HathiTrust Resource Center Workset Browser
Posted on May 26, 2015 in UncategorizedIn my copious spare time I have hacked together a thing I’m calling the HathiTrust Research Center Workset Browser, a (fledgling) tool for doing “distant reading” against corpora from the HathiTrust. [1]
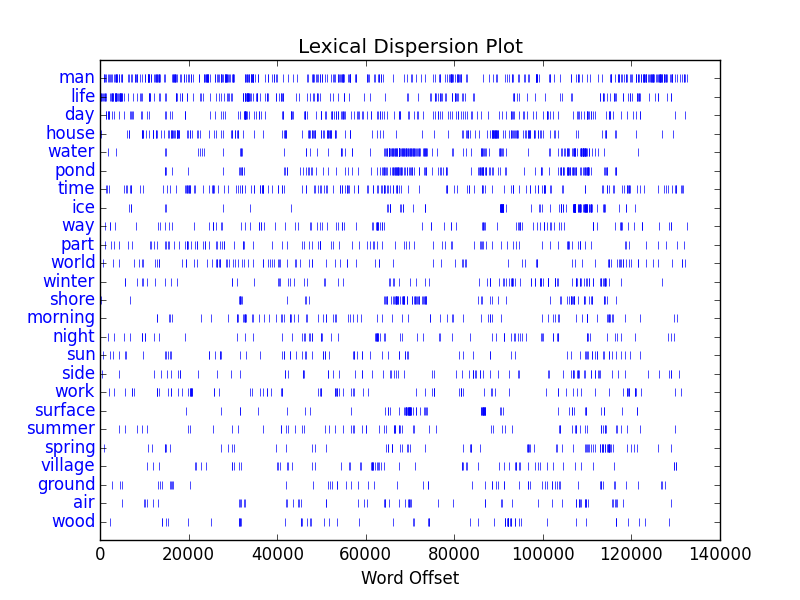
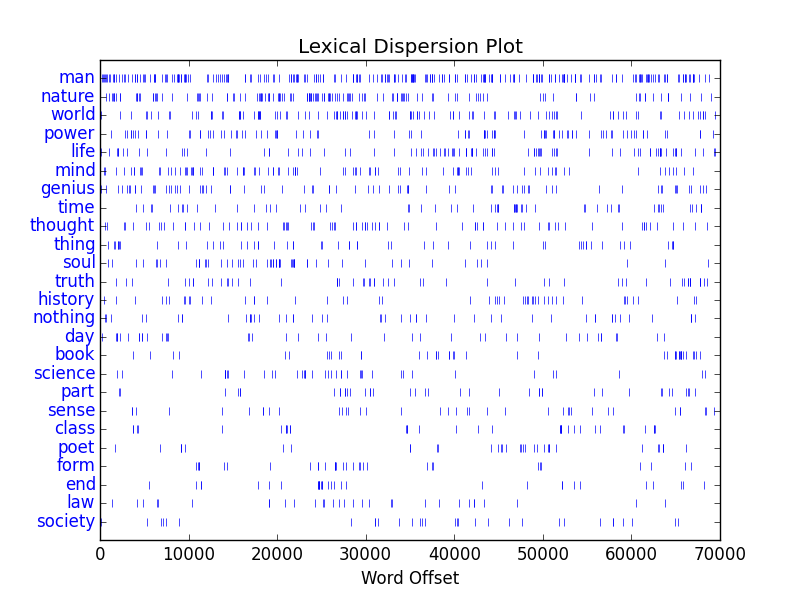
The idea is to: 1) create, refine, or identify a HathiTrust Research Center workset of interest — your corpus, 2) feed the workset’s rsync file to the Browser, 3) have the Browser download, index, and analyze the corpus, and 4) enable to reader to search, browse, and interact with the result of the analysis. With varying success, I have done this with a number of worksets ranging on topics from literature, philosophy, Rome, and cookery. The best working examples are the ones from Thoreau and Austen. [2, 3] The others are still buggy.
As a further example, the Browser can/will create reports describing the corpus as a whole. This analysis includes the size of a corpus measured in pages as well as words, date ranges, word frequencies, and selected items of interest based on pre-set “themes” — usage of color words, name of “great” authors, and a set of timeless ideas. [4] This report is based on more fundamental reports such as frequency tables, a “catalog”, and lists of unique words. [5, 6, 7, 8]

The whole thing is written in a combination of shell and Python scripts. It should run on just about any out-of-the-box Linux or Macintosh computer. Take a look at the code. [9] No special libraries needed. (“Famous last words.”) In its current state, it is very Unix-y. Everything is done from the command line. Lot’s of plain text files and the exploitation of STDIN and STDOUT. Like a Renaissance cartoon, the Browser, in its current state, is only a sketch. Only later will a more full-bodied, Web-based interface be created.
The next steps are numerous and listed in no priority order: putting the whole thing on GitHub, outputting the reports in generic formats so other things can easily read them, improving the terminal-based search interface, implementing a Web-based search interface, writing advanced programs in R that chart and graph analysis, provide a means for comparing & contrasting two or more items from a corpus, indexing the corpus with a (real) indexer such as Solr, writing a “cookbook” describing how to use the browser to to “kewl” things, making the metadata of corpora available as Linked Data, etc.
‘Want to give it a try? For a limited period of time, go to the HathiTrust Research Center Portal, create (refine or identify) a collection of personal interest, use the Algorithms tool to export the collection’s rsync file, and send the file to me. I will feed the rsync file to the Browser, and then send you the URL pointing to the results. [10] Let’s see what happens.
Fun with public domain content, text mining, and the definition of librarianship.
Links
- HTRC Workset Browser – http://bit.ly/workset-browser
- Thoreau – http://bit.ly/browser-thoreau
- Austen – http://bit.ly/browser-austen
- Thoreau report – http://bit.ly/browser-thoreau-about
- Thoreau dictionary (frequency list) – http://bit.ly/thoreau-dictionary
- usage of color words in Thoreau — http://bit.ly/thoreau-colors
- unique words in the corpus – http://bit.ly/thoreau-unique
- Thoreau “catalog” — http://bit.ly/thoreau-catalog
- source code – http://ntrda.me/1Q8pPoI
- HathiTrust Research Center Portal – https://sharc.hathitrust.org