





PTPBio and the Reader
Posted on May 6, 2021 in Distant Reader by Eric Lease Morgan [The following missive was written via an email message to a former colleague, and it is a gentle introduction to Distant Reader “study carrels”. –ELM]
[The following missive was written via an email message to a former colleague, and it is a gentle introduction to Distant Reader “study carrels”. –ELM]
On another note, I see you help edit a journal (PTPBio), and I used it as a case-study for a thing I call the Distant Reader.
The Distant Reader takes an arbitrary amount of text as input, does text mining and natural language processing against it, saves the result as a set of structured data, writes a few reports, and packages the whole thing into a zip file. The zip file is really a data set, and Distant Reader data sets are affectionately called “study carrels”. I took the liberty of applying the Reader process to PTPBio, and the result has manifested itself in a number of ways. Let me enumerate them. First, there is the cache of the original content;
Next, there are plain text versions of the cached items. These files are used for text mining, etc.:
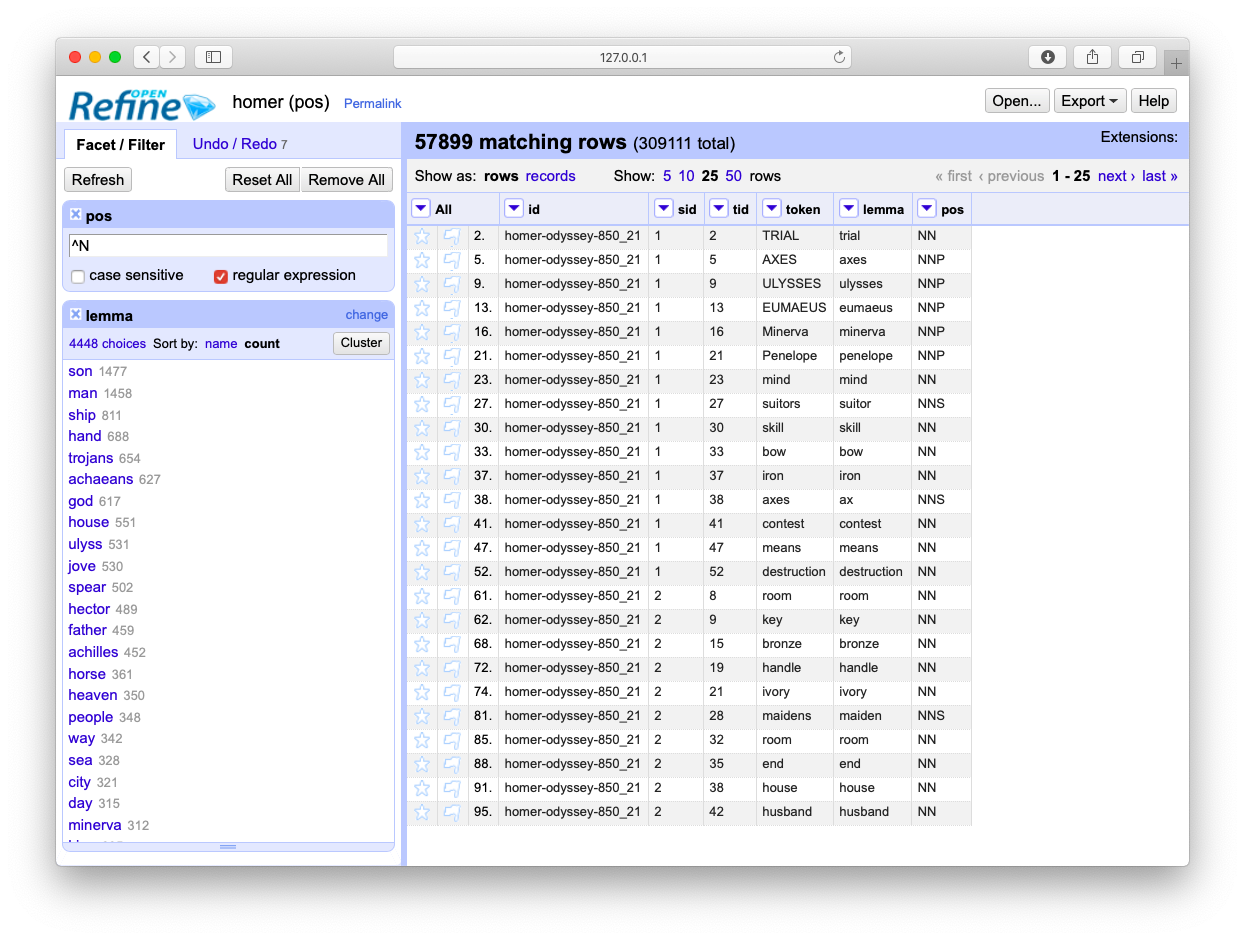
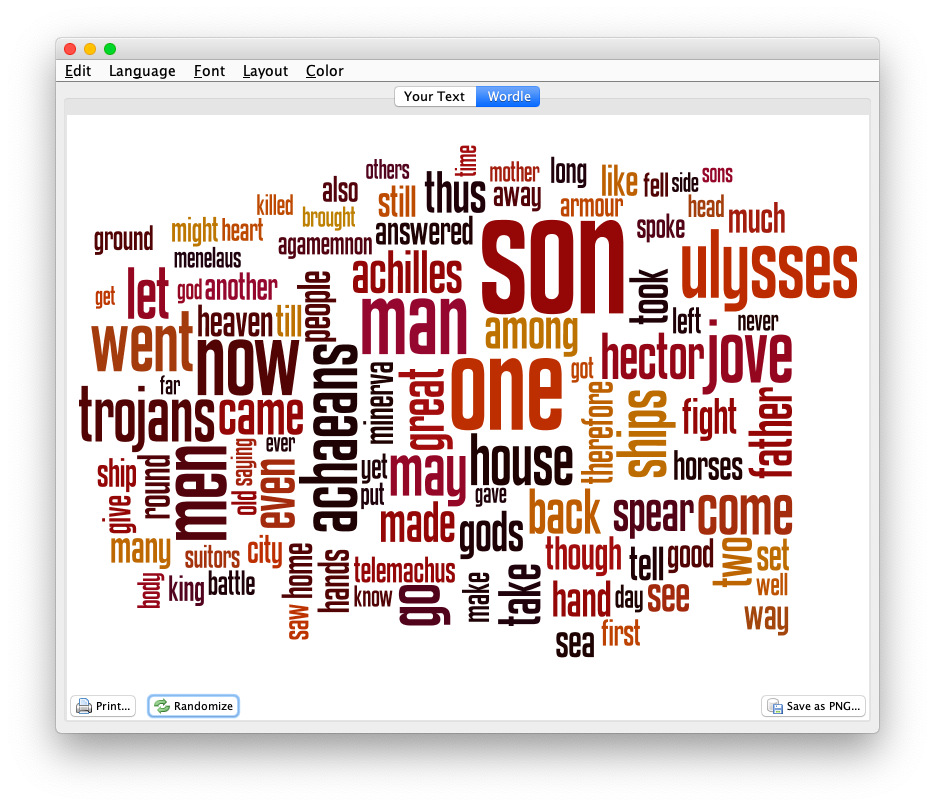
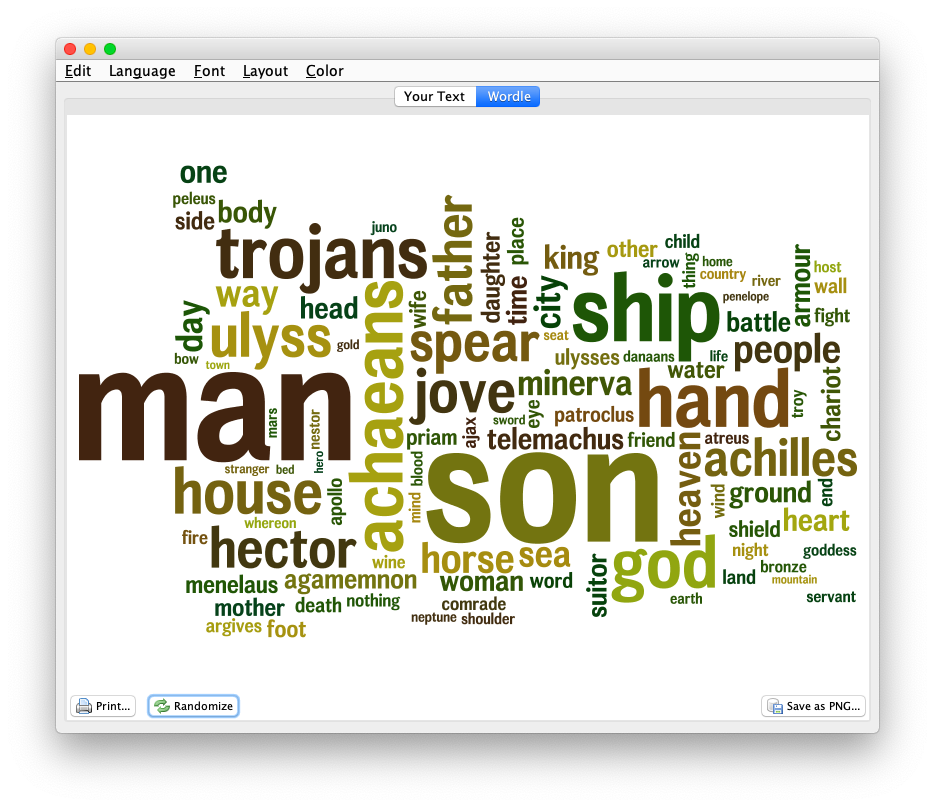
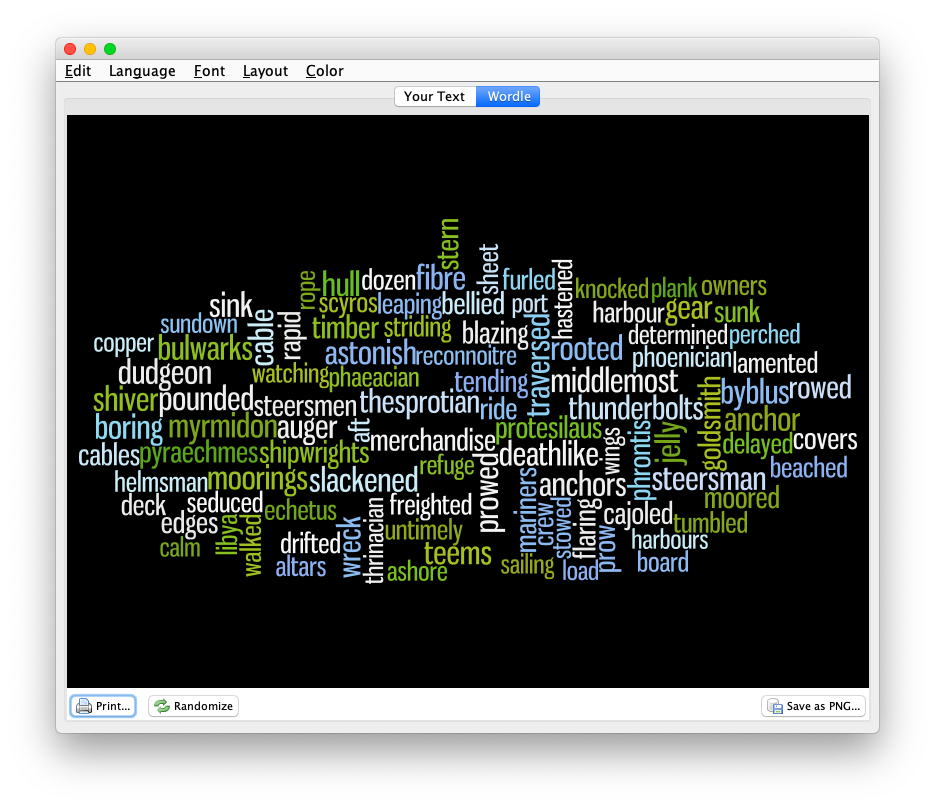
The Reader does many different things against the plain text. For example, the Reader enumerates and describes each and every token (“word”) in each and every document. The descriptions include the word, its lemma, is part-of-speech, and its location in the corpus. Each plain text file is really a tab-delimited file easily importable into your favorite spreadsheet or database program:
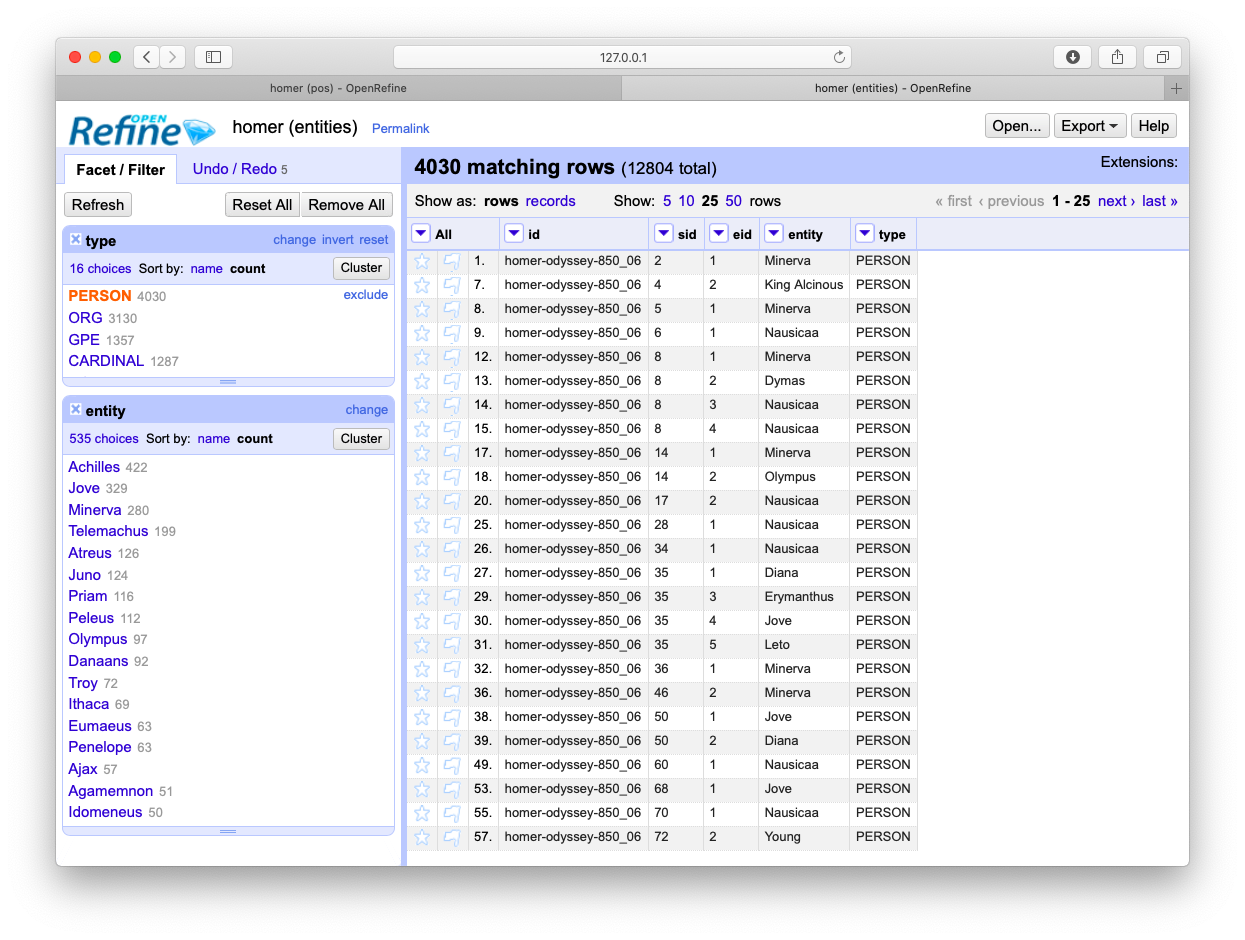
Similar sets of files are created for named entities, URLs, email addresses, and statistically significant keywords:
- https://library.distantreader.org/backroom/journal-ptpbio/ent/
- https://library.distantreader.org/backroom/journal-ptpbio/adr/
- https://library.distantreader.org/backroom/journal-ptpbio/urls/
- https://library.distantreader.org/backroom/journal-ptpbio/wrd/
All of this data is distilled into a (SQLite) database file, and various reports are run against the database. For example, a very simple and rudimentary report as well as a more verbose HTML report:
- https://library.distantreader.org/backroom/journal-ptpbio/standard-output.txt
- https://library.distantreader.org/backroom/journal-ptpbio/index.htm
All of this data is stored in a single directory:
Finally, the whole thing is zipped up and available for downloading. What is cool about the download is that it is 100% functional on your desktop as it is on the ‘Net. The study carrels does not require the ‘Net to be operational; study carrels are manifested as plain text files, are stand-alone items, and will endure the test of time:
“But wait. There’s more!”
It is not possible for me to create a Web-based interface empowering students, researchers, or scholars to answer any given research question. There are too many questions. On the other hand, since the study carrels are “structured”, one can write more sophisticated applications against the data. That is what the Reader Toolbox and Reader (Jupyter) Notebooks are for. Using the Toolbox and/or the Notebooks the student, researcher, or scholar can do all sorts of things:
- download carrels from the Reader’s library
- extract ngrams
- do concordancing
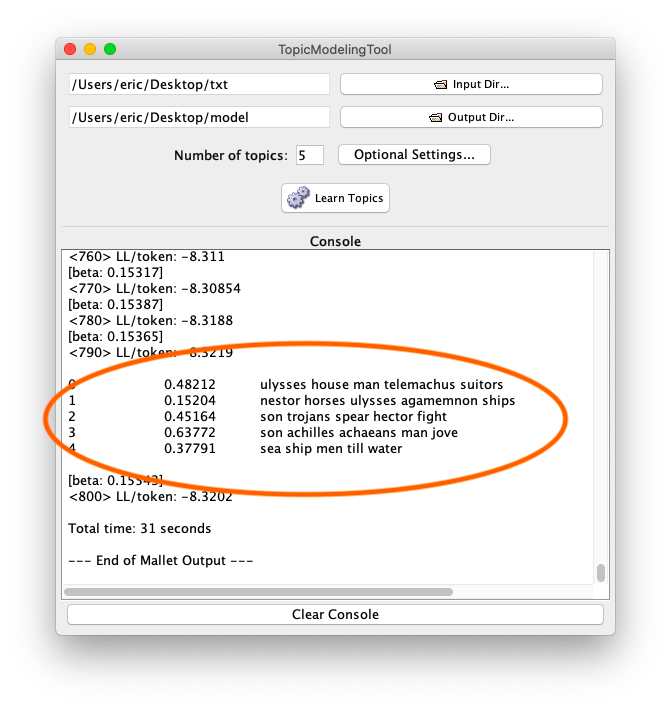
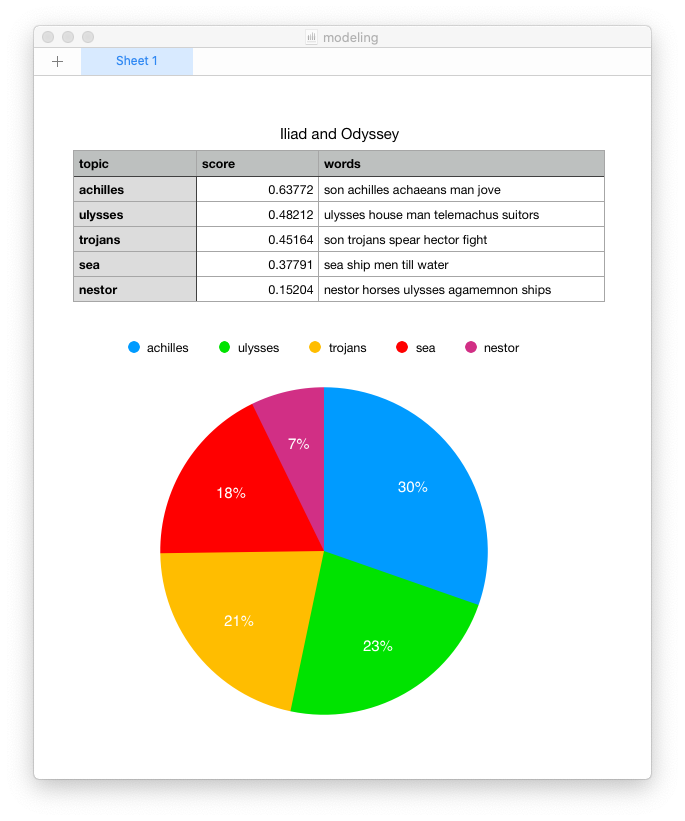
- do topic modeling
- create a full text index
- output all sentences containing a given word
- find all people, use the ‘Net to get birth date and death dates, and create a timeline
- find all places, use the ‘Net to get locations, and plot a map
- articulate an “interesting” idea, and illustrate how that idea ebbed & flowed over time
- play hangman, do a cross-word puzzle, or plat a hidden word search game
Finally, the Reader is by no means perfect. “Software is never done. If it were, then it would be called ‘hardware’.” Ironically though, the hard part about the Reader is not interpreting the result. The hard part is two other things. First, in order to use the Reader effectively, a person needs to have a (research) question in mind. The question can be as simple as “What are the characteristics of the given corpus?” Or, they can be as sublime as “How does St. Augustine define love, and how does his definition differ from Rousseau’s?”
Just as difficult it the creation of the corpus to begin with. For example, I needed to get just the PDF versions of your journal, but the website (understandably) is covered with about pages, navigation pages, etc. Listing the URLs of the PDF files was not difficult, but it was a bit tedious. Again, that is not your fault. In fact, your site was (relatively) easy. Some places seem to make it impossible to get to the content. (Sometimes I think the Internet is really one huge advertisement.)
Okay. That was plenty!
Your journal was a good use-case. Thank you for the fodder.
Oh, by the way, the Reader is located at https://distantreader.org, and it available for use by anybody in the world.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}