





Project Gutenberg and the Distant Reader
Posted on November 6, 2019 in Distant Reader by Eric Lease Morgan
The venerable Project Gutenberg is perfect fodder for the Distant Reader, and this essay outlines how & why. (tl;dnr: Search my mirror of Project Gutenberg, save the result as a list of URLs, and feed them to the Distant Reader.)
Project Gutenberg

Wall Paper by Eric
To date, Project Gutenberg is a corpus of more than 60,000 freely available transcribed ebooks. The texts are predominantly in English, but many languages are represented. Many academics look down on Project Gutenberg, probably because it is not as scholarly as they desire, or maybe because the provenance of the materials is in dispute. Despite these things, Project Gutenberg is a wonderful resource, especially for high school students, college students, or life-long learners. Moreover, its transcribed nature eliminates any problems of optical character recognition, such as one encounters with the HathiTrust. The content of Project Gutenberg is all but perfectly formatted for distant reading.
Unfortunately, the interface to Project Gutenberg is less than desirable; the index to Project Gutenberg is limited to author, title, and “category” values. The interface does not support free text searching, and there is limited support for fielded searching and Boolean logic. Similarly, the search results are not very interactive nor faceted. Nor is there any application programmer interface to the index. With so much “clean” data, so much more could be implemented. In order to demonstrate the power of distant reading, I endeavored to create a mirror of Project Gutenberg while enhancing the user interface.
To create a mirror of Project Gutenberg, I first downloaded a set of RDF files describing the collection. [2] I then wrote a suite of software which parses the RDF, updates a database of desired content, loops through the database, caches the content locally, indexes it, and provides a search interface to the index. [3, 4] The resulting interface is ill-documented but 100% functional. It supports free text searching, phrase searching, fielded searching (author, title, subject, classification code, language) and Boolean logic (using AND, OR, or NOT). Search results are faceted enabling the reader to refine their query sans a complicated query syntax. Because the cached content includes only English language materials, the index is only 33,000 items in size.
Project Gutenberg & the Distant Reader
The Distant Reader is a tool for reading. It takes an arbitrary amount of unstructured data (text) as input, and it outputs sets of structured data for analysis — reading. Given a corpus of any size, the Distant Reader will analyze the corpus, and it will output a myriad of reports enabling you to use & understand the corpus. The Distant Reader is intended to supplement the traditional reading process. Project Gutenberg and the Distant Reader can be used hand-in-hand.
As described in a previous posting, the Distant Reader can take five different types of input. [5] One of those inputs is a file where each line in the file is a URL. My locally implemented mirror of Project Gutenberg enables the reader to search & browse in a manner similar to the canonical version of Project Gutenberg, but with two exceptions. First & foremost, once a search has been gone against my mirror, one of the resulting links is “only local URLs”. For example, below is an illustration of the query “love AND honor AND truth AND justice AND beauty”, and the “only local URLs” link is highlighted:
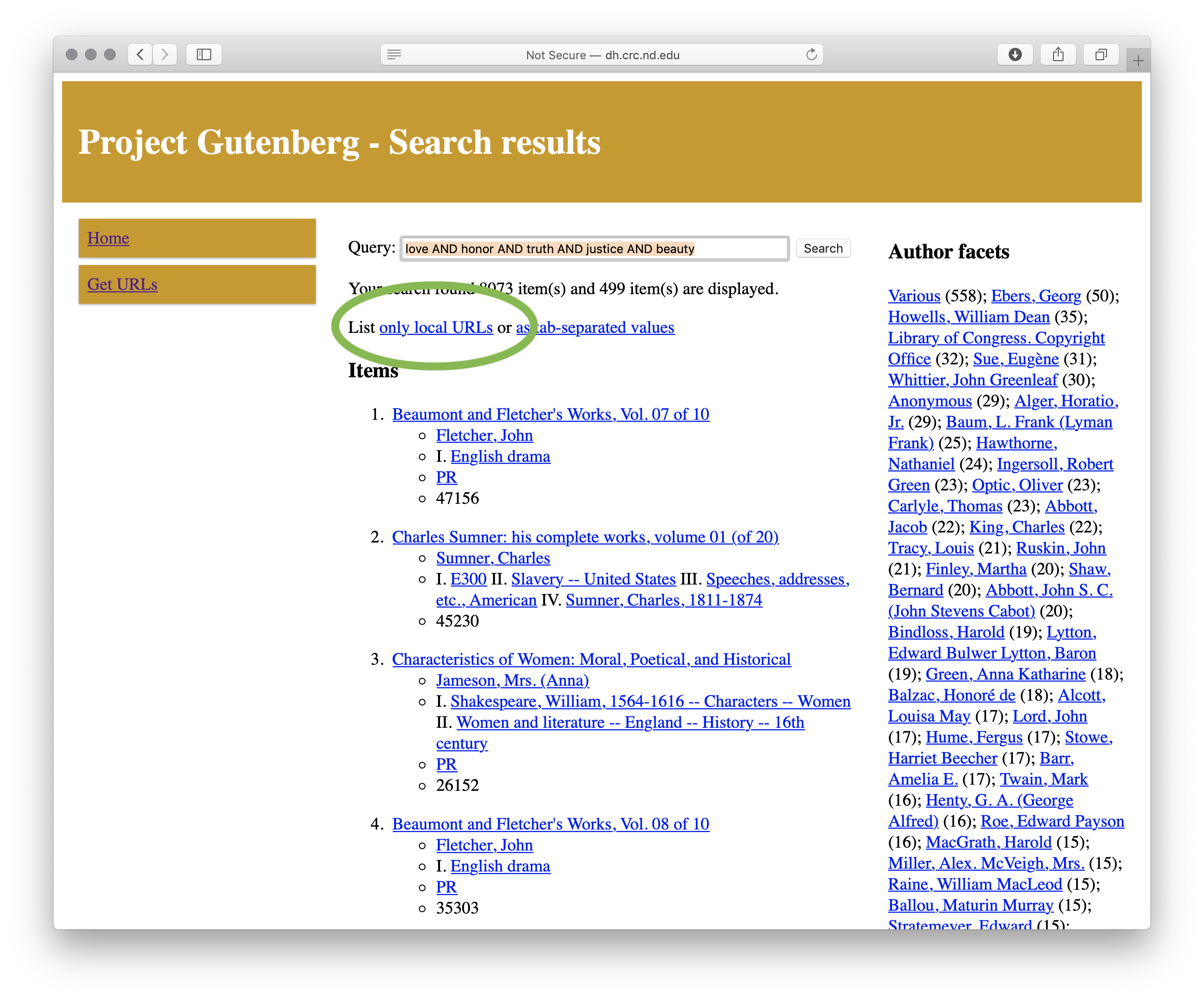
Search result
By selecting the “only local URLs”, a list of… URLs is returned, like this:
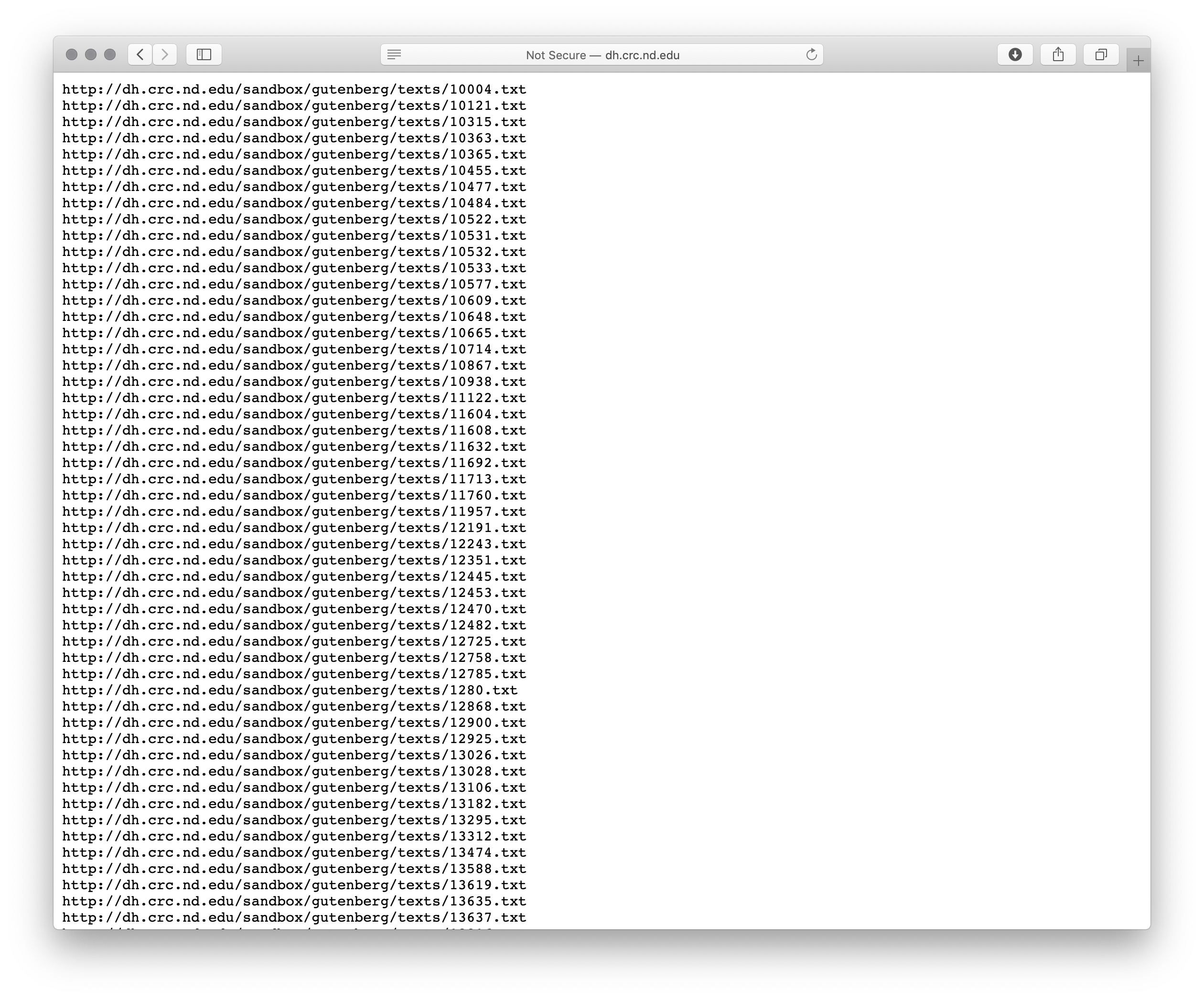
URLs
This list of URLs can then be saved as file, and any number of things can be done with the file. For example, there are Google Chrome extensions for the purposes of mass downloading. The file of URLs can be fed to command-line utilities (ie. curl or wget) also for the purposes of mass downloading. In fact, assuming the file of URLs is named love.txt, the following command will download the files in parallel and really fast:
cat love.txt | parallel wget
This same file of URLs can be used as input against the Distant Reader, and the result will be a “study carrel” where the whole corpus could be analyzed — read. For example, the Reader will extract all the nouns, verbs, and adjectives from the corpus. Thus you will be able to answer what and how questions. It will pull out named entities and enable you to answer who and where questions. The Reader will extract keywords and themes from the corpus, thus outlining the aboutness of your corpus. From the results of the Reader you will be set up for concordancing and machine learning (such as topic modeling or classification) thus enabling you to search for more narrow topics or “find more like this one”. The search for love, etc returned more than 8000 items. Just less than 500 of them were returned in the search result, and the Reader empowers you to read all 500 of them at one go.
Summary
Project Gutenberg is very useful resource because the content is: 1) free, and 2) transcribed. Mirroring Project Gutenberg is not difficult, and by doing so an interface to it can be enhanced. Project Gutenberg items are perfect items for reading & analysis by the Distant Reader. Search Project Gutenberg, save the results as a file, feed the file to the Reader and… read the results at scale.
Notes and links
† All puns are intended.
[1] Michael Hart in Roanoke (Indiana) – video: https://youtu.be/eeoBbSN9Esg; blog posting: http://infomotions.com/blog/2010/03/michael-hart-in-roanoke-indiana/
[2] The various Project Gutenberg feeds, including the RDF is located at https://www.gutenberg.org/wiki/Gutenberg:Feeds
[3] The suite of software to cache and index Project Gutenberg is available on GitHub at https://github.com/ericleasemorgan/gutenberg-index
[4] My full text index to the English language texts in Project Gutenberg is available at http://dh.crc.nd.edu/sandbox/gutenberg/cgi-bin/search.cgi
[5] The Distant Reader and its five different types of input – http://sites.nd.edu/emorgan/2019/10/dr-inputs/