





Project English: An Index to English/American literature spanning six centuries
Posted on April 24, 2018 in Uncategorized by Eric Lease Morgan
I have commenced upon a project to build an index and set of accompanying services rooted in English/American literature spanning the 15th to 20th centuries. For the lack of a something better, I call it Project English. This blog posting describes Project English in greater detail.
Goals & scope
The goals of the Project include but are not limited to:
- provide enhanced collections & services to the University of Notre Dame community
- push the boundaries of librarianship
To accomplish these goals I have acquired a subset of three distinct and authoritative collections of English/American literature:
- EEBO – Early English Books Online which has its roots in venerable Short-Title Catalogue of English Books
- ECCO – Eighteenth Century Collection Online, which is an extension of the Catalogue
- Sabin – Bibliotheca Americana: A Dictionary of Books Relating to America from Its Discovery to the Present Time originated by Joseph Sabin
More specifically, the retired and emeritus English Studies Librarian, Laura Fuderer purchased hard drives containing the full text of the aforementioned collections. Each item in the collection is manifested as an XML file and a set of JPEG images (digital scans of the original materials). The author identified the hard drives, copied some of the XML files, and began the Project. To date, the collection includes:
- 56 thousand titles
- 7.6 million pages
- 2.3 billion words
At the present time, the whole thing consumes 184 GB of disk space where approximately 1/3 of it is XML files, 1/3 of it is HTML files transformed from the XML, and 1/3 is plain text files transformed from the XML. At the present time, there are no image nor PDF files in the collection.
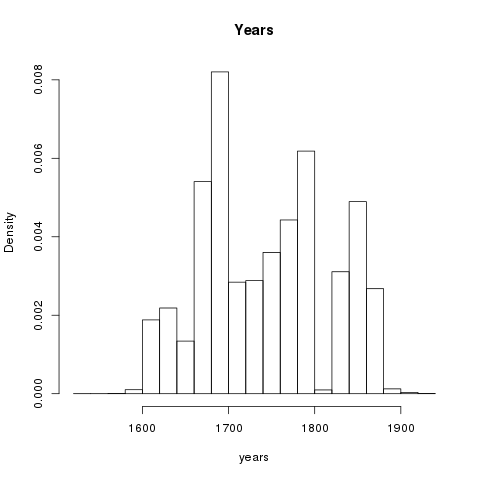
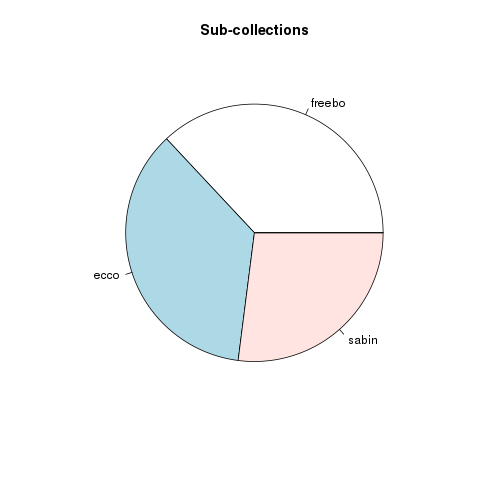
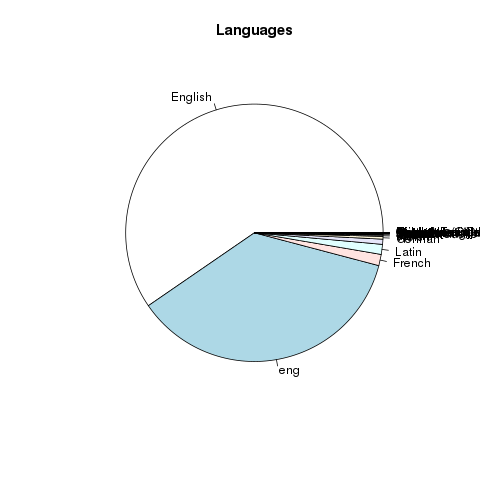
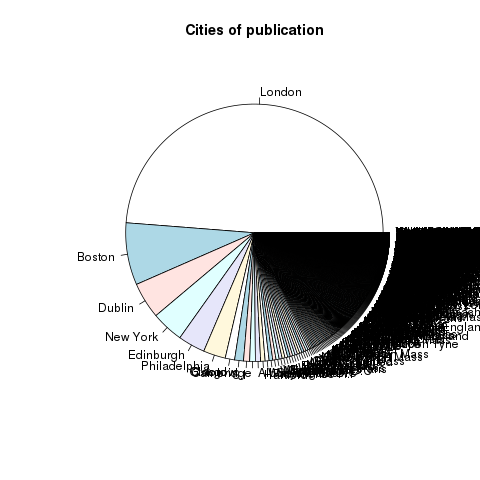
On average, each item in the collection is approximately 135 pages (or 46,000 words) long. As of right now, each sub-collection is equally represented. The vast majority of the collection is in English, but other languages are included. Most of the content was published in London. The distribution of centuries is beginning to appear balanced, but determining the century of publication is complicated by the fact the metadata’s date values are not expressed as integers. The following charts & graphs illustrate all of these facts.
 |
 |
 |
 |
Access & services
By default, the collection is accessible via freetext/fielded/faceted searching. Given an EBBO, ECCO, or Sabin identifier, the collection is also accessible via known-item browse. (Think “call number”.) Search results can optionally be viewed and sorted using a tabled interface. (Think “spreadsheet”.) The reader has full access to:
- the original XML data – hard to read but rich in metadata
- rudimentary HTML – transformed from the original XML and a bit easier to read
- plain text – intended for computational analysis
Search results and its associated metadata can also be downloaded en masse. This enables the reader to do offline analysis such as text mining, concordancing, parts-of-speech extraction, or topic modeling. Some of these things are currently implemented inline, including:
- listing the frequency of unigrams, bigrams, and trigrams
- listing the frequency of noun phrases, the subjects & objects of sentences
For example, the reader can first create a set of one or more items of interest. They can then do some “distant” or “scalable” reading against the result. In its current state, Project English enables the reader to answer questions like:
- What is this particular item about?
- To what degree does this item mention the words God, man, truth, or beauty?
As Project English matures, it will enable the reader to answer additional questions, such as:
- What actions take place in a given corpus?
- How are things described?
- If one were to divide the collection into T themes, then what might those themes be?
- How has a theme changed over time?
- Who, what places, and what organizations appear in the corpus?
- What ideas appear concurrently in a corpus?
Librarianship
Remember, one of the goals of the Project is to push the boundaries of librarianship. With the advent of ubiquitous networked computers, the traditional roles of librarianship are not as important as they previously were. (I did not say the roles were unimportant, just not as important as they used to be.) Put another way, there is less of a need for the collection, organization, preservation, and dissemination of data, information, and knowledge. Much of this work is being facilitated through the Internet. This then begs the question, “Given the current environment, what are or can be the roles of (academic) libraries?” In the author’s opinion, the roles are rooted in two activities:
- the curation of rare & infrequently held materials
- the provision of value-added services against those materials
In the case of Project English, the rare & infrequently held materials are full text items dating from 15th to 20th centuries. When it is all said & done, the collection may come close to 2.5 million titles in size, a modest library by most people’s standards. These collections are being curated with scope, with metadata, with preservation, and with quick & easy access. The value-added services are fledgling, but they will include a sets of text mining & natural langage processing interfaces enabling the learner, teacher, and scholar to do “distant” and “scalable” reading. In other words, instead of providing access to materials and calling the work of librarianship done, Project English will enable & empower the reader to use & understand the materials they have acquired.
Librarianship needs to go beyond the automation of traditional tasks; it behooves librarianship to exploit computers to a greater degree and use them to augment & supplement the profession’s reason and experience. Project English is one librarian’s attempt to manifest this idea into a reality.