





Analyzing search results using JSTOR’s Data For Research
Posted on February 17, 2014 in Uncategorized by Eric Lease Morgan
Introduction
Data For Research (DFR) is an alternative interface to JSTOR enabling the reader to download statistical information describing JSTOR search results. For example, using DFR a person can create a graph illustrating when sets of citations where written, create a word cloud illustrating the most frequently used words in a journal article, or classify sets of JSTOR articles according to a set of broad subject headings. More advanced features enable the reader to extract frequently used phrases in a text as well as list statistically significant keywords. JSTOR’s DFR is a powerful tool enabling the reader to look for trends in large sets of articles as well as drill down into the specifics of individual articles. This hands-on workshop leads the student through a set of exercises demonstrating these techniques.
Faceted searching
DFR supports an easy-to-use search interface. Enter one or two words into the search box and submit your query. Alternatively you can do some field searching using the advanced search options. The search results are then displayed and sortable by date, relevance, or a citation rank. More importantly, facets are displayed along side the search results, and searches can be limited by selecting one or more of the facet terms. Limiting by years, language, subjects, and disciplines prove to be the most useful.
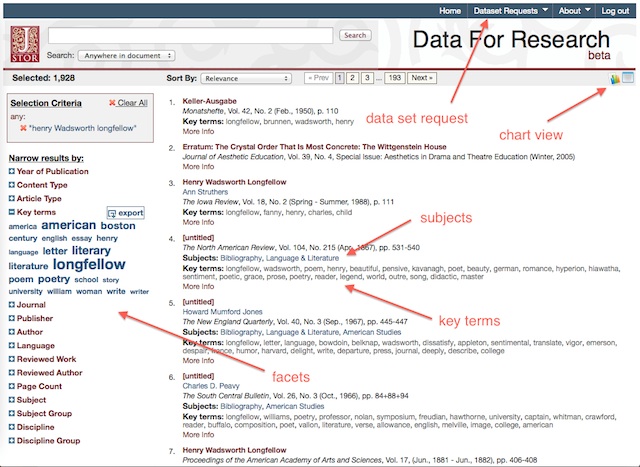
search results screen
Publication trends over time
By downloading the number of citations from multiple search results, it is possible to illustrate publication trends over time.
In the upper right-hand corner of every search result is a “charts view” link. Once selected it will display a line graph illustrating the number of citations fitting your query over time. It also displays a bar chart illustrating the broad subject areas of your search results. Just as importantly, there is a link at the bottom of the page — “Download data for year chart” — allowing you to download a comma-separated (CSV) file of publication counts and years. This file is easily importable into your favorite spreadsheet program and chartable. If you do multiple searches and download multiple CSV files, then you can compare publication trends. For example, the following chart compares the number of times the phrases “Henry Wadsworth Longfellow”, “Henry David Thoreau”, and “Ralph Waldo Emerson” have appeared in the JSTOR literature between 1950 and 2000. From the chart we can see that Emerson was consistently mentioned more of than both Longfellow and Thoreau. It would be interesting to compare the JSTOR results with the results from Google Books Ngram Viewer, which offers a similar service against their collection of digitized books.
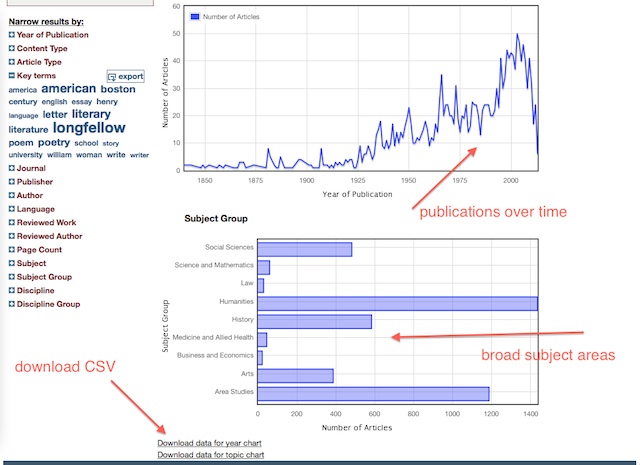
chart view screen shot
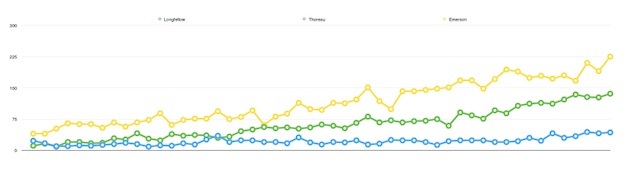
publications trends for Emerson, Thoreau, and Longfellow
Key word analysis
DFR counts and tabulates frequently used words and statistically significant key words. These tabulations can be used to illustrate characteristics of search results.
Each search result item comes complete with title, author, citation, subject, and key terms information. The subjects and key terms are computed values — words and phrases determined by frequency and statistical analysis. Each search result item comes with a “More Info” link which returns lists of the item’s most frequently used words, phrases, and keyword terms. Unfortunately, these lists often include stop words like “the”, “of”, “that”, etc. making the results not as meaningful as they could be. Still, these lists are somewhat informative. They allude to the “aboutness” of the selected article.
Key terms are also facets. You can expand the Key terms facets to get a small word cloud illustrating the frequency of each term across the entire search result. Clicking on one of the key terms limits the search results accordingly. You can also click on the Export button to download a CVS file of key terms and their frequency. This information can then be fed to any number of applications for creating word clouds. For example, download the CSV file. Use your text editor to open the CSV file, and find/replace the commas with colons. Copy the entire result, and paste it into Wordle’s advanced interface. This process can be done multiple times for different searches, and the results can be compared & contrasted. Word clouds for Longfellow, Thoreau, and Emerson are depicted below, and from the results you can quickly see both similarities and differences between each writer.

Ralph Waldo Emerson key terms

Henry David Thoreau key terms

Henry Wadsworth Longfellow key terms
Downloading complete data sets
If you create a DFR account, and if you limit your search results to 1,000 items or less, then you can download a data set describing your search results.
In the upper right-hand corner of the search results screen is a pull-down menu option for submitting data set requests. The resulting screen presents you with options for downloading a number of different types of data (citations, word counts, phrases, and key terms) in two different formats (CSV and XML). The CSV format is inherently easier to use, but the XML format seems to be more complete, especially when it comes to citation information. After submitting your data set request you will have to wait for an email message from DFR because it takes a while (anywhere from a few minutes to a couple of hours) for it to be compiled.
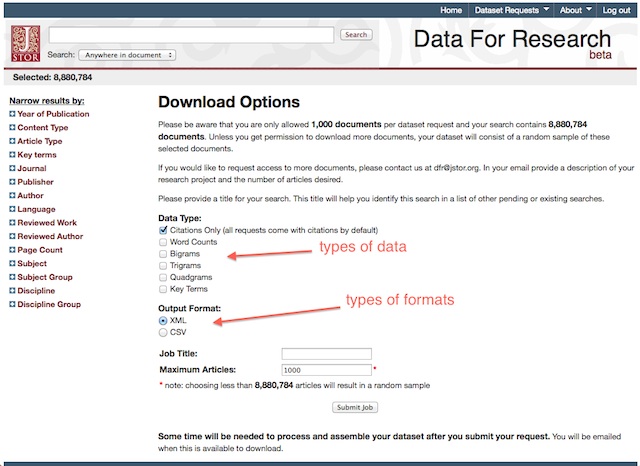
data set request page
After downloading a data set you can do additional analysis against it. For example, it is possible to create a timeline illustrating when individual articles where written. It is not be too difficult to create word clouds from titles or author names. If you have programming experience, then you might be be able to track ideas over time or the originator of specific ideas. Concordances — keyword in context search engines — can be implemented. Some of this functionality, but certainly not all, is being slowly implemented in a Web-based application called JSTOR Tool.
Summary
As the written word is increasingly manifested in digital form, so does the ability to evaluate the written word quantifiably. JSTOR’s DFR is one example of how this can be exploited for the purposes of academic research.
Note
A .zip file containing some sample data and well as the briefest of instructions on how to use it is linked from this document.