This tutorial is for those of you who want to learn some basic programming in Python for the digital humanities, but also for those who have never programmed or may become filled with terror at the sight of a single line of code (trust me, I know the feeling!). At the end of this guide, you should know how to perform optical character recognition (OCR) to make a pdf searchable. For this, we are going to use “ocrmypdf”, a Tesseract-based Python package with wonderful capabilities. Everything will be done online from your web browser, so don’t worry, you will not have to install anything on your computer!
I have tried to keep the tutorial very simple and straight to the point, at the cost of occasionally sacrificing some useful and important explanations about the code. For that, I profusely apologize to my colleagues in the department of computer science. Please, do not send the Spanish Inquisition.
The name “Python” is a tribute to Monty Python (please excuse the poor joke).
Why Tesseract and ocrmypdf?
Some of you may be familiar with, or even regular users of the OCR function provided by Adobe Acrobat DC pro. The ctrl+f function is one of the simplest and most efficient tools to support analysis of text and research. Acrobat DC is a powerful and very easy to use software, but this comes at a price. First, Acrobat works only with a handful of common modern languages such as English, French, German or Japanese. Tesseract on the other hand can recognize characters from a broad variety of modern and classical languages, including, but not limited to, Armenian, Classical Arabic, Classical Greek, Syriac, and Old Georgian, to name only a few. Second, Tesseract is a free, and open-source software, presenting a more cost-efficient option compared to other expensive commercial options and I am sure many of you would rather settle for the free but equally powerful alternative.
This is a free Jupyter notebook that will save your data on your personal google drive. Just remember to hit the save button before closing the page.
Open a new notebook and sign up with a Gmail address. You will want to use your @nd.edu address but any personal google account will work too.
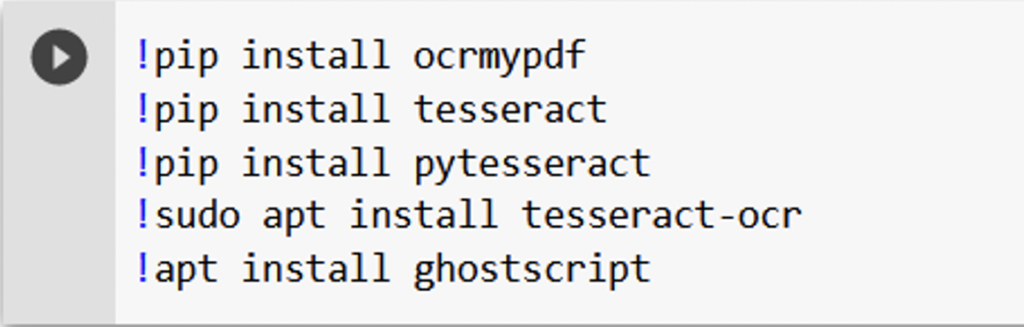
As a first step, we need to download ocrmypdf, and all its dependencies. To do so, simply type the following lines. The first will download the python package ocrmypdf, while the other lines will deal with the dependencies. For those of you new to coding, you will learn the first rule of coding: any errors in spelling, indentation and so forth can break your code. Be careful!
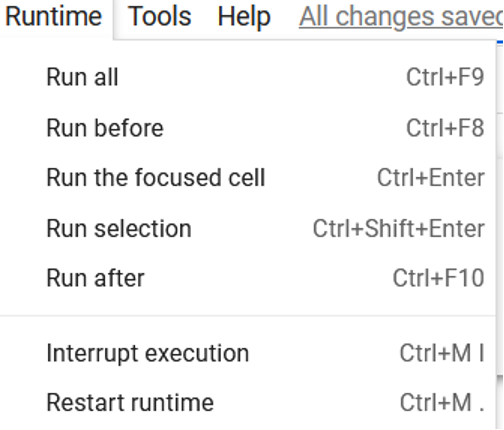
When the above lines have been written, run the cell by pressing ctrl+enter or press the button in the upper left corner. The download process should take around a minute. Once the download is complete, you should see a little green tick next to the upper left arrow.
Once the package and its dependencies have been downloaded, we will need to import “ocrmypdf” so that we can put it to work. Add a line of code to your colab sheet by clicking on + Code and write the following code:
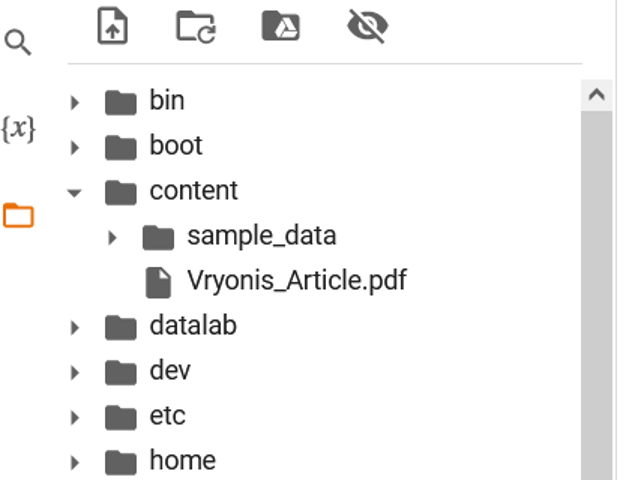
Next, add a copy of your scanned pdf to the “files/content” folder on the left side of your screen (or any other folder of your choice, you will just have to note its path somewhere). In our case, we are going to work with the first page of an article on the Mevlevi Sufi order published by the Byzantinist Speros Vryonis Junior.
In a new cell, enter the following lines of code (beware, the underscores are double underscores!).
Here, the name on the left should be that of the file you want to ocr (or its path if put in another folder), the one on the right should be that of the new, postprocessed file. The code uses the exact name of the file, ‘Vryonis_Article.pdf’. You can keep the exact same name if you want the new file to overwrite the original one. In my case, my code is directing ocrmypdf to create a new file: ‘Vryonis_Article_OCR.pdf’. Once generated, the post-processed article should appear in the same folder.
If you ever get an error, simply restart the runtime before running the cell again.
Et voila! You can now search your pdf with ctrl+F or copy and paste any sentence you want.
But this is not the most exciting part of this tutorial, and we may want to spice things up a little bit. Tesseract is very good at OCRing (yes, this is a verb, at least according to the WordSense dictionary) non-Latin scripts, but the process is a bit more involved. As an example, let’s take a page from the Masālik al-abṣārfīmamālik al-amṣār written in the 14th century by the Syrian polymath al-ʿUmarī.
And here we are. Those who can read Arabic will notice that the result is extremely impressive. This, however, is a rather neat scan and Arabic is often difficult to properly OCR because of the cursive nature of the script. If the quality of your scan is poor, you may also be able to clean it with Python beforehand for a better result. I may develop this point further in another post.
Beyond Arabic, Tesseract works very well with other non-cursive Semitic scripts, and you may get excellent results with Hebrew for example. Here is a last example from a Syriac Bible.
If you have any questions or comments about this guide, feel free to contact me.
Today’s blog continues from last week’s discussion of the Nasrid College and the multicultural exchange it fostered in Medieval Iberia by shifting the focus to the intellectual and political.
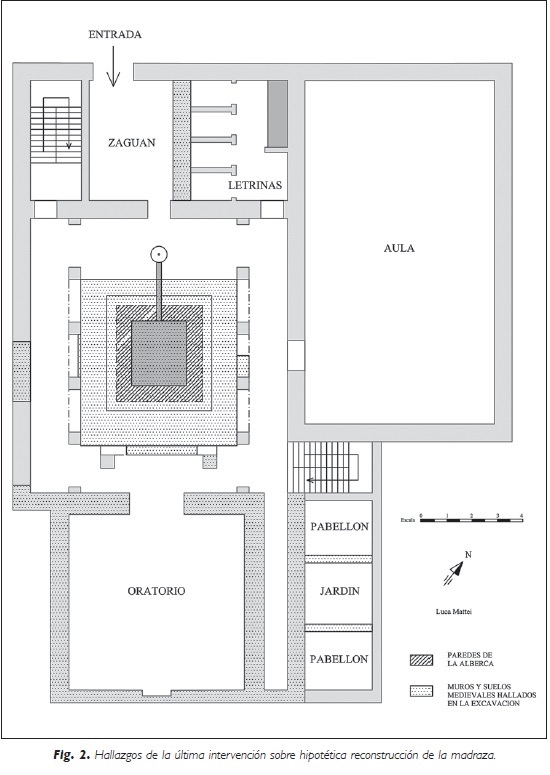
In Muḥarram 750/April 1349, the Nasrid College, located directly across from the former Great Mosque of Granada (today the cathedral) and near the main market, was completed.[1] It reflected the intersection between knowledge and power, cosmopolitanism and learning, in Nasrid Granada. Although the Nasrid College was certainly the most significant example of an Andalusi madrasah during the Middle Ages, the Granadan scholar-statesman and historian Lisān al-Dīn ibn al-Khaṭīb (d. 1374) states that “the admirable college was constructed during the reign of Yūsuf and was the most illustrious of all the colleges in his capital,” indicating that there may have been other such colleges in the kingdom.[2] The Nasrid College sought to establish the preeminence of the Granada as a leading intellectual and cultural center in the Islamic West. Its prominence reflected the transformation of Granada from an embattled frontier polity into a major center of learning in the Islamic West, competing with other intellectual centers such as Fez, Tlemcen, Tunis, Marrakesh and Meknes. Although law, Arabic grammar, and theology constituted the integral components of the curriculum, the subjects taught at the Nasrid College encompassed both the “traditional sciences” (al-‘ulūm al-naqliyyah) as well as the “philosophical sciences” (al-‘ulūm al-‘aqliyyah), and included jurisprudence, logic, medicine, astronomy, philosophy, mathematics, arithmetic, and geometry. Some of these subjects would also be studied with professors from the Nasrid College in other spaces in Granada, including the home and chancery. The students and teachers at the Nasrid College included some of the greatest luminaries from al-Andalus as well as North Africa during the 14th and 15th centuries. The Nasrid College contained a significant library that housed many of the most important works produced in the late medieval Islamic West, as well as many books from across the Islamic world. According to a note by the 15th-century Andalusi scholar Abū ‘Abd Allāh Muḥammad b. al-Ḥaddād al-Wādī Āshī, for example, an ornamented and calligraphic manuscript of the monumental “Comprehensive History of Granada” (al-Ihāṭah fī Akhbār Gharnāṭah, authored by Ibn al-Khaṭīb) was deposited in the library of Nasrid College during the reign of Muḥammad V (r. 1354-1359, 1362-1391), where it remained as an endowment (taḥbīs), and was consulted by subsequent generations of scholars.
Details of the miḥrāb of the Nasrid College. Photo by Mohamad Ballan.
Following the Iberian Christian conquest of Granada in 1492, the Nasrid College survived largely intact, until much of it was demolished during the early 18th century to make way for a new Baroque structure. Although only the prayer niche (miḥrāb) and the Oratory of the Following the Iberian Christian conquest of Granada in 1492, the Nasrid College survived largely intact, until much of it was demolished during the early 18th century to make way for a new Baroque structure. Although only the prayer niche (miḥrāb) and the Oratory of the Nasrid College survives to the present day, recent studies by historians and archaeologists have sought to reconstruct the original structure, which included a monumental gate and pool.
Bilal Sar and Luca Mattei. “La Madraza Yusufiyya en época andalusí: un diálogo entre las fuentes árabes escritas y arqueológicas,” Arqueología y Territorio Medieval 16 (2009), p. 73.
The survival of several contemporary Marinid colleges in North Africa, including those in Fez, Meknes, and Salé built during the 1340s and 1350s, may also provide an idea of both the scale and style of the Nasrid College.
College of Abū al-Ḥasan ‘Alī in Salé, Morocco, completed around 1341. Source: Wikimedia. Miḥrāb, or prayer niche, of the College of Abū al-Ḥasan ‘Alī in Salé, Morocco. Source: Wikimedia.Bou Inania Madrasa, Fez. Photo by Mohamad Ballan.Bou Inania Madrasa, Fez. Photo by Mohamad Ballan.Bou Inania Madrasa, Fez. Photo by Mohamad Ballan.Bou Inania Madrasa in Meknes, built in the 1350s. Photo by Mohamad Ballan.Bou Inania Madrasa in Meknes, built in the 1350s. Photo by Mohamad Ballan.Bou Inania Madrasa in Meknes, built in the 1350s. Photo by Mohamad Ballan.
Like the monumental colleges constructed by Marinid rulers in North Africa, especially Abū al-Ḥasan ‘Alī (r. 1331–1348) and Abū ‘Inān (1348–1358), this structure was intended to c
Like the monumental colleges constructed by Marinid rulers in North Africa, especially Abū al-Ḥasan ‘Alī (r. 1331–1348) and Abū ‘Inān (1348–1358), this structure was intended to celebrate the elaborate wealth and power of the sovereign, while proclaiming his commitment to knowledge. There are remarkable architectural and artistic similarities between the Nasrid College and other royal monuments in Granada, including the Alhambra, as well as with Marinid colleges in North Africa, particularly the College of Abū al-Ḥasan ‘Alī in Salé, which was built several years earlier. Similar to the Marinid colleges, the verses inscribed on the walls of the Nasrid College, which were preserved in medieval and early modern texts, were authored by leading scholars, litterateurs and courtiers. These celebrated the patronage of learning by Yūsuf I, and illustrate the interrelationship between royal power and learned elites in the Nasrid kingdom.[3]
Nasrid dynastic slogan—“There is no Conqueror except God” (wa lā ghālib illā Llāh)—inscribed on the prayer niche of the Nasrid College. Photo by Mohamad Ballan.Another instance of the Nasrid dynastic slogan—“There is no Conqueror except God” (wa lā ghālib illā Llāh)—inscribed on the prayer niche of the Nasrid College. Photo by Mohamad Ballan.
In addition to reflecting a shared idiom of sovereignty and learned kingship across both Islamic Spain and North Africa, the similarities between these colleges, which were built within several years of one another, provides an important indication of the cultural and artistic exchange across the Islamic West. It also illustrates the role of interregional connections in strengthening the ties of affiliation and the diffusion of institutions between Iberia and North Africa during this period. Itinerant scholars, administrators and artisans served as cultural intermediaries and conduits for the exchange of ideas and institutions between Nasrid Granada and Marinid Morocco. The Nasrid College was merely one illustration of this broader phenomenon.
While the College came to be known in later sources as al-Madrasa al-Yūsufiyya or “The College of Yūsuf,” and came to be associated with the name of Yūsuf I (r. 1333-1354), it was in fact the creation of Abū Nu‘aym Riḍwān al-Naṣrī (d. 1359), this Nasrid sovereign’s royal chamberlain.[4] Abū Nu‘aym Riḍwān was a prominent example of a particular class of Nasrid society that modern scholarship has referred to as “renegades,” enslaved people and freedmen and their descendants who were an integral part of Granada’s population. Riḍwān was born into a Castilian Christian family in Calzada de Calatrava before being enslaved as a child during a Nasrid raid in the late 13th century. Following his captivity, he was converted to Islam and manumitted, received an education in the Nasrid court, and eventually appointed to leading positions of executive authority, including royal chamberlain, chief minister and commander of the military. The rise to prominence of Riḍwān during this period is also corroborated by contemporary Castilian and Aragonese sources, including the Crónica de Alfonso XI, which describes him as “a Muslim knight known as Reduan, the son of a Christian man and Christian woman, whom the king of Granada trusted immensely (un cavallero moro que dezian Reduan que fuera fijo de christiano e de christiana e era ome quien fiava mucho el rey).”[5] There is substantial evidence that Riḍwān served as an intermediary with the Iberian Christian kingdoms, and corresponded directly with Alfonso IV (r. 1327–1336) and Pedro IV (r. 1336–1387) of Aragón in order to secure a peace treaty between the Nasrids and Aragón. In these documents, four of which have been preserved in the Archivo de la Corona de Aragón, Riḍwān consistently refers to himself as “Riḍwān, son of God’s servant, the chief minister of the Sultan” (Riḍwān ibn ‘Abd Allāh wazīr al-sulṭān).
Signature of Abū Nu‘aym Riḍwān on surviving document produced by the Nasrid chancery during the 1330s.Signature of Abū Nu‘aym Riḍwān on surviving document produced by the Nasrid chancery during the 1330s.Signature of Abū Nu‘aym Riḍwān on surviving document produced by the Nasrid chancery during the 1330s
Fragments of the foundation inscription of the Nasrid College. Source: andalfarad.com.Details of the miḥrāb of the Nasrid College. Photo by Mohamad Ballan.
This concerted program of urban expansion and elaborate construction in Granada during the 14th century was accomplished through the close collaboration between the secretarial class, nobles, artisans, and craftsmen. The establishment of the Nasrid College and its transformation into one of the most important institutions of learning in Granada was made possible by the close relationship between the sovereign, leading statesmen such as Riḍwān and the various secretaries and functionaries within the Nasrid chancery. The construction of the Nasrid College and the circumstances surrounding it demonstrate that, far from being a period of “intellectual decline,” the 14th and 15th centuries in the Islamic West witnessed the emergence of a rigorous scholarly culture that produced brilliant individuals and prolific scholars. The Nasrid College, which has now become the subject of numerous interdisciplinary studies that have included historians, philologists, and archaeologists, has the potential to shed light on this larger cultural renaissance.
Ceiling of the Oratory of the Nasrid College, Granada. Source: flickr.com
Mattei, Luca. “Estudio de la Madraza de Granada a partir del registro arqueológico y de las metodologías utilizadas en la intervención de 2006.” Arqueología y Territorio 5 (2008): 181-192
Prado García, Celia. “Los estudios superiores en las madrazas de Murcia y Granada. Un estado de la cuestión.” Murgetana 139 (2018): 9-21.
Rodríguez-Mediano, Fernando. “The Post-Almohad Dynasties in al-Andalus and the Maghrib.” In The New Cambridge History of Islam, Volume II: The Western Islamic World, Eleventh to Eighteenth Centuries, edited by Maribel Fierro, pp. 106–143. Cambridge: Cambridge University Press, 2012.
Rubiera Mata, María Jesús. “Datos sobre una ‘Madrasa’ en Málaga anterior a la Naṣrí de Granada.” Al-Andalus 35 (1970): 223–226
Sarr, Bilal and Luca Mattei. “La Madraza Yusufiyya en época andalusí: un diálogo entre las fuentes árabes escritas y arqueológicas.” Arqueología y Territorio Medieval 16 (2009): 53–74.
Secall, M. Isabel Calero. “Rulers and Qādīs: Their Relationship during the Naṣrid Kingdom.” Islamic Law and Society 7 (2000): 235–255
Seco de Lucena Paredes, Luis. “El Ḥāŷib Riḍwān, la madraza de Granada y las murallas del Albayzín.” Al-Andalus 21 (1956): 285–296.
[1] The most important scholarship about the Nasrid College includes La Madraza: pasado, presente y futuro (Granada: Editorial Universidad de Granada, 2007), eds. Rafael López Guzmán and María Elena Díez Jorge; La Madraza de Yusuf I y la ciudad de Granada: análisis a partir de la arqueología (Granada: Editorial Universidad de Granada, 2015), eds. Antonio Malpica Cuello and Luca Mattei.
[2] Ibn al-Khatīb, al-Lamḥa al-Badriyya fī al-Dawla al-Naṣriyya (Kuwait, 2013), p. 153. For a discussion of an earlier college built in the Nasrid kingdom, see María Jesús Rubiera Mata, “Datos sobre una ‘Madrasa’ en Málaga anterior a la Naṣrí de Granada,” Al-Andalus 35 (1970), pp. 223–226.
[5] Fernán Sánchez de Valldolid, Crónica de Alfonso XI, BN MS 829, ff. 190r–190v.
[6] For a comprehensive study of awqāf in al-Andalus, see Alejandro García-Sanjúan, Till God inherits the Earth: Islamic Pious Endowments in al-Andalus (9-15th centuries) (Leiden: Brill, 2007).
For Spain and North Africa, the late medieval period (ca. 1250-1500) was a tumultuous era that was characterized by political turmoil and mass violence. It was also the period that witnessed one of the greatest bursts of cultural efflorescence, intellectual creativity and administrative-political innovation in the region. During the fourteenth and fifteenth centuries, the cities of Toledo, Seville, Granada, Fez and Tunis, not unlike the city-states of Renaissance Italy during the same period, produced some of the most remarkable scholars and intellectuals in the history of the Western Mediterranean, despite the numerous challenges of the era. It was also the period that witnessed the rise of some of the most remarkable pieces of architecture in the region. One of the most iconic monuments associated with this period is the Alhambra, the royal and administrative center of the Nasrid kingdom of Granada between the 13th and 15th centuries. Since the Middle Ages, there has been no shortage of interest in this palace-fortress complex, its monumental scale and its exquisite craftsmanship.[1]
Alhambra, Granada. Source: Wikimedia.
The history of another architectural and cultural gem from 14th-century Granada, which remains relative little-known beyond a small circle of specialists, is concealed behind an 18th-century Baroque façade behind the Great Cathedral of Granada: the Nasrid College (al-madrasah al-naṣriyyah), constructed in April 1349.
Baroque exterior of Palacio de la Madraza, Granada. Photo by Mohamad Ballan.Oratory of the Nasrid College. Source: caminandogranada.com.Oratory of the Nasrid College. Photo by Mohamad Ballan.
The Nasrid College was a rare example of a madrasah constructed in medieval al-Andalus (Muslim Iberia).[2] This structure, which was only excavated and restored over the past several decades and finally opened to the public in 2011, provides important insights into the intellectual, social and political history of Nasrid Granada during the 14th century. This short post seeks to provide an overview of the emergence of the Nasrid College, with particular attention to the cultural, political and intellectual context in which it emerged.
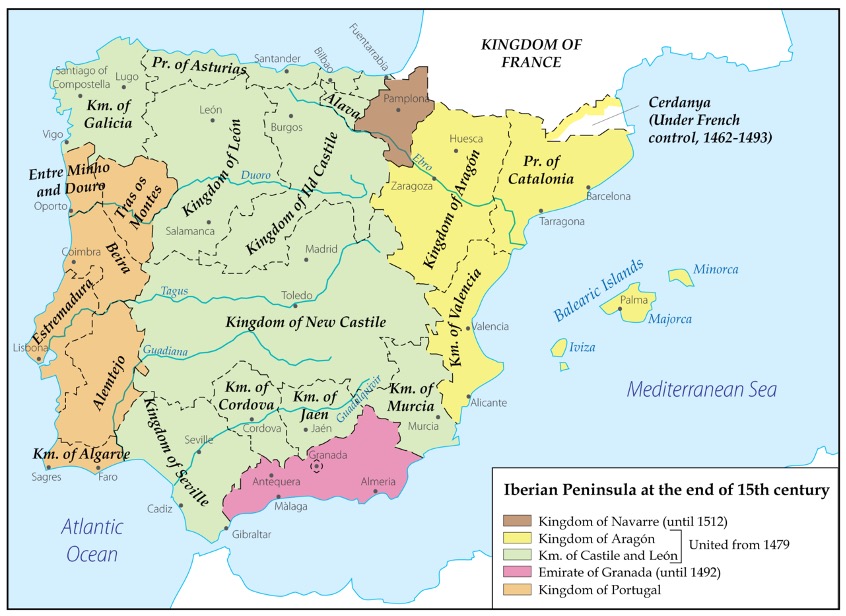
Nasrid Granada, the last surviving Muslim polity in medieval Iberia, was a borderland city-state entrenched in the farthest reaches of the Islamic world, between Europe and North Africa, yet closely connected and integrated within both Latin Christendom and the Islamic world. The Muslim-Christian borderlands during this period were characterized by intermittent frontier warfare and shifting alliances between Nasrid and Castilian rulers, the emergence of a bilingual nobility (conversant in Romance as well as Arabic), and the permeability of the frontier, which facilitated the passage and migration of mercenaries and merchants, renegades and refugees, scholars and slaves between the Islamic world and Latin Christendom.
Medieval Iberia, ca. 1470. Source: mapsontheweb.zoomNasrid Kingdom of Granada, 1238-1492. Source Wikimedia.
Over the past several decades, there has been a substantial body of scholarship that has treated various aspects of the political, intellectual, cultural and social history of Nasrid Granada demonstrating the various ways that this polity and its inhabitants were shaped by this broader borderland context.[3] By the 14th century, the Kingdom of Granada encompassed one of the most urban and diverse populations in late medieval Iberia. The mass migration of thousands of Andalusi Muslims to Granada in the wake of the Castilian, Portuguese and Aragonese conquest of Islamic Spain transformed it from a regional urban center into a thriving metropolis and one of the largest cities in the western Islamic world.
Recent studies have challenged the conventional narrative of Nasrid decline and isolation by illustrating Granada’s integration into the extensive intellectual, mercantile, commercial and diplomatic networks that characterized the late medieval Mediterranean world. The various communities of Christian merchants and mercenaries, particularly from Genoa, Castile and Aragón, [4] that were established across the Nasrid kingdom between the 13th and 15th centuries often served as cultural intermediaries and conduits for the circulation and exchange of ideas between Latin Christendom and the Islamic West. The population of Nasrid Granada was characterized by social and cultural heterogeneity. The Andalusi Muslims who comprised the majority of the kingdom’s roughly 250,000–300,000 inhabitants were themselves descendants of communities from diverse geographic, social and ethnic backgrounds from across the Iberian Peninsula (and beyond), the consequence of centuries of acculturation, conversion and migration in the region. Granada was also home to various Jewish communities, and significant contingents of North African “holy warriors” (ghuzāh) and their families, who played an important role in Nasrid society and politics.
[1] Olivia Remie Constable, Housing the Stranger in the Mediterranean World: Lodging, Trade, and Travel in Late Antiquity and the Middle Ages (Cambridge, 2003), 248-249, 297-298, 302-303; Roser Salicrú i Lluch, “The Catalano-Aragonese Commercial Presence in the Sultanate of Granada during the Reign of Alfonso the Magnanimous,” Journal of Medieval History 27 (2001), 289-312.
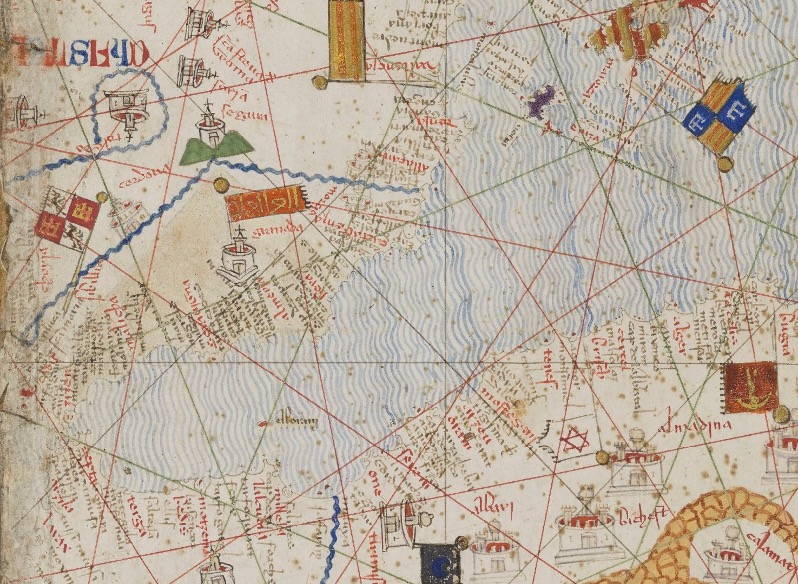
Nasrid Granada as depicted on the Catalan Atlas, 1375. BnF Espagnol 30.Nasrid Granada as depicted on the Catalan Atlas, 1375. BnF Espagnol 30.
The Nasrid College was shaped by this dynamic history of cosmopolitanism, cultural exchange and transregional connections. Unlike the medieval Middle East, where colleges were ubiquitous, particularly from the 11th century onwards, the institution was a rather late arrival in medieval Islamic Spain and North Africa. It was the mosque, the home and the chancery that functioned as the most important spaces of learning prior to the 14th century. The first madrasas (colleges) in the Islamic West only began to be constructed by the Marinids during the late 13th century.[5] The Marinid dynasty in North Africa was particularly distinguished by a dedication to the construction of colleges during the late 13th and 14th centuries. The emergence of the college in late medieval Islamic West reflected the increased collaboration and intersection between learned elites, urban notables and ruling elites. From the inception of the Nasrid kingdom of Granada, royal and noble elites worked closely with the urban scholarly and administrative classes whom they relied upon to govern and rule. These elites patronized various intellectual disciplines and genres of writing, ranging from philosophy and medicine to historiography, jurisprudence, and literature. The second Nasrid ruler, Muḥammad II (r. 1273–1302), was even known as “the learned” (al-faqīh)[6] for his patronage, promotion and participation in the Islamic legal, theological and intellectual sciences. It was within a broader cultural milieu in which learning and knowledge served not only a practical purpose in royal courts, but came to constitute a central component of political legitimation, that the Nasrid College, one of the most important institutions in Nasrid history was constructed. In Muḥarram 750/April 1349, the Nasrid College, located directly across from the former Great Mosque of Granada (today the cathedral) and near the main market, was completed.[7]
Oratory of the Nasrid College, Granada. Source: Wikipedia Commons.Ceiling of the Oratory of the Nasrid College. Photo by the Mohamad Ballan.
Return next week to continue reading about the Nasrid College and how it fostered knowledge and power in medieval Granada!
Mattei, Luca. “Estudio de la Madraza de Granada a partir del registro arqueológico y de las metodologías utilizadas en la intervención de 2006.” Arqueología y Territorio 5 (2008): 181-192
Prado García, Celia. “Los estudios superiores en las madrazas de Murcia y Granada. Un estado de la cuestión.” Murgetana 139 (2018): 9-21.
Rodríguez-Mediano, Fernando. “The Post-Almohad Dynasties in al-Andalus and the Maghrib.” In The New Cambridge History of Islam, Volume II: The Western Islamic World, Eleventh to Eighteenth Centuries, edited by Maribel Fierro, pp. 106–143. Cambridge: Cambridge University Press, 2012.
Rubiera Mata, María Jesús. “Datos sobre una ‘Madrasa’ en Málaga anterior a la Naṣrí de Granada.” Al-Andalus 35 (1970): 223–226
Sarr, Bilal and Luca Mattei. “La Madraza Yusufiyya en época andalusí: un diálogo entre las fuentes árabes escritas y arqueológicas.” Arqueología y Territorio Medieval 16 (2009): 53–74.
Secall, M. Isabel Calero. “Rulers and Qādīs: Their Relationship during the Naṣrid Kingdom.” Islamic Law and Society 7 (2000): 235–255
Seco de Lucena Paredes, Luis. “El Ḥāŷib Riḍwān, la madraza de Granada y las murallas del Albayzín.” Al-Andalus 21 (1956): 285–296.
[3] For an important recent contribution, which reflects the most up-to-date scholarship on Nasrid Granada, see Adela Fábregas, ed., The Nasrid Kingdom of Granada between East and West (Leiden, 2021). A significant historiographical overview and the current state of the field can be found in Antonio Peláez Rovira, “Balance historiográfico del emirato nazarí de Granada (siglos XIII-XV) desde los estudios sobre al-Andalus: instituciones, sociedad y economía,” Reti Medievali Rivista 9 (2008), 1–48.
[4] Olivia Remie Constable, Housing the Stranger in the Mediterranean World: Lodging, Trade, and Travel in Late Antiquity and the Middle Ages (Cambridge, 2003), 248-249, 297-298, 302-303; Roser Salicrú i Lluch, “The Catalano-Aragonese Commercial Presence in the Sultanate of Granada during the Reign of Alfonso the Magnanimous,” Journal of Medieval History 27 (2001), 289-312.
[5] For an excellent recent study of this development see Riyaz Mansur Latif, Ornate Visions of Knowledge and Power: Formation of Marinid Madrasas in Maghrib al-Aqsā (University of Minnesota PhD Book, 2011). Also, see Muhammad Abu Rihab, al-Madāris al-Maghribīya fī al-ʻaṣr al-Marīnī : dirāsa āthārīya miʻmārīya (Alexandria: Dār al-Wafāʼ li-Dunyā al-Ṭibāʻa wa-al-Nashr, 2011).
[6] This was an epithet he shared with his exact contemporary, Alfonso X of Castile-León (r. 1252-1282), known as “the Learned” (El Sabio).
[7] The most important scholarship about the Nasrid College includes La Madraza: pasado, presente y futuro (Granada: Editorial Universidad de Granada, 2007), eds. Rafael López Guzmán and María Elena Díez Jorge; La Madraza de Yusuf I y la ciudad de Granada: análisis a partir de la arqueología (Granada: Editorial Universidad de Granada, 2015), eds. Antonio Malpica Cuello and Luca Mattei.