





My second Python script, dispersion.py
Posted on November 19, 2014 in UncategorizedThis is my second Python script, dispersion.py, and it illustrates where common words appear in a text.
#!/usr/bin/env python2 # dispersion.py - illustrate where common words appear in a text # # usage: ./dispersion.py <file> # Eric Lease Morgan <emorgan@nd.edu> # November 19, 2014 - my second real python script; "Thanks for the idioms, Don!" # configure MAXIMUM = 25 POS = 'NN' # require import nltk import operator import sys # sanity check if len( sys.argv ) != 2 : print "Usage:", sys.argv[ 0 ], "<file>" quit() # get input file = sys.argv[ 1 ] # initialize with open( file, 'r' ) as handle : text = handle.read() sentences = nltk.sent_tokenize( text ) pos = {} # process each sentence for sentence in sentences : # POS the sentence and then process each of the resulting words for word in nltk.pos_tag( nltk.word_tokenize( sentence ) ) : # check for configured POS, and increment the dictionary accordingly if word[ 1 ] == POS : pos[ word[ 0 ] ] = pos.get( word[ 0 ], 0 ) + 1 # sort the dictionary pos = sorted( pos.items(), key = operator.itemgetter( 1 ), reverse = True ) # do the work; create a dispersion chart of the MAXIMUM most frequent pos words text = nltk.Text( nltk.word_tokenize( text ) ) text.dispersion_plot( [ p[ 0 ] for p in pos[ : MAXIMUM ] ] ) # done quit()
I used the program to analyze two works: 1) Thoreau’s Walden, and 2) Emerson’s Representative Men. From the dispersion plots displayed below, we can conclude a few things:
- The words “man”, “life”, “day”, and “world” are common between both works.
- Thoreau discusses water, ponds, shores, and surfaces together.
- While Emerson seemingly discussed man and nature in the same breath, but none of his core concepts are discussed as densely as Thoreau’s.
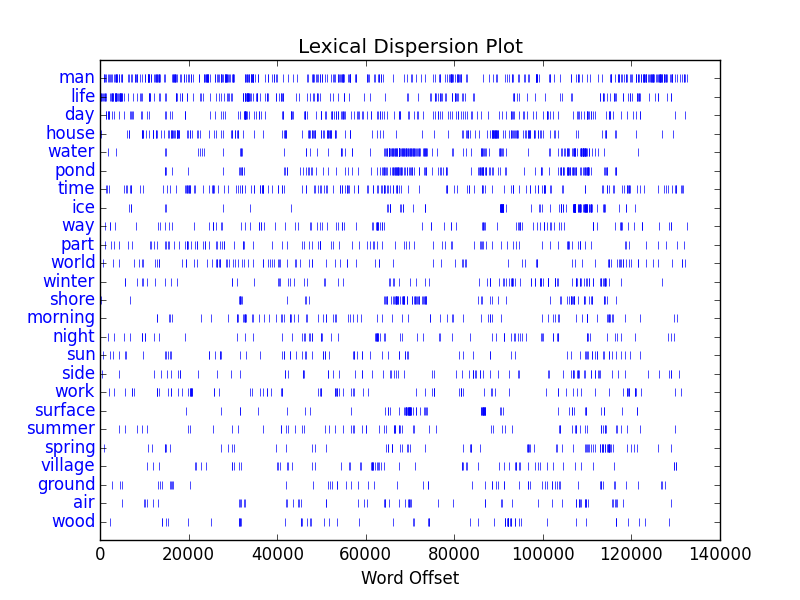
Thoreau’s Walden
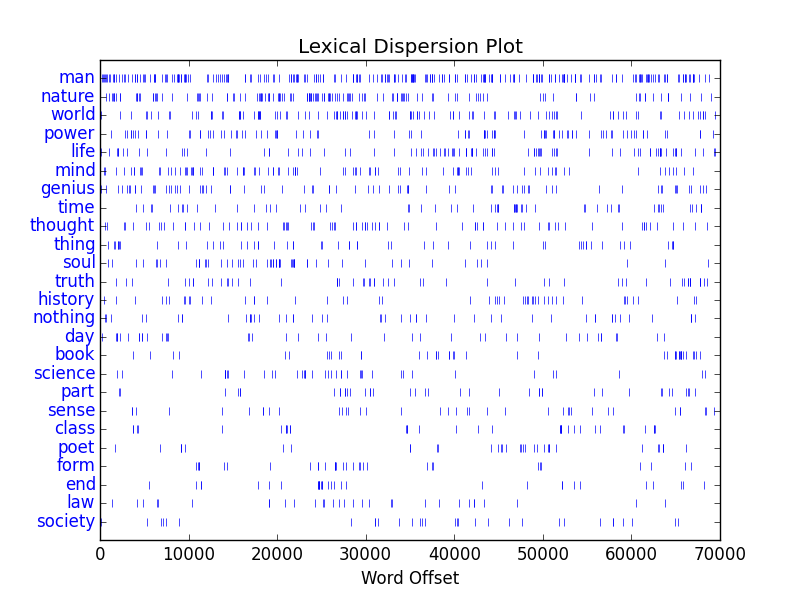
Emerson’s Representative Men
Python’s Natural Langauge Toolkit (NLTK) is a good library to get start with for digital humanists. I have to learn more though. My jury is still out regarding which is better, Perl or Python. So far, they have more things in common than differences.