





Issues in Science and Technology Librarianship
Posted on April 1, 2022 in Distant ReaderI asked a colleague (Parker Ladwig) if there was a blog he thought might be worthy of archiving, and he mentioned Issues in Science and Technology Librarianship (ISTL). I took it upon myself to see what I could do.
After looking more closely at the site, I guessed the underlying technology was not blog technology but rooted in the venerable OJS journal publishing system, and OJS robustly supports a protocol called OAI-PMH. Luckily I had previously written a suite of software used to harvest all the bibliographic information and content from (OJS) OAI-PHM sites. Consequently, in a matter of about 30 minutes, I was able to create a CSV file listing all the articles along with their authors, titles, abstracts, URLs, etc.
I then ran a program that looped through the CSV file and downloaded (cached) the content. Thus, all the articles in their original form are found in the (temporarily) linked .zip file. There are about 900 of them.
I then ran the whole thing through my Distant Reader Toolbox, and I am now able to characterize the journal as a whole. For example, after removing bogus files, there are about 850 articles, and the whole corpus is 2.5 million words long. (The Bible is about .8 million words long.) I was then able to create a rudimentary bibliography, which is really only half a step better than the original CSV file.
Do you know what ISTL is about? Science and technology librarianship would be a good guess, but can you elaborate? I can, in a number of ways. For example, if I compute statistically significant keywords against the text, I can visualize the result as a word cloud. Now you know more, and in what proportions.

Rudimentary clustering of the data returns two possible themes, but the clustering process (Principle Component Analysis) does not articulate what those themes may be. Still, such an analysis points to what a good topic model might be.
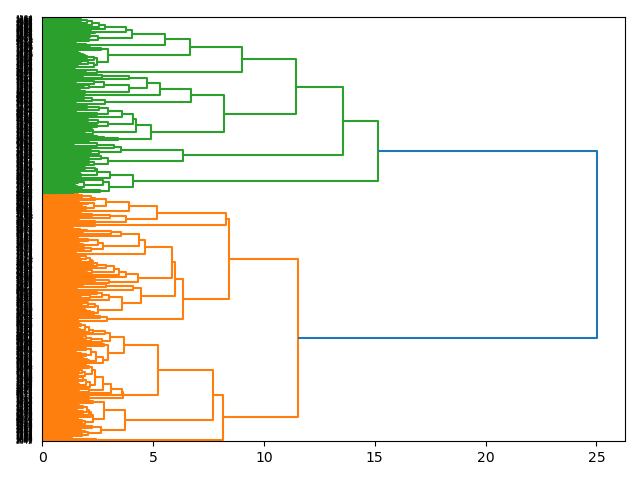
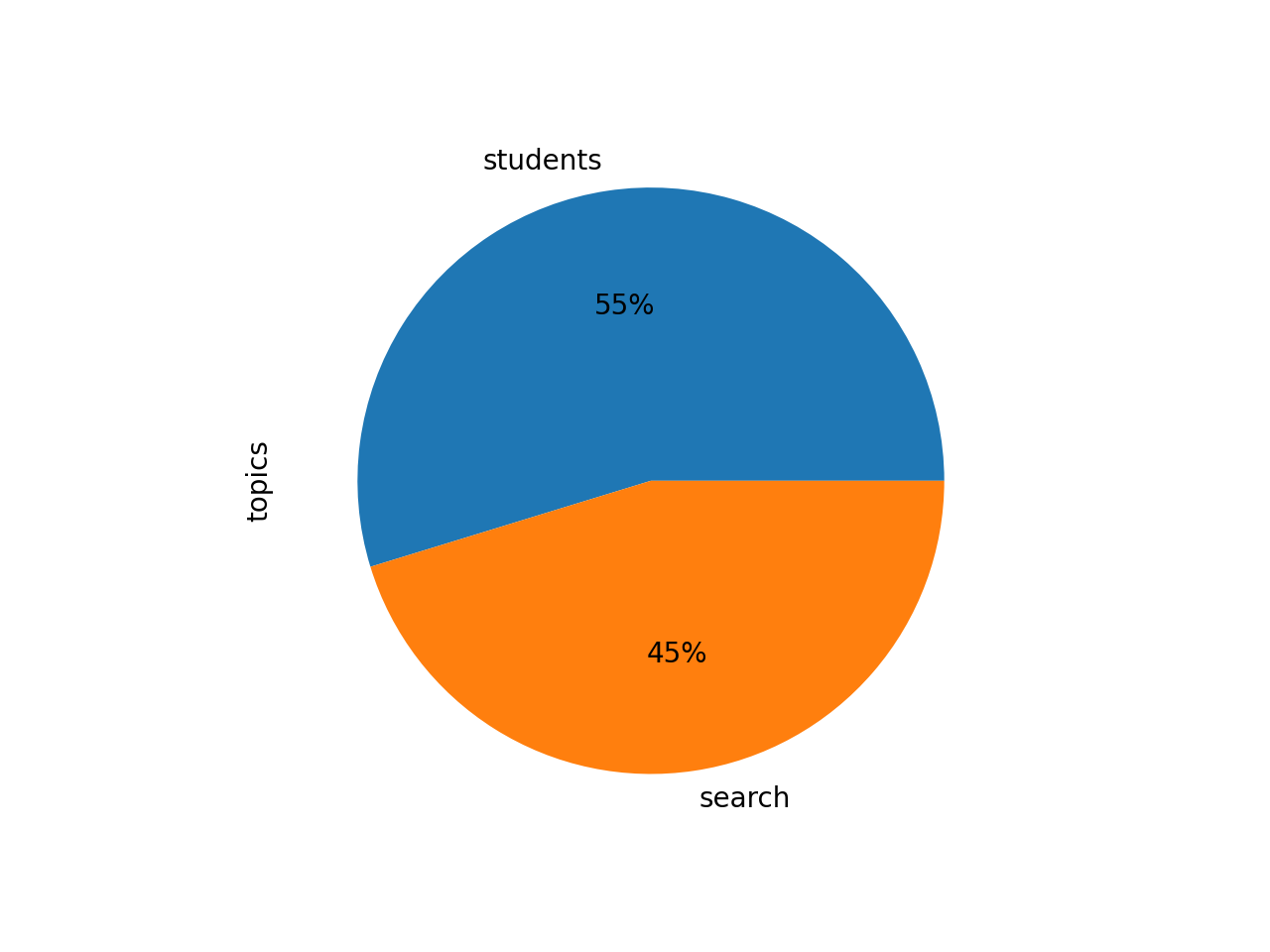
Topic modeling with only two topics, returns two possible, over-arching themes: 1) students, and 2) search. Notice how the students theme is really about people, and the search theme seems to be about searching stuff:
topic weights features
students 0.54019 students data research librarians faculty univ...
search 0.44664 search journals web access research articles d...
In terms of proportions, the pie chart of the weights mirrors the clustering analysis.
After a bit more modeling, the idea of search is still evident, but the theme of students has broken down into different types of people and different things being searched:
topic weights features
use 0.34272 use faculty survey services new staff university
search 0.33438 search web database users results databases also
book 0.27892 book technology work new internet example many
librarians 0.25108 librarians research technology university educ...
access 0.20613 access journals electronic open research publi...
citation 0.19648 citation study journals research analysis arti...
students 0.17608 students literacy research instruction course ...
food 0.10850 food site resources environmental research agr...
data 0.10367 data research management researchers gis servi...
site 0.09101 site resources links web provides history rese...
patent 0.06577 patent yes patents titles databases journals d...
chemistry 0.05041 chemistry chemical structure molecular data bi...
Again, a pie chart of the whole.
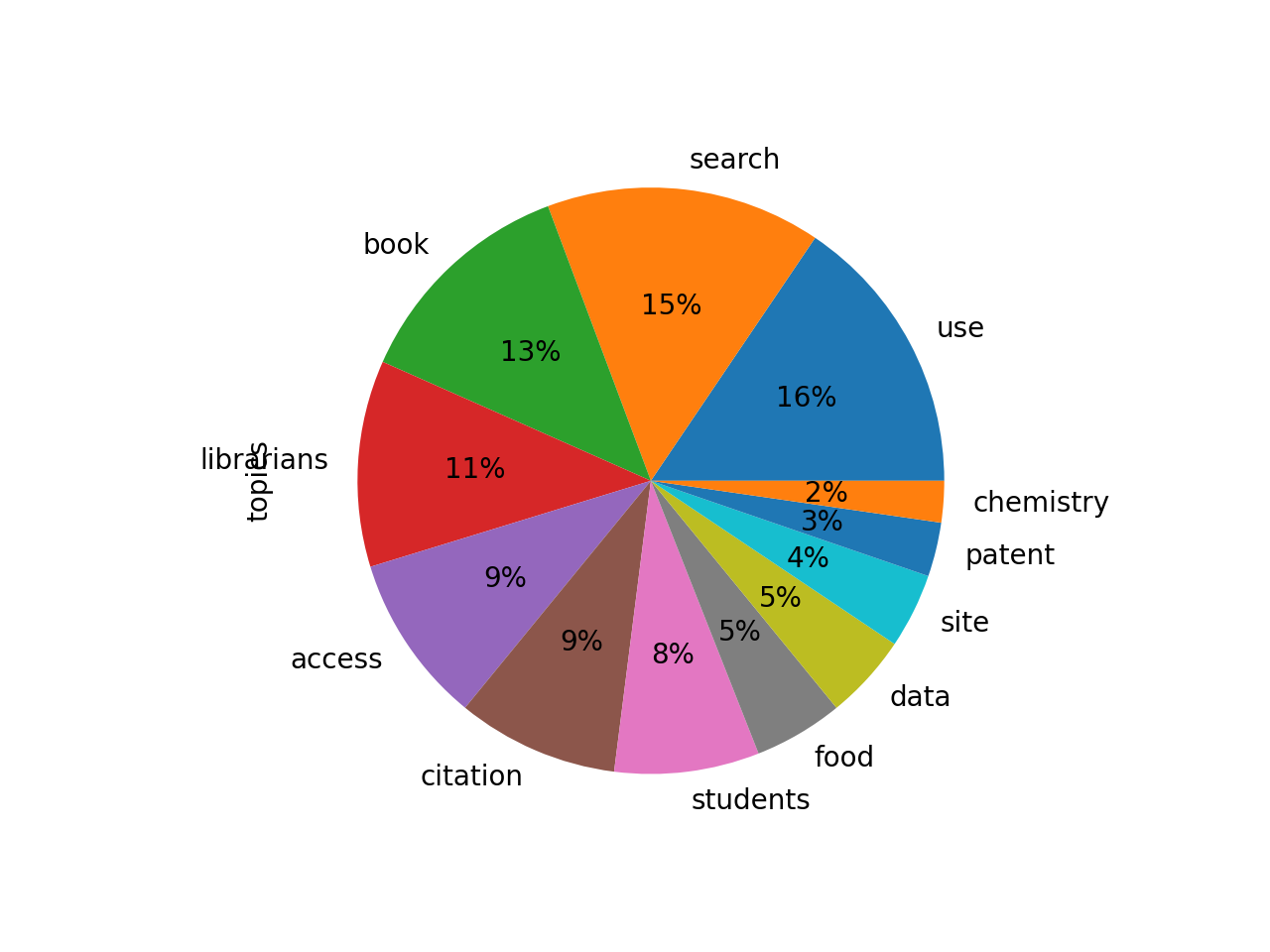
One of our esteemed colleagues — Roy Tennant — once said, “Librarians like to search. Everybody else likes to find.” Consequently, I was not surprised to see search as a theme in a library-related journal.

Upon closer inspection of the keywords, the word soil piqued my interest, so I created a full text index and searched for “title:soil OR keyword:soil”. I got three records:
Your search (title:soil OR keyword:soil) against the study carrel named
"istl" returned 3 record(s):
id: 2495
author: Pellack, Lorraine J.
title: Soil Surveys — They're Not Just for Farmers.
date: 2009-09-01
summary: Soil surveys do contain inventories of the soils of an area;
however, they also contain a wealth of tabular data that help interpret
whether a location is suitable for a given use, such as a playground, a
golf course, or a highway. This guide will describe soil surveys, their
uses, and uniqueness.
keyword(s): library; soil; surveys; u.s
words: 3003
sentence: 151
flesch: 59
cache: /Users/eric/Documents/reader-library/istl/cache/2495.htm
txt: /Users/eric/Documents/reader-library/istl/txt/2495.txt
id: 2420
author: Bracke, Marianne Stowell
title: Agronomy: Selected Resources
date: 2007-07-01
summary: This web bibliography, or webliography, contains links and
descriptions of agronomy web sites that cover general and background
information, crop science, soil science, resources for K-12 teachers,
databases, freely-available and subscription-based journals, and
organizations. Only a select number of sites that focused on crop
science, soil science, or a particular sub-area (e.g., corn) were
included due to the large number of sites in existence.
keyword(s): agronomy; crop; information; plant; science; site; soil
words: 5135
sentence: 265
flesch: 39
cache: /Users/eric/Documents/reader-library/istl/cache/2420.htm
txt: /Users/eric/Documents/reader-library/istl/txt/2420.txt
id: 1984
author: Harnly, Caroline D.
title: Sustainable Agriculture and Sustainable Forestry: A
Bibliographic Essay: Theme: All Topics
date: 2004-08-14
summary: The authors found that there is no clear preference in
the marketplace to the many approaches to achieving sustainable forest
management. Peter F. Ffolliott, et al.'s book, Dryland Forestry,
details how to manage both the biophysical and socioeconomic aspects
of environmentally sound, sustainable forest management in dryland
environments.
keyword(s): agricultural; book; edited; farming; food; forest; forest
management; management; new; papers; press; soil; sustainability;
sustainable; sustainable agriculture; sustainable forestry; systems; topics
words: 14403
sentence: 990
flesch: 43
cache: /Users/eric/Documents/reader-library/istl/cache/1984.htm
txt: /Users/eric/Documents/reader-library/istl/txt/1984.txt
Well, that’s enough for now, but the point is this:
As librarians we collect, organize, preserve, and disseminate data, information, and knowledge. These are the whats of librarianship, and they change very slowly. On the other hand, the hows of librarianship — card catalogs versus OPAC, MARC versus linked data, licensing versus purchasing, reference desking versus zooming, just-in-time collection versus just-in-case collection, etc. — change much faster with changes in the political environment and technology. Harvesting things from the Web and adding value to the resulting collection may be things we ought to do more actively. The things outlined above are possible examples.
Fun with librarianship?
P.S. Ironically, I just noticed the linked blog posting about Web archiving. From the concluding paragraph:
There is clearly value in identifying the parts of “the Web” that aren’t being collected, preserved, and disseminated to scholars. But in an era when real resources are limited, and likely shrinking, proposals to address these deficiencies need to be realistic about what can be achieved with the available resources. They should be specific about what current tasks should be eliminated to free up resources for these additional efforts, or the sources of (sustainable, not one-off) additional funding for them.
Food for thought.

 Over the past few years, I have written a number of blog postings which describe a thing called the
Over the past few years, I have written a number of blog postings which describe a thing called the This tiny blog posting outlines a sort of recipe for the use of text mining to address research questions. Through the use of this process the student, researcher, or scholar can easily supplement the traditional reading process.
This tiny blog posting outlines a sort of recipe for the use of text mining to address research questions. Through the use of this process the student, researcher, or scholar can easily supplement the traditional reading process. The Distant Reader Toolbox is a command-line tool for interacting with data sets created by the Distant Reader — data sets affectionally called “study carrels”. See:
The Distant Reader Toolbox is a command-line tool for interacting with data sets created by the Distant Reader — data sets affectionally called “study carrels”. See: The venerable
The venerable 

 [The following missive was written via an email message to a former colleague, and it is a gentle introduction to Distant Reader “study carrels”. –ELM]
[The following missive was written via an email message to a former colleague, and it is a gentle introduction to Distant Reader “study carrels”. –ELM]