This posting summarizes the Catholic Pamphlets Project — a process to digitize sets of materials from the Hesburgh Libraries collection, add the result to a repository, provide access to the materials through the catalog and “discovery system” as well as provide enhanced access to the materials through a set of text mining interfaces. In a sentence, the Project has accomplished most of its initial goals both on time and under budget.
The Project’s original conception
The Catholic Pamphlets Project began early in 2011 with the writing of a President’s Circle Award proposal. The proposal detailed how sets of Catholic Americana would be digitized in conjunction with the University Archives. The Libraries was to digitize the 5,000 Catholic pamphlets located in Special Collections, and the Archives was to digitize its set of Orestes Brownson papers. In addition, a graduate student was to be hired to evaluate both collections, write introductory essays describing why they are significant research opportunities, and do an environmental scan regarding the use of digital humanities computing techniques applied against digitized content. In the end, both the Libraries and the Archives would have provided digital access to the materials through things like the library catalog, its “discovery” system, and the “Catholic Portal”, as well as laid the groundwork for further digitization efforts.
Getting started
By late Spring a Project leader was identified, and their responsibilities were to coordinate the Libraries’s side of the Project in conjunction with a number of library departments including Special Collections, Cataloging, Electronic Resources, Preservation, and Systems. By this time it was also decided not to digitize the entire collection of 5,000 items, but instead hire someone for the summer to digitize as many items as possible and process them accordingly – a workflow test. In the meantime, a comparison of in-house and vendor-supplied digitization costs would be evaluated.
By this time a list of specific people had also been identified to work on the Project, and these people became affectionately known as Team Catholic Pamphlets:
Aaron Bales • Eric Lease Morgan (leader) • Jean McManus • Julie Arnott • Lisa Stienbarger • Louis Jordan • Mark Dehmlow • Mary McKeown • Natasha Lyandres • Rajesh Balekai • Rick Johnson • Robert Fox • Sherri Jones
Work commences
Through out the summer a lot of manual labor was applied against the Project. A recent graduate from St. Mary’s (Eileen Laskowski) was hired to scan pamphlets. After a one or two weeks of work, she was relocated from the Hesburgh Library to the Art Slide Library where others were doing similar work. She used equipment borrowed from Desktop Computing and Network Services (DCNS) and the Slide Library. Both DCNS and the Slide Library were gracious about offering their resources. By the end of the summer Ms. Laskowski had digitized just less than 400 pamphlets. The covers were digitized in 24-bit color. The inside pages were gray-scale. Everything was digitized at 600 dots per inch. These pamphlets generated close to 92 GB of data in the form of TIFF and PDF files.
Because the Pamphlets Project was going to include links to concordance (text mining) interfaces from within the library’s catalog, Sherri Jones facilitated two hour-long workshops to interested library faculty and staff in order to explain and describe the interfaces. The first of these workshops took place in the early summer. The second took place in late summer.
In the meantime efforts were spent by two summer students of Jean McManus‘s. The students determined the copyright status of each of the 5,000 pamphlets. They used a decision-making flowchart as the basis of their work. This flowchart has since been reviewed by the University’s General Counsel and deemed a valid tool for determining copyright. Of the sum of pamphlets, approximately 4,000 (80%) have been determined to be in the public domain.
Starting around June Team Catholic Pamphlets decided to practice with the technical services aspect of the Project. Mary McKeown, Natasha Lyandres, and Lisa Stienbarger wrote a cataloging policy for the soon-to-be created MARC records representing the digital versions of the pamphlets. Aaron Bales exported MARC records representing the print versions of the pamphlets. PDF versions of approximately thirty-five pamphlets were placed on a Libraries’s Web server by Rajesh Balekai and Rob Fox. Plain text versions of the same pamphlets were placed on a different Web server, and a concordance application was configured against them. Using the content of the copyright database being maintained by Jean McManus’s students, Eric Lease Morgan updated the MARC records representing the print records to include links to the PDF and concordance versions of the pamphlets. The records were passed along to Lisa Stienbarger who updated them according to the newly created policy. The records were then loaded into a pre-production version of the catalog for verification. Upon examination the Team learned that users of Internet Explorer were not able to consistently view the PDF versions. After some troubleshooting, Rob Fox wrote a work-around to the problem, and the MARC records were changed to reflect new URLs of the PDF versions. Once this work was done the thirty-five records were loaded into the production version of the catalog, and from there they seamlessly flowed into the library’s “discovery system” – Primo. Throughout this time Julie Arnott and Dorothy Snyder applied quality control measures against the digitized content and wrote a report documenting their findings. Team Catholic Portal had successfully digitized and processed thirty-five pamphlets.
With these successes under our belts, and with the academic year commencing, Team Catholic Pamphlets celebrated with a pot-luck lunch and rested for a few weeks.
The workflow test concludes
In early October the Team got together again and unanimously decided to process the balance of the digitized pamphlets in order to put them into production. Everybody wanted to continue practicing with their established workflows. The PDF and plain text versions of the pamphlets were saved on their respective Web servers. The TIFF versions of the pamphlets were saved to the same file system as the library’s digital repository. URLs were generated. The MARC records were updated and saved to pre-production. After verification, they were moved to production and flowed to Primo. What took at least three months earlier in the year now took only a few weeks. By Halloween Team Catholic Pamphlets finished its workflow test processing the totality of the digitized pamphlets.
Access to the collection
There is no single home page for the collection of digitized pamphlets. Instead, each of the pamphlets have been cataloged, and through the use of command-line search strategy one can pull up all the pamphlets in the library’s catalog — http://bit.ly/sw1JH8
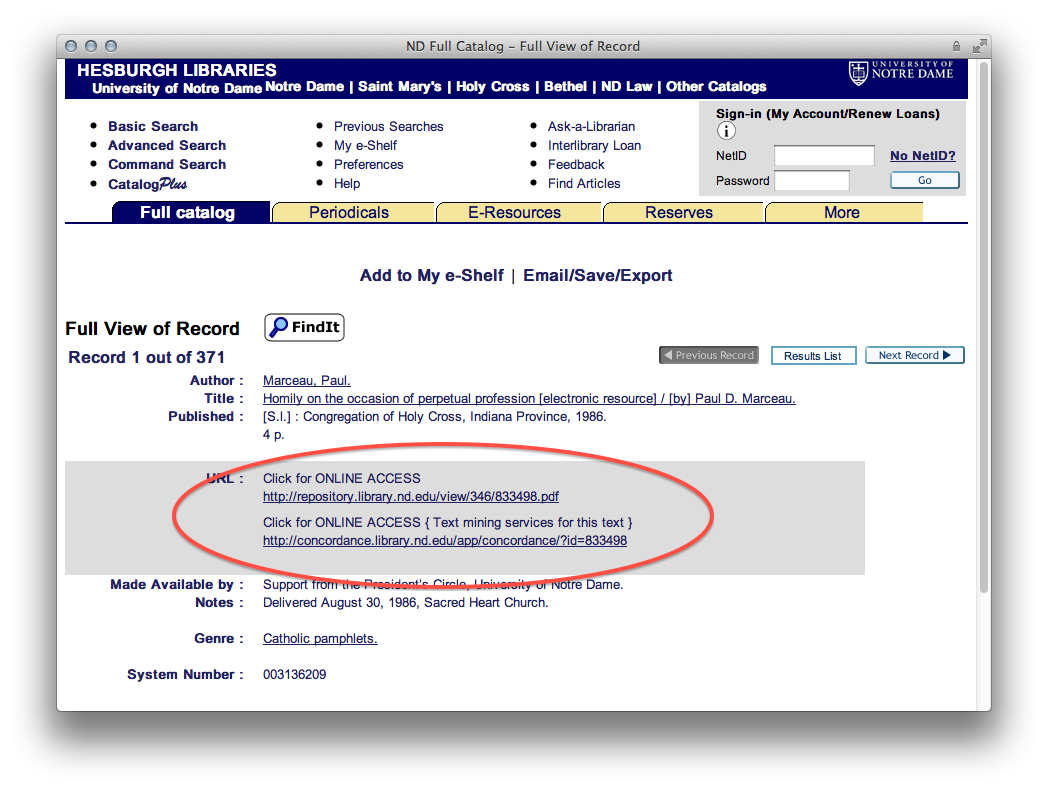
From the results list it is best to view the records’ detail in order to see all of the options associated with the pamphlet.
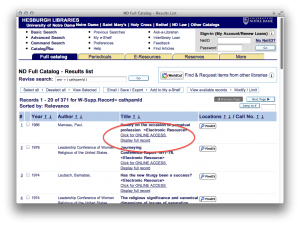
command-line search results page
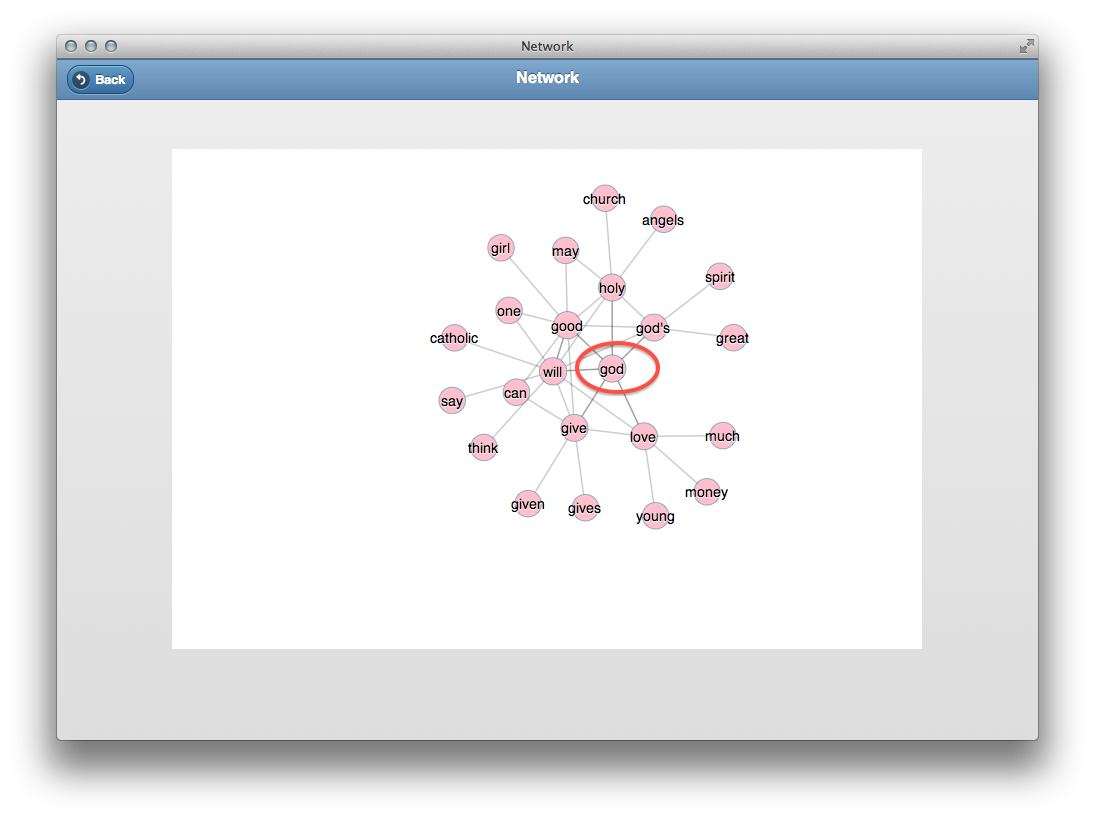
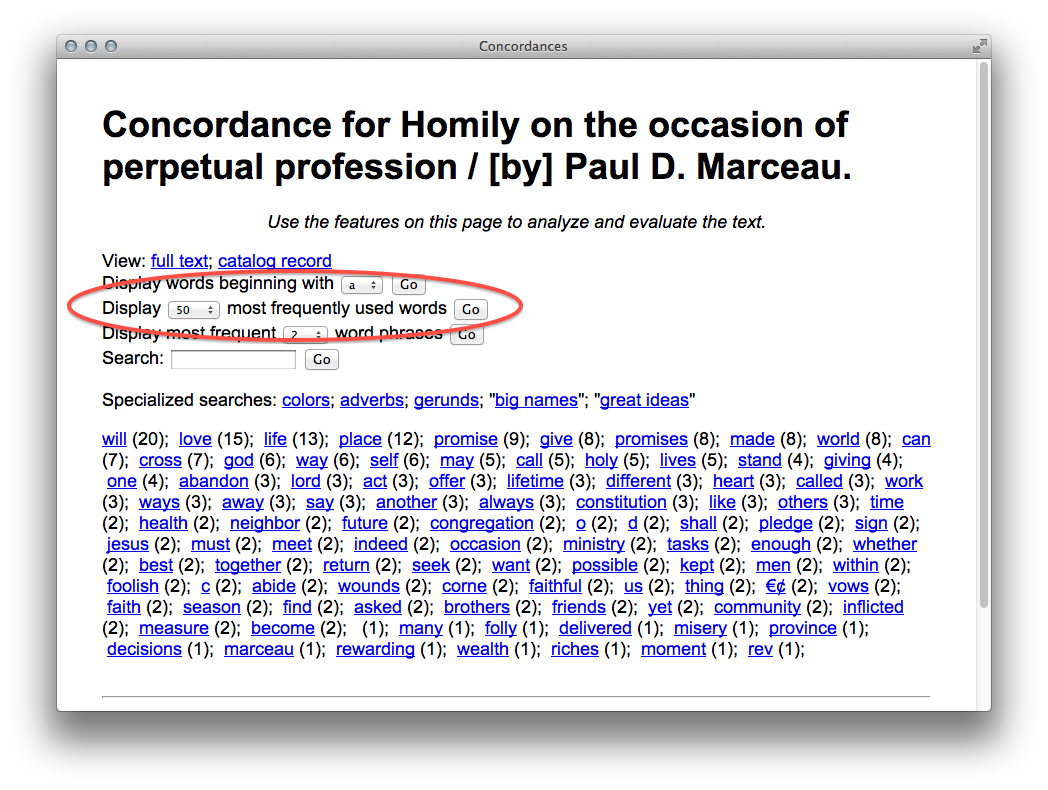
From the details page one can download and read the pamphlet in the form of a PDF document or the reader can use a concordance to apply “distant reading” techniques against the content.
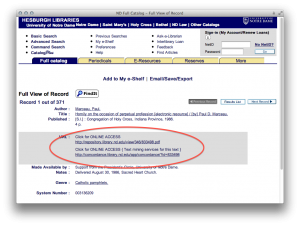
details of a specific Catholic pamphlets record
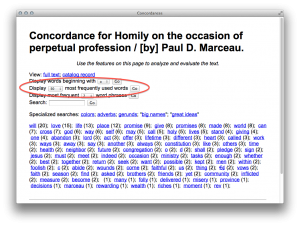
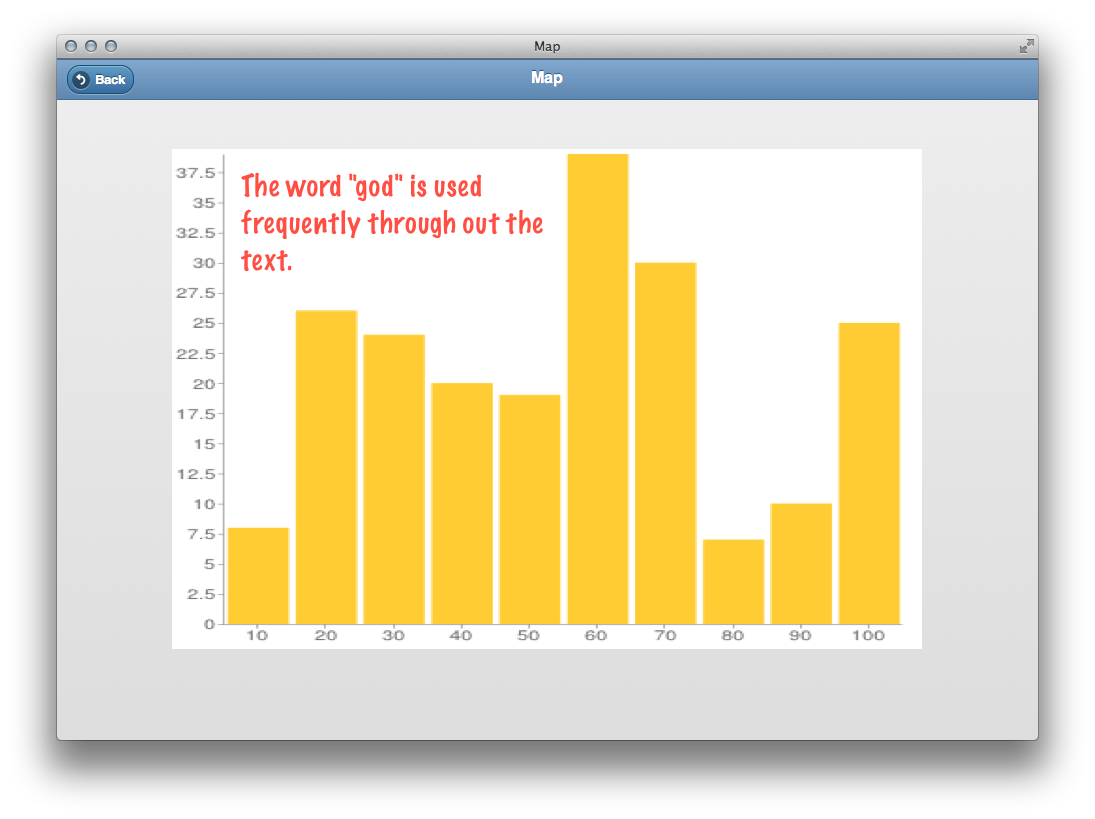
50 most frequently used words in a selected pamphlet
Conclusions and next steps
The Team accomplished most of its goals, and we learned many things, but not everything was accomplished. No graduate student was hired, and therefore no overarching description of the pamphlets (nor content from the Archives) was evaluated. Similarly, no environmental scan regarding use of digital humanities against the collections was done. While 400 of our pamphlets are accessible from the catalog as well as the “discovery system”, no testing has been done to determine their ultimate usability.
The fledgling workflow can still be refined. For example, the process of identifying content to digitize, removing it from Special Collections, digitizing it, returning it to Special Collections, doing quality control, adding the content to the institutional repository, establishing the text mining interfaces, updating the MARC records (with copyright information, URLs, etc.), and ultimately putting the lot into the catalog is a bit disjointed. Each part works well unto itself, but the process as a whole does not run like a well-oiled machine, yet. Like any new workflow, more practice is required.
This Project provided Team members with the opportunity to apply traditional library skills against a new initiative, and it was relished by everybody involved. The Project required the expertise of faculty and staff. It required the expertise of people in Collection Management, Preservation, Technical Services, Public Services, and Systems. Everybody applied their highly developed professional knowledge to a new and challenging problem. The Project was a cross-departmental holistic process, and it even generated interest in participation from people outside the Team. There are many people across the Libraries who would like to get involved with wider digitization efforts because they thought this Project was exciting and had the potential for future growth. They too see it as an opportunity for professional development.
While there are 5,000 pamphlets in the collection, only 4,000 of them are deemed in the public domain (legally digitizable). Four-hundred (400) pamphlets were scanned by a single person at a resolution of 600 dots/inch over a period of three months for a total cost of approximately $3,400. This is a digitization rate of approximately 1,200 pamphlets per year at a cost of $13,600. At this pace it would take the Libraries close to 3 1/3 years to digitized the 4,000 pamphlets for an approximate out-of-pocket labor cost of $44,880. If the dots/inch qualification were reduced by half – which still exceeds the needs for quality printing purposes – then it would take a single person approximately 1.7 years to do the digitization at a total cost of approximately $22,440. The time spent doing digitization could be reduced even further if the dots/inch qualification were reduced some more. One hundred fifty dots/inch is usually good enough for printing purposes. Based on our knowledge, it would cost less than $3,000 to purchase three or four computer/scanning set-ups similar to the ones used during the Project. If the Libraries were to hire as many as four students to do digitization, then we estimate the public domain pamphlets could be digitized in less than two years at a cost of approximately $25,000.
There are approximately 184,996 pages of Catholic pamphlet content, but approximately 80% of these pages (4,000 pamphlets of the total 5,000) are legally digitizable – 147,997 pages. A reputable digitization vendor will charge around $.25/page to do digitization. Consequently, the total out-of-pocket cost of using the vendor is close to $37,000.
Team Catholic Pamphlets recommends going forward with the Project using an in-house digitization process. Despite the administrative overhead associated with hiring and managing sets of digitizers, the in-house process affords the Libraries a means to learn and practice with digitization. The results will make the Libraries more informed and better educated and thus empower us to make higher quality decisions in the future.