This is a travelogue documenting my experiences at second Code4Lib Midwest Meeting (July 28 & 29, 2011) at the University of Illinois, Chicago.

Attendees of Code4Lib Midwest
Day #1
The meeting began with a presentation by Peter Schlumpf (Avanti Library Systems). In it he described and demonstrated Avanti Nova, an application used to create and maintain semantic maps. To do so, a person first creates objects denoted by strings of characters. This being Library Land, these strings of characters can be anything from books to patrons, from authors to titles, from URLs to call numbers. Next a person creates links (relationships) between objects. These links are seemingly simple. One points to another, vice versa, or the objects link to each other. The result of these two processes forms a thing Schlumpf called a relational matrix. Once the relational matrix is formed queries can be applied against it and reports can be created. Towards the end of the presentation Schlumpf demonstrated how Avanti Nova could be used to implement a library catalog as well as represent the content of a MARC record.
Robert Sandusky (University of Illinois, Chicago) shared with the audience information about a thing called the DataOne Toolkit. DataOne is a federation of data repositories including nodes such as Dryad, MNs, and UC3 Merritt. The Toolkit supports an application programmer interface to support three levels of federation compliance: read, write, and replicate. I was particularity interested in DataOne’s data life cycle: collect, assure, describe, deposit, preserve, discover, integrate, analyze, collect. I also liked the set of adjectives and processes used to describe the vision of DataOne: adaptive, cognitive, community building, data sharing, discovery & access, education & training, inclusive, informed, integrate and synthesis, resilient, scalable, and usable. Sandusky encouraged members of the audience (and libraries in general) to become members of DataOne as well as community-based repositories. He and DataOne see libraries playing a significant role when it comes to replication of research data.
Somewhere in here I, Eric Lease Morgan (University of Notre Dame), spoke to the goals of the Digital Public Library of America (DPLA) as well as outlined my particular DPLA Beta-Sprint Proposal. In short, I advocated the library community move beyond the process of find & get and towards the process of use & understanding.
Ken Irwin (Wittenberg University) gave a short & sweet lightning talk about “hacking” trivial projects. Using an example from his workplace — an application used to suggest restaurants — he described how he polished is JQuery skills and enhanced is graphic design skills. In short he said, “There is a value for working on things that are not necessarily library-related… By doing so there is less pressure to do it ‘correctly’.” I thought these were words of wisdom and point to the need for play and experimentation.
Rick Johnson (University of Notre Dame) described how he and his group are working in an environment where the demand is greater than the supply. Questions he asked of the group, in an effort to create discussion, included: how do we move from a development shop to a production shop, how do we deal with a backlog of projects, to what degree are we expected to address library problems versus university problems, to what extent should our funding be grant-supported and if highly, then what is our role in the creation of these grants. What I appreciated most about Johnson’s remarks was the following: “A library is still a library no matter what medium they collect.” I wish more of our profession expressed such sentiments.
Margaret Heller (Dominican University) asked the question, “How can we assist library students learn a bit of technology and at the same time get some work done?” To answer her question she described how her students created a voting widget, did an environmental scan, and created a list of library labs.
Christine McClure (Illinois Institute of Technology) was given the floor, and she was seeking feedback in regards to here recently launched mobile website. Working in a very small shop, she found the design process invigorating since she was not necessarily beholden to a committee for guidance. “I work very well with my boss. We discuss things, and I implement them.” Her lightning talk was the first of many which exploited JQuery and JQuery Mobile, and she advocated the one-page philosophy of Web design.
Jeremy Prevost (Northwestern University) built upon the McClure’s topic by describing how he built a mobile website using a Model View Controller (MVC) framework. Using such a framework, which is operating system and computer programming language agnostic, accepts a URL as input, performs the necessary business logic, branches according to the needs/limitations of the HTTP user-agent, and returns the results appropriately. Using MVC he is able to seamlessly provide many different interfaces to his website.
If a poll had been taken on the best talk of the Meeting, then I think Matthew Reidsma‘s (Grand Valley State University) presentation would have come out on top. In it he drove home two main points: 1) practice “progressive enhancement” Web design as opposed to “graceful degradation”, and 2) use JQuery to control the appearance and functionality of hosted Web content. In the former, single Web pages are designed in a bare bones manner, and through the use of conditional Javascript logic and cascading stylesheets the designer implements increasingly complicated pages. This approach works well for building mobile websites through full-fledged desktop browser interfaces. The second point — exploiting JQuery to control hosted pages — was very interesting. He was given access to the header and footer of hosted content (Summon). He then used JQuery’s various methods to read the body of the pages, munge it, and present more aesthetically pleasing as well as more usable pages. His technique was quite impressive. Through Reidsma’s talk I also learned the necessity of many skills to do Web work. It is not enough to know how HTML or Javascript or graphic design or database management or information architecture, etc. Instead, it is necessary to have a combination of these skills in order to really excel. To a great degree Riedsma embodied such a combination.
Francis Kayiwa (University of Illinois, Chicago) wrapped up the first day by asking the group questions about hosting and migrating applications from different domains. The responses quickly turned to things about EAD files, blogs postings, and where the financial responsibility lies when grant money dries up. Ah, Code4Lib. You gotta love it.
Day #2
The second day was given over to three one-hour presentations. The first was by Rich Wolf (University of Illinois, Chicago) who went to excruciating detail on how to design and write RESTful applications using Objective-C.
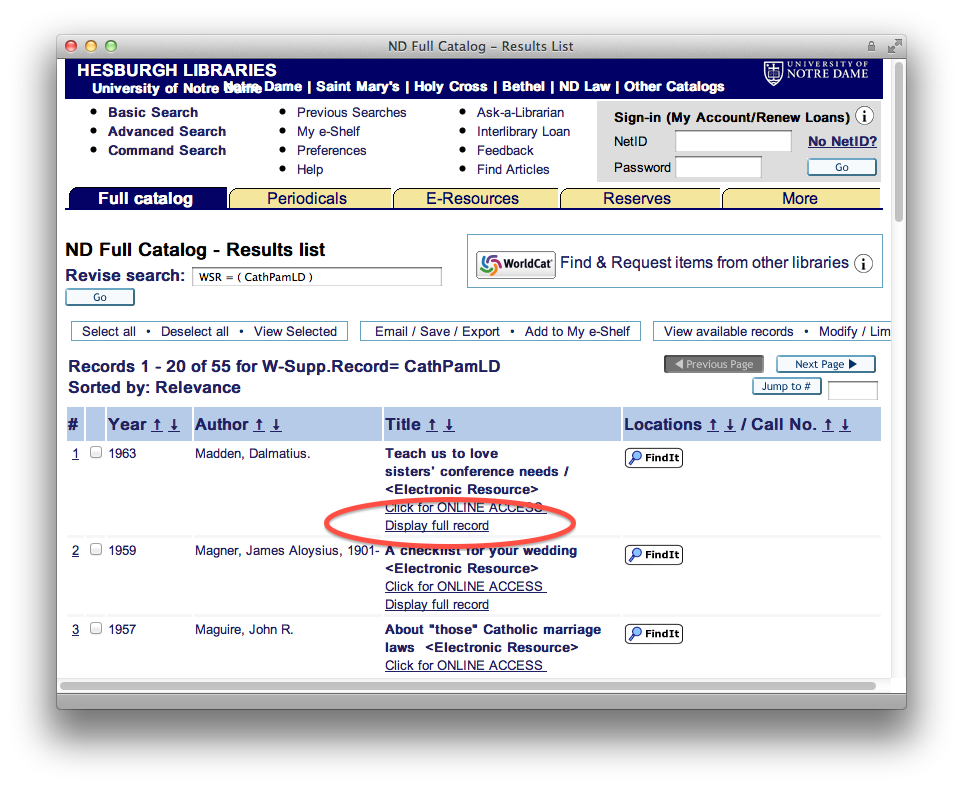
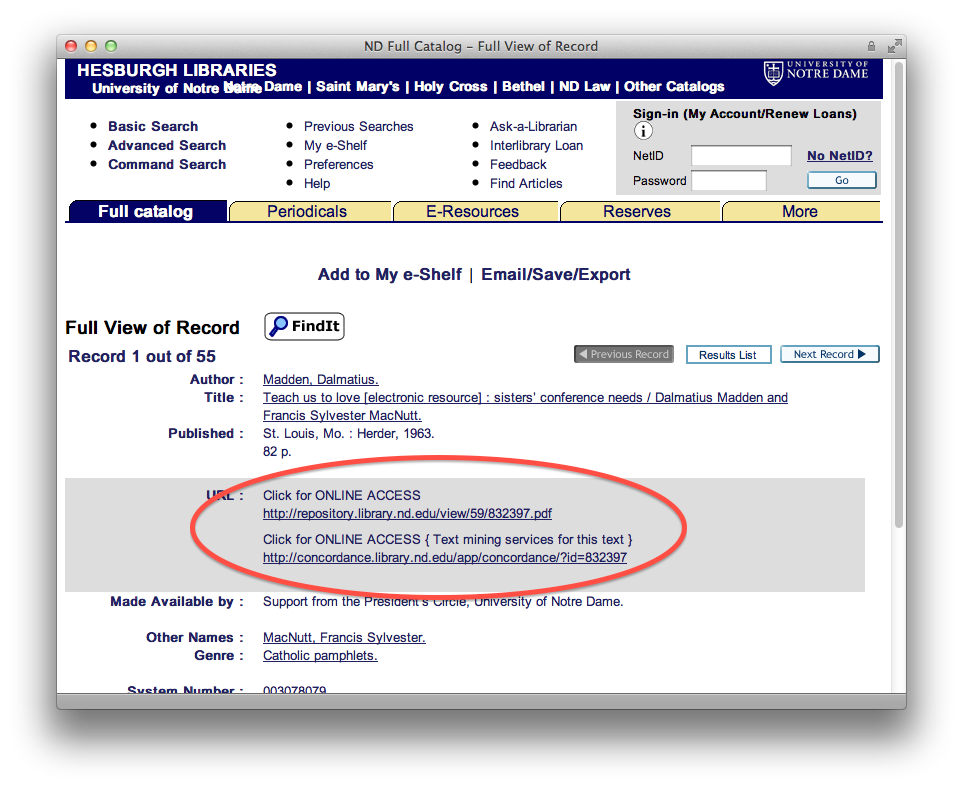
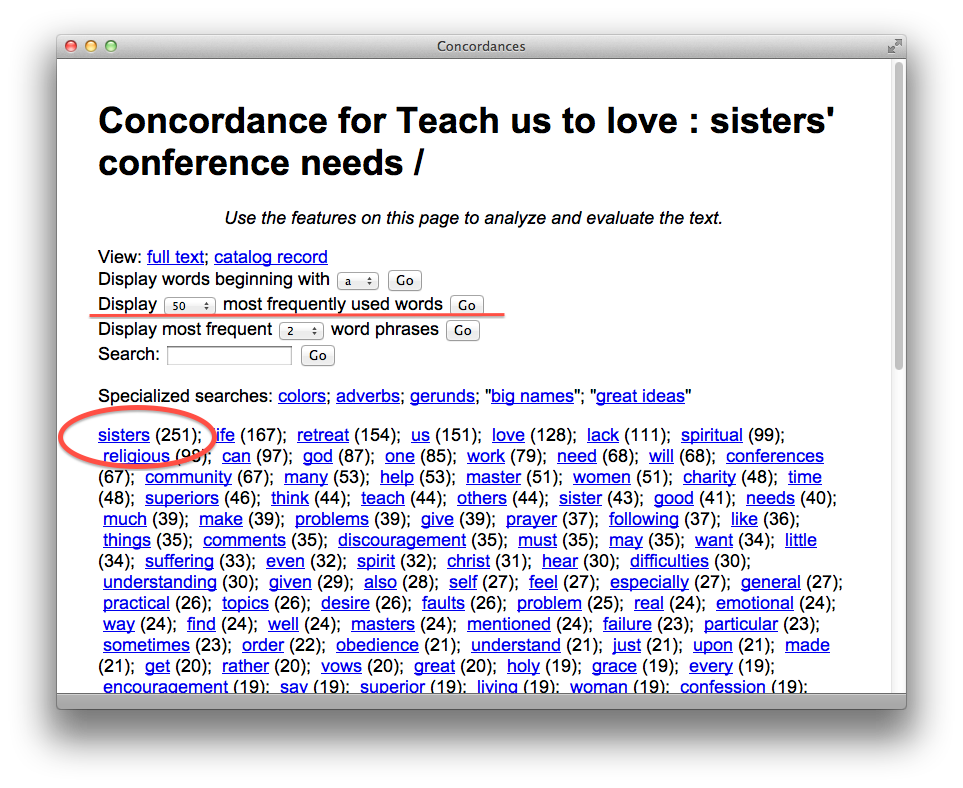
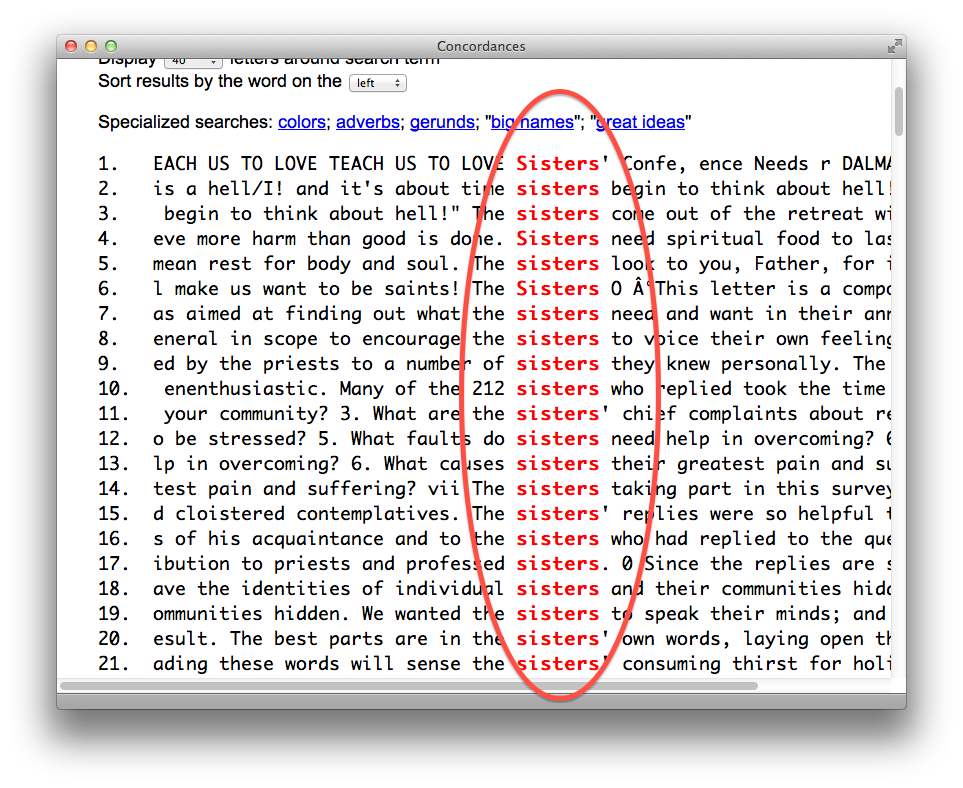
My presentation on text mining might have been as painful for others. In it I tried to describe and demonstrate how libraries could exploit the current environment to provide services against texts through text mining. Examples included the listing of n-grams and their frequencies, concordances, named-entity extractions, word associations through network diagrams, and geo-locations. The main point of the presentation was “Given the full text of documents and readily accessible computers, a person can ‘read’ and analyze a text in so many new and different ways that would not have been possible previously.”
The final presentation at the Meeting was by Margaret Kipp (University of Wisconsin Milwaukee), and it was called “Teaching Linked Data”. In it she described and demonstrated how she was teaching library school students about mash-ups. Apparently her students have very little computer experience, and the class surrounded things like the shapes of URLs, the idea of Linked Data, and descriptions of XML and other data streams like JSON. Using things like Fusion tables, Yahoo Pipes, Simile Timelines, and Google Maps students were expected to become familiar with new uses for metadata and open data. One of the nicest things I heard from Kipp was, “I was also trying to teach the students about programatic thinking.” I too think such a thing is important; I think it important to know how to think both systematically (programmatically) as well as analytically. Such thinking processes complement each other.
Summary
From my perspective, the Meeting was an unqualified success. Kudos go to Francis Kayiwa, Abigail Goben, Bob Sandusky, and Margaret Heller for organizing the logistics. Thank you! The presentations were on target. The facilites were more than adequate. The wireless network connections were robust. The conversations were apropos. The company was congenial. The price was right. Moreover, I genuinely believe everybody went away from the Meeting learning something new.
I also believe these sorts of meetings demonstrate the health and vitality of the growing Code4Lib community. The Code4Lib mailing list boasts about 2,000 subscribers who are from all over the world but mostly in the United States. Code4Lib sponsors an annual meeting and regularly occurring journal. Regional meetings, like this one in Chicago, are effective and inexpensive professional development opportunities for people who are unable or uncertain about the full-fledged conference. If these meetings continue, then I think we ought to start charging a franchise fee. (Just kidding, really.)