





Synonymizer: Using Wordnet to create a synonym file for Solr
Posted on January 16, 2017 in Uncategorized by Eric Lease Morgan
This posting describes a little hack of mine, Synonymizer — a Python-based CGI script to create a synonym files suitable for use with Solr and other applications. [0]
Human language is ambiguous, and computers are rather stupid. Consequently computers often need to be explicitly told what to do (and how to do it). Solr is a good example. I might tell Solr to find all documents about dogs, and it will dutifully go off and look for things containing d-o-g-s. Solr might think it is smart by looking for d-o-g as well, but such is a heuristic, not necessarily a real understanding of the problem at hand. I might say, “Find all documents about dogs”, but I might really mean, “What is a dog, and can you give me some examples?” In which case, it might be better for Solr to search for documents containing d-o-g, h-o-u-n-d, w-o-l-f, c-a-n-i-n-e, etc.
This is where Solr synonym files come in handy. There are one or two flavors of Solr synonym files, and the one created by my Synonymizer is a simple line-delimited list of concepts, and each line is a comma-separated list of words or phrases. For example, the following is a simple Solr synonym file denoting four concepts (beauty, honor, love, and truth):
beauty, appearance, attractiveness, beaut
honor, abide by, accept, celebrate, celebrity
love, adoration, adore, agape, agape love, amorousness
truth, accuracy, actuality, exactitude
Creating a Solr synonym file is not really difficult, but it can be tedious, and the human brain is not always very good at multiplying ideas. This is where computers come in. Computers do tedium very well. And with the help of a thesaurus (like WordNet), multiplying ideas is easier.
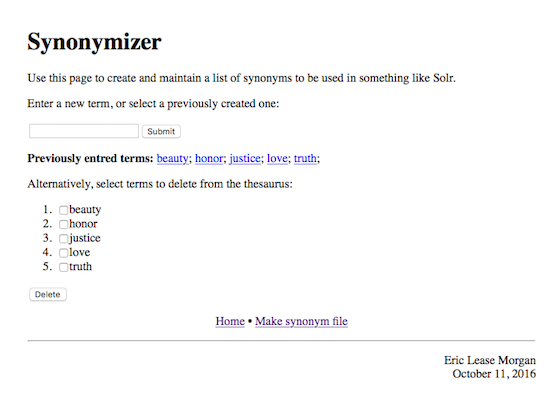
Here is how Synonymizer works. First it reads a configured database of previously generated synonyms.† In the beginning, this file is empty but must be readable and writable by the HTTP server. Second, Synonymizer reads the database and offers the reader to: 1) create a new set of synonyms, 2) edit an existing synonym, or 3) generate a synonym file. If Option #1 is chosen, then input is garnered, and looked up in WordNet. The script will then enable the reader to disambiguate the input through the selection of apropos definitions. Upon selection, both WordNet hyponyms and hypernyms will be returned. The reader then has the opportunity to select desired words/phrase as well as enter any of their own design. The result is saved to the database. The process is similar if the reader chooses Option #2. If Option #3 is chosen, then the database is read, reformatted, and output to the screen as a stream of text to be used on Solr or something else that may require similar functionality. Because Option #3 is generated with a single URL, it is possible to programmatically incorporate the synonyms into your Solr indexing process pipeline.
The Synonymizer is not perfect.‡ For example, it only creates one of the two different types of Solr synonym files. Second, while Solr can use the generated synonym file, search results implement phrase searches poorly, and this is well-know issue. [1] Third, editing existing synonyms does not really take advantage of previously selected items; data-entry is tedious but not as tedious as writing the synonym file by hand. Forth, the script is not fast, and I blame this on Python and WordNet.
Below are a couple of screenshots from the application. Use and enjoy.

[0] synonymizer.py – http://dh.crc.nd.edu/sandbox/synonymizer/synonymizer.py
[1] “Why is Multi-term synonym mapping so hard in Solr?” – http://bit.ly/2iyYZw6
† The “database” is really simple delimited text file. No database management system required.
‡ Software is never done. If it were, then it would be called “hardware”.