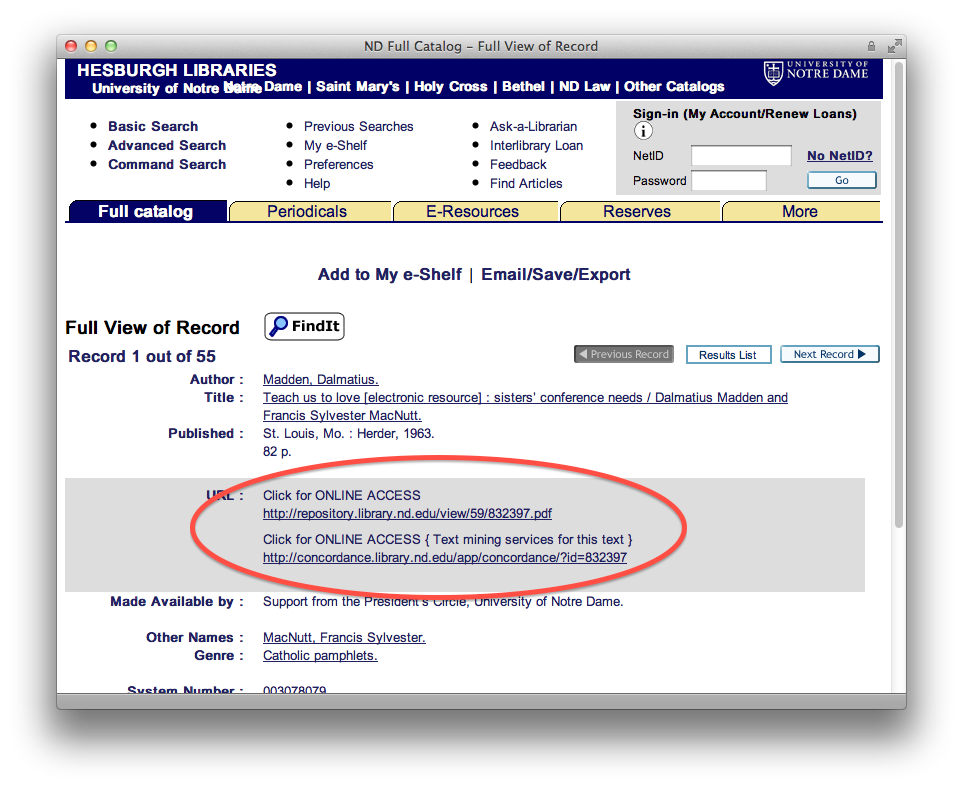
detail display
In order to practice with workflow, we selected about 30 of these pamphlets and enhanced their bibliographic records to denote their digital nature. These enhancements included URLs pointing to PDF versions of the pamphlets as well as URLs pointing to the text mining interfaces. When the enhancements were done we added them to the catalog. Once there they “flowed” to the “discovery system” (Primo). You can see these records from the following URL — http://bit.ly/qcnGNB. At the same time we extracted the plain text from the PDFs and made them accessible via a text mining interface allowing the reader to see what words/phrases are most commonly used in individual pamphlets. The text mining interface also includes a concordance — http://concordance.library.nd.edu/app/. These later services are implemented as a means of demonstrating how library catalogs can evolve from inventory lists to tools for use & understanding.
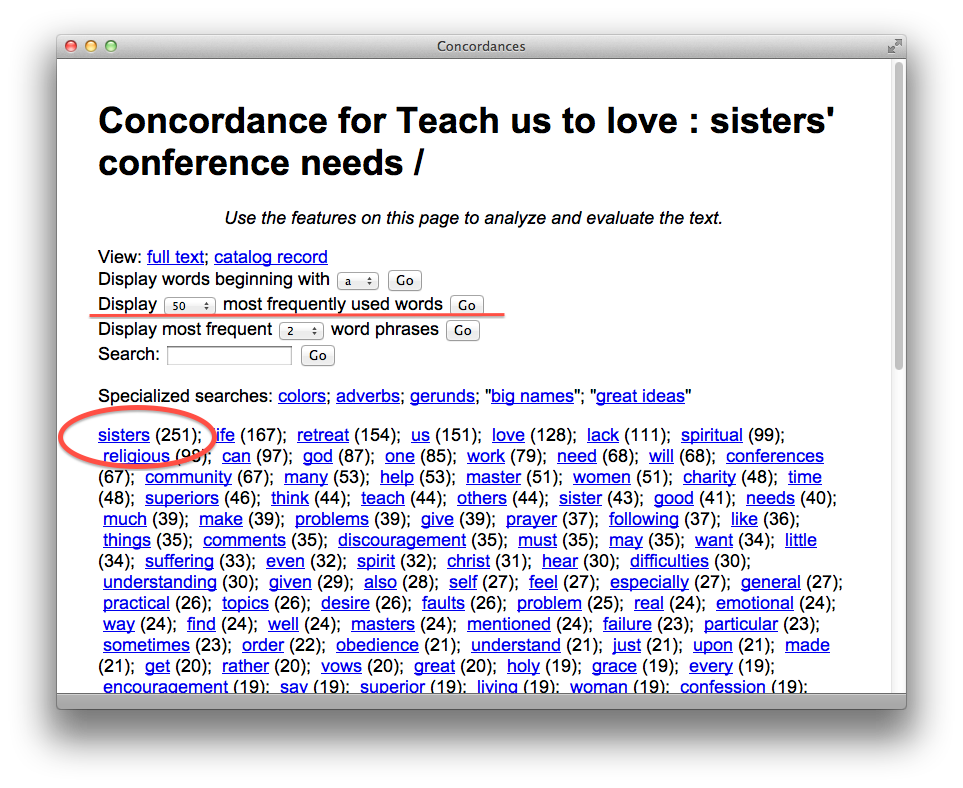
most frequently used words
While the practice may seem all but trivial, it required about three months of time. Between vacations, conferences, other priorities, and minor glitches the process took more time than originally planned. The biggest glitch was with Internet Explorer. We saved our PDF files in Fedora. Easy. Each PDF file had a URL coming from Fedora which we put into the cataloging records. But alas, Internet Explorer was not able to process the Fedora URLs because: 1) Fedora was not pointing to files but data streams, and/or 2) Fedora was not including an HTTP header called “filename disposition” which includes a file name extension. No other browsers we tested had these limitations. Consequently we (Rob Fox) wrote a bit of middleware taking a URL as input, getting the content from Fedora, and passing it back to the browser. Problem solved. This was a hack for sure. “Thank you, Rob!”
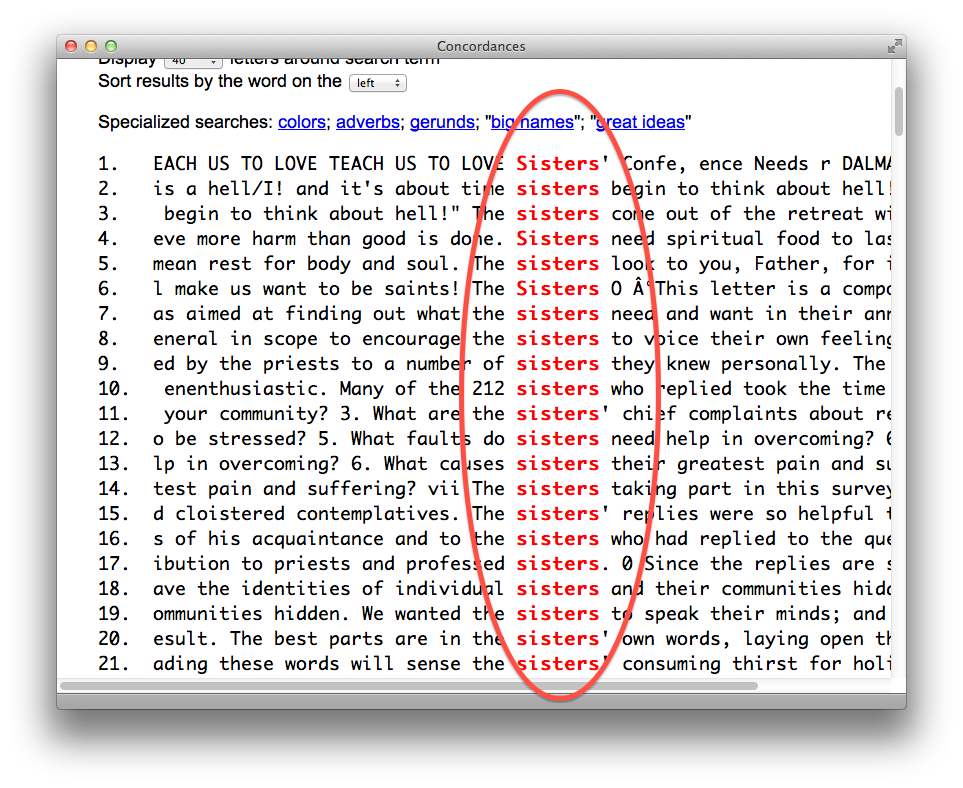
concordance display
We presently have no plans (resources) to digitize the balance of the pamphlets, but it is my personal hope we process (catalog, store, and make accessible via text mining) the remaining 325 pamphlets before Christmas. Wish us luck.