





CrossRef’s Prospect API
Posted on February 17, 2014 in Uncategorized by Eric Lease Morgan
This is the tiniest of blog postings outlining my experiences with a fledgling API called Prospect.
Prospect is an API being developed by CrossRef. I learned about it through both word-of-mouth as well as a blog posting by Eileen Clancy called “Easy access to data for text mining“. In a nutshell, given a CrossRef DOI via content negotiation, the API will return both the DOI’s bibliographic information as well as URL(s) pointing to the location of full text instances of the article. The purpose of the API is to provide a straight-forward method for acquiring full text content without the need for screen scraping.
I wrote a simple, almost brain-deal Perl subroutine implementing the API. For a good time, I put the subroutine into action in a CGI script. Enter a simple query, and the script will search CrossRef for full text articles, and return a list of no more than five (5) titles and their associated URL’s where you can get them in a number of formats.
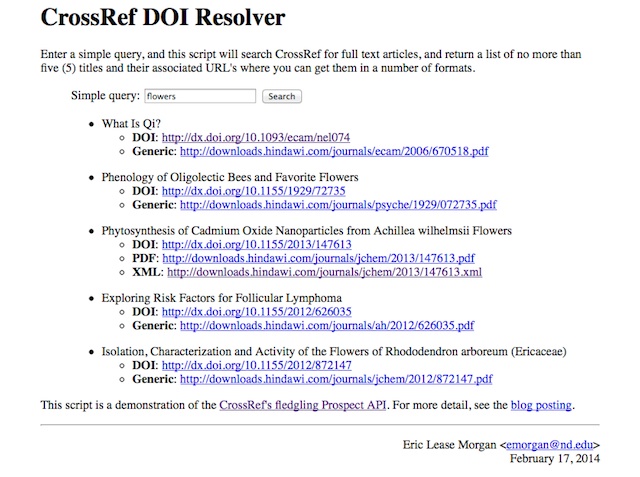
screen shot of CrossRef Prospect API in action
The API is pretty straight-forward, but the URLs pointing to the full text are stuffed into a “Links” HTTP header, and the value of the header is not as easily parseable as one might desire. Still, this can be put to good use in my slowly growing stock of text mining tools. Get DOI. Feed to one of my tools. Get data. Do analysis.
Fun with HTTP.