





EEBO-TCP Workset Browser
Posted on June 11, 2015 in Uncategorized by Eric Lease MorganI have begun creating a “browser” against content from EEBO-TCP in the same way I have created a browser against worksets from the HathiTrust. The goal is to provide “distant reading” services against subsets of the Early English poetry and prose. You can see these fledgling efforts against a complete set of Richard Baxter’s works. Baxter was an English Puritan church leader, poet, and hymn-writer. [1, 2, 3]
 EEBO is an acronym for Early English Books Online. It is intended to be a complete collection of English literature between 1475 through to 1700. TCP is an acronym for Text Creation Partnership, a consortium of libraries dedicated to making EEBO freely available in the form of XML called TEI (Text Encoding Initiative). [4, 5]
EEBO is an acronym for Early English Books Online. It is intended to be a complete collection of English literature between 1475 through to 1700. TCP is an acronym for Text Creation Partnership, a consortium of libraries dedicated to making EEBO freely available in the form of XML called TEI (Text Encoding Initiative). [4, 5]
The EEBO-TCP initiative is releasing their efforts in stages. The content of Stage I is available from a number of (rather hidden) venues. I found the content on a University Michigan Box site to be the easiest to use, albiet not necessarily the most current. [6] Once the content is cached — in the fullest of TEI glory — it is possible to search and browse the collection. I created a local, terminal-only interface to the cache and was able to exploit authority lists, controlled vocabularies, and free text searching of metadata to create subsets of the cache. [7] The subsets are akin to HathiTrust “worksets” — items of particular interest to me.
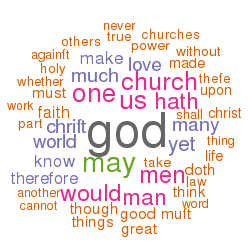
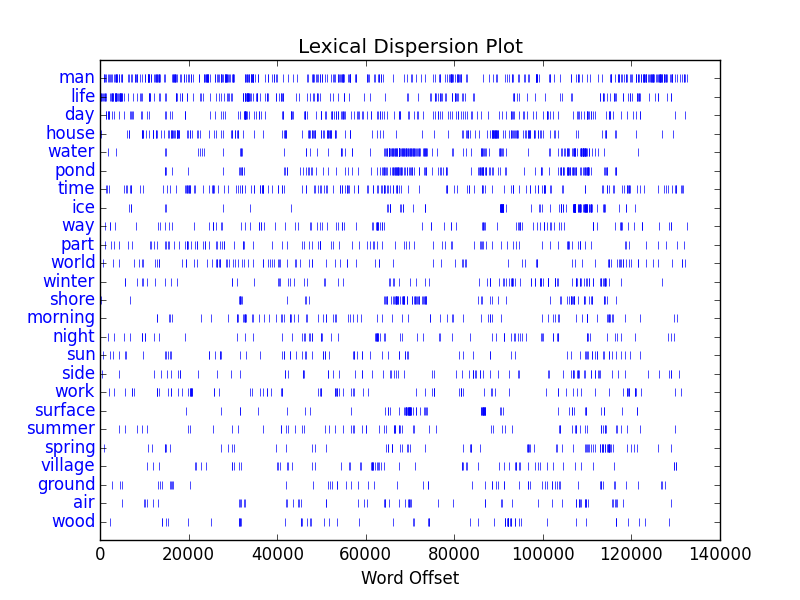
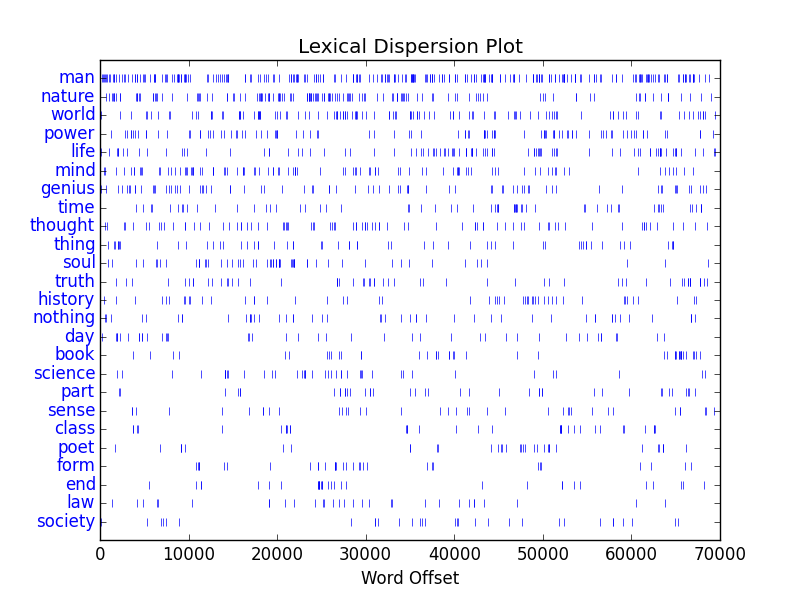
Once a subset was identified, I was able to mirror (against myself) the necessary XML files and begin to do deeper analysis. For example, I am able to create a dictionary of all the words in the “workset” and tabulate their frequencies. Baxter used the word “god” more than any other, specifically, 65,230 times. [8] I am able to pull out sets of unique words, and I am able to count how many times Baxter used words from three sets of locally defined “lexicons” of colors, “big” names, and “great” ideas. Furthermore, I am be to chart and graph trends of the works, such as when they were written and how they cluster together in terms of word usage or lexicons. [9, 10]
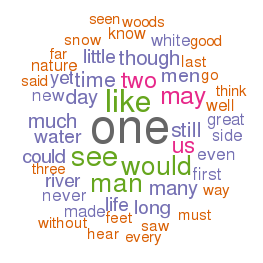
I was then able to repeat the process for other subsets, items about: lutes, astronomy, Unitarians, and of course, Shakespeare. [11, 12, 13, 14]
The EEBO-TCP Workset Browser is not as mature as my HathiTrust Workset Browser, but it is coming along. [15] Next steps include: calculating an integer denoting the number of pages in an item, implementing a Web-based search interface to a subset’s full text as well as metadata, putting the source code (written in Python and Bash) on GitHub. After that I need to: identify more robust ways to create subsets from the whole of EEBO, provide links to the raw TEI/XML as well as HTML versions of items, implement quite a number of cosmetic enhancements, and most importantly, support the means to compare & contrast items of interest in each subset. Wish me luck?
More fun with well-structured data, open access content, and the definition of librarianship.
- Richard Baxter (the person) – http://en.wikipedia.org/wiki/Richard_Baxter
- Richard Baxter (works) – http://bit.ly/ebbo-browser-baxter-works
- Richard Baxter (analysis of works) – http://bit.ly/eebo-browser-baxter-analysis
- EEBO-TCP – http://www.textcreationpartnership.org/tcp-eebo/
- TEI – http://www.tei-c.org/
- University of Michigan Box site – http://bit.ly/1QcvxLP
- local cache of EEBO-TCP – http://bit.ly/eebo-cache
- dictionary of all Baxter words – http://bit.ly/eebo-browser-baxter-dictionary
- histogram of dates – http://bit.ly/eebo-browser-baxter-dates
- clusters of “great” ideas – http://bit.ly/eebo-browser-baxter-cluster
- lute – http://bit.ly/eebo-browser-lute
- astronomy – http://bit.ly/eebo-browser-astronomy
- Unitarians – http://bit.ly/eebo-browser-unitarian
- Shakespeare – http://bit.ly/eebo-browser-shakespeare
- HathiTrust Workset Browser – https://github.com/ericleasemorgan/HTRC-Workset-Browser
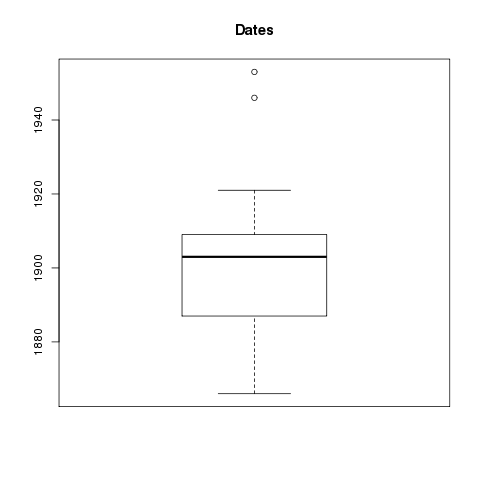
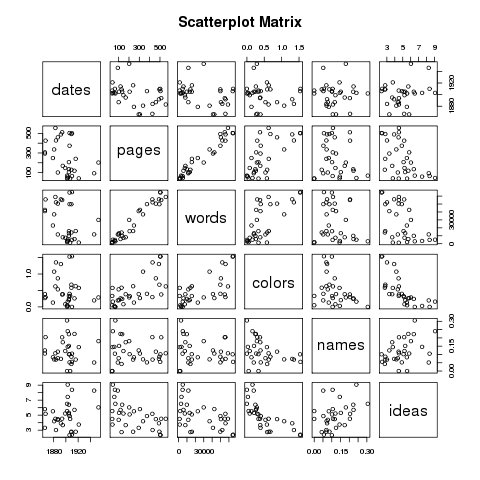
 I used the repository on Box to get my content, and I mirrored it locally. [1, 2] I then looped through the content using XPath to extract rudimentary metadata, thus creating a “catalog” (index). Along the way I calculated the number of words in each document and saved that as a field of each “record”. Being a tab-delimited file, it is trivial to import the catalog into my favorite spreadsheet, database, editor, or statistics program. This allowed me to browse the collection. I then used grep to search my catalog, and save the results to a file. I searched for Richard Baxter. [6, 7, 8]. I then used an R script to graph the numeric data of my search results. Currently, there are only two types: 1) dates, and 2) number of words. [9, 10, 11, 12] From these graphs I can tell that Baxter wrote a lot of relatively short things, and I can easily see when he published many of his works. (He published a lot around 1680 but little in 1665.) I then transformed the search results into a browsable HTML table. The table has hidden features. (Can you say, “Usability?”) For example, you can click on table headers to sort. This is cool because I want sort things by number of words. (Number of pages doesn’t really tell me anything about length.) There is also a hidden link to the left of each record. Upon clicking on the blank space you can see subjects, publisher, language, and a link to the raw XML.
I used the repository on Box to get my content, and I mirrored it locally. [1, 2] I then looped through the content using XPath to extract rudimentary metadata, thus creating a “catalog” (index). Along the way I calculated the number of words in each document and saved that as a field of each “record”. Being a tab-delimited file, it is trivial to import the catalog into my favorite spreadsheet, database, editor, or statistics program. This allowed me to browse the collection. I then used grep to search my catalog, and save the results to a file. I searched for Richard Baxter. [6, 7, 8]. I then used an R script to graph the numeric data of my search results. Currently, there are only two types: 1) dates, and 2) number of words. [9, 10, 11, 12] From these graphs I can tell that Baxter wrote a lot of relatively short things, and I can easily see when he published many of his works. (He published a lot around 1680 but little in 1665.) I then transformed the search results into a browsable HTML table. The table has hidden features. (Can you say, “Usability?”) For example, you can click on table headers to sort. This is cool because I want sort things by number of words. (Number of pages doesn’t really tell me anything about length.) There is also a hidden link to the left of each record. Upon clicking on the blank space you can see subjects, publisher, language, and a link to the raw XML.

 I have put my (fledgling) HathiTrust Workset Browser on GitHub. Try:
I have put my (fledgling) HathiTrust Workset Browser on GitHub. Try:




{kind=link}
{kind=link}
{kind=link}
{kind=link}