I attended the Semantic Web in Libraries 2013 conference in Hamburg (November 25-27), and this posting documents some of my experiences. In short, I definitely believe the linked data community in libraries is maturing, but I still wonder whether or not barrier for participation is really low enough for the vision of the Semantic Web to become a reality.

Preconference on provenance
On the first day I attended a preconference about linked data and provenance led by Kai Eckert (University of Mannheim) and Magnus Pfeffer (Stuttgarat Media University). One of the fundamental ideas behind the Semantic Web and linked data is the collecting of triples denoting facts. These triples are expected to be amassed and then inferenced across in order to bring new knowledge to light. But in the scholarly world it is important cite and attribute scholarly output. Triples are atomistic pieces of information: subjects, predicates, objects. But there is no room in these simple assertions to denote where the information originated. This issue was the topic of the preconference discussion. Various options were outlined but none of them seemed optimal. I’m not sure of the conclusion, but one “solution” may be the use of PROV, “a model, corresponding serializations and other supporting definitions to enable the inter-operable interchange of provenance information in heterogeneous environments such as the Web”.

Day #1
Both Day #1 and Day #2 were peppered with applications which harvested linked data (and other content) to create new and different views of information. AgriVIVO, presented by John Fereira (Cornell University) was a good example:
AgriVIVO is a search portal built to facilitate connections between all actors in the agricultural field, bridging across separately hosted directories and online communities… AgriVIVO is based on the VIVO open source semantic web application initially developed at Cornell University and now adopted by several cross-institutional research discovery projects.
Richard Wallis (OCLC) advocated the creation of library knowledge maps similar to the increasingly visible “knowledge graphs” created by Google and displayed at the top of search results. These “graphs” are aggregations of images, summaries, maps, and other bit of information providing the reader with answers / summaries describing what may be the topic of search. They are the same sort of thing one sees when searches are done in Facebook as well. And in the true spirit of linked data principles, Wallis advocated the additional use of additional peoples’ Semantic Web ontologies such as the ontology used by Schema.org. If you want to participate and help extend the bibliographic entities of Schema.org, then consider participating in a W3C Community called Schema Bib Extend Community Group.
BIBFRAME was described by Julia Hauser (Reinhold Heuvelmann German National Library). Touted as as a linked data replacement for MARC, its data model consists of works, instances, authorities, and annotations (everything else). According to Hauser, “The big unknown is how can RDA or FRBR be expressed using BIBFRAME.” Personally, I noticed how BIBFRAME contains no holdings information, but such an issue may be resolvable through the use of schema.org.
“Language effects hierarchies and culture comes before language” were the concluding remarks in a presentation by the National Library of Finland. Leaders in the linked data world, the presenters described how they were trying to create a Finnish ontology, and they demonstrated how language does not fit into neat and orderly hierarchies and relationships. Things always get lost in translation. For example, one culture may have a single word for a particular concept, but another culture may have multiple words because the concept has more nuances in its experience. Somewhere along the line the presenters alluded to onki-light, “a REST-style API for machine and Linked Data access to the underlying vocabulary data.” I believe the presenters were using this tool to support access to their newly formed ontology.
Yet another ontology was described by Carsten Klee (Berlin State Library) and Jakob Voẞ (GBV Common Library Network). This was a holdings ontology which seemed unnecessarily complex to me, but then I’m no real expert. See the holding-ontology repository on Github.

Day #2
I found the presentation — “Decentralization, distribution, disintegration: Towards linked data as a first class citizen in Library Land” — by Martin Malmsten (National Library of Sweden) to be the most inspiring. In the presentation he described why he thinks linked data is the way to describe the content of library catalogs. He also made insightful distinctions between file formats and the essencial characteristics of data, information, knowledge, (and maybe wisdom). Like many at the conference, he advocated interfaces to linked data, not MARC:
Working with RDF has enabled me to see beyond simple formats and observe the bigger picture — “Linked data or die”. Linked data is the way to do it now. I advocate the abstraction of MARC to RDF because RDF is more essencial and fundmental… Mixing data is new problem with the advent of linked data. This represents a huge shift in our thinking of Library Land. It is transformative… Keep the formats (monsters and zombies) outside your house. Formats are for exchange. True and real RDF is not a format.
Some of the work demonstrating the expressed ideas of the presentation is available on Github in a package called librisxl.
Another common theme / application demonstrated at the conference were variations of the venerable library catalog. OpenCat, presented by Agnes Simon (Bibliothéque Nationale de France), was an additional example of this trend. Combining authority data (available as RDF) provided by the National Library of France with works of a second library (Fresnes Public Library), the OpenCat prototype provides quite an interesting interface to library holdings.
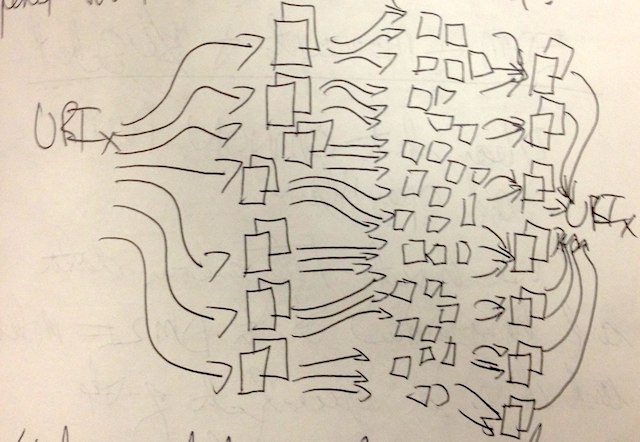
Peter Király (Europeana Foundation) described how he is collecting content over many protocols and amalgamating it into the data store of Europenana. I appreciated the efforts he has made to normalize and enrich the data — not an easy task. The presentation also made me think about provenance. While provenance is important, maybe trust of provenance can come from the aggregator. I thought, “If these aggregators believe — trust — the remote sources, then may be I can too.” Finally, the presentation got me imagining how one URI can lead to others, and my goal would be to distill it down again into a single URI all of the interesting information I found a long the way, as in the following image I doodled during the presentation.
Enhancing the access and functionality of manuscripts was the topic of the presentation by Kai Eckert (Universität Mannheim). Specifically, manuscripts are digitized and an interface is placed on top allowing scholars to annotate the content beneath. I think the application supporting this functionality is called Pundit. Along the way he takes heterogeneous (linked) data and homogenizes it with a tool called DM2E.
OAI-PMH was frequently alluded to during the conference, and I have some ideas about that. In “Application of LOD to enrich the collection of digitized medieval manuscripts at the University of Valencia” Jose Manuel Barrueco Cruz (University of Valencia) described how the age of his content inhibited his use of the currently available linked data. I got the feeling there was little linked data closely associated with the subject matter of his manuscripts. Still, an an important thing to note, is how he started his investigations with the use of Datahub:
a data management platform from the Open Knowledge Foundation, based on the CKAN data management system… [providing] free access to many of CKAN’s core features, letting you search for data, register published datasets, create and manage groups of datasets, and get updates from datasets and groups you’re interested in. You can use the web interface or, if you are a programmer needing to connect the Datahub with another app, the CKAN API.
Simeon Warner (Cornell University) described how archives or dumps of RDF triple stores are synchronized across the Internet via HTTP GET, gzip, and a REST-ful interface on top of Google sitemaps. I was impressed because the end result did not necessarily invent something new but rather implemented an elegant solution to a real-world problem using existing technology. See the resync repository on Github.
In “From strings to things: A linked data API for library hackers and Web developers” Fabian Steeg and Pascal Christoph (HBZ) described an interface allowing librarians to determine the URIs of people, places, and things for library catalog records. “How can we benefit from linked data without being linked data experts? We want to pub Web developers into focus using JSON for HTTP.” There are few hacks illustrating some of their work on Github in the lobid repository.
Finally, I hung around for a single lightning talk — Carsten Klee’s (Berlin State Library) presentation of easyM2R, a PHP script converting MARC to any number of RDF serializations.

Observations, summary, and conclusions
I am currently in the process of writing a short book on the topic of linked data and archives for an organization called LiAM — “a planning grant project whose deliverables will facilitate the application of linked data approaches to archival description.” One of my goals for attending this conference was to determine my level of understanding when it comes to linked data. At the risk of sounding arrogant, I think I’m on target, but at the same time, I learned a lot at this conference.
For example, I learned that the process of publishing linked data is not “rocket surgery” and what I have done to date is more than functional, but I also learned that creating serialized RDF from MARC or EAD is probably not the best way to create RDF. I learned that publishing linked data is only one half of the problem to be solved. The other half is figuring out ways to collect, organize, and make useful the published content. Fortunately this second half of the problem was much of what the conference was about. Many people are using linked data to either create or enhance “next-generation library catalogs”. In this vein they are not really doing anything new and different; they are being evolutionary. Moreover, many of the developers are aggregating content using quite a variety of techniques, OAI-PMH being one of the more frequent.
When it comes to OAI-PMH and linked data, I see very much the same vision. Expose metadata in an agreed upon format and in an agreed upon method. Allow others to systematically harvest the metadata. Provide information services against the result. OAI-PMH was described as protocol with a low barrier to entry. The publishing of linked data is also seen as low barrier technology. The challenges of both first lie the vocabularies used to describe the things of the metadata. OAI-PMH required Dublin Core but advocated additional “ontologies”. Few people implemented them. Linked data is not much different. The problem with the language of the things is just as prevalent, if not more so. Linked data is not just the purview of Library Land and a few computer scientists. Linked data has caught the attention of a much wider group of people, albiet the subject is still a bit esoteric. I know the technology supporting linked data functions. After all, it is the technology of the Web. I just wonder if: 1) there will ever be a critical mass of linked data available in order to fulfill its promise, and 2) will we — the information community — be able to overcome the “Tower of Babel” we are creating with all the the various ontologies we are sporting. A single ontology won’t work. Just look at Dublin Core. Many ontologies won’t work either. There is too much variation and too many idiosyncrasies in real-world human language. I don’t know what the answer is. I just don’t.
Despite some of my misgivings, I think the following quote by Martin Malmsten pretty much sums up much of the conference — Linked data or die!